숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
Virtual Memory의 등장 과정
Single Programming
초기 (1950~1970)의 운영체제는 물리 memory에 하나의 program만을 올리는 Single Programming 형태였다. 즉, memory는 OS 영역, 실행 중인 1개의 program이 올라가는 영역으로 구분됐다. memory 가상화에 대한 개념도 존재하지 않았다. 동시에 memory를 점유할 수 있는 program의 개수가 최대 1개였기 때문에 multi-tasking도 불가능했다. Single Programming을 채택한 대표적인 OS로는 MS-DOS가 있다.

Multi Programming
이후 Multi Programming이 등장했다. 동시에 여러 process를 실행(되는 것 처럼 보이게)할 수 있다. OS는 하나의 process를 매우 짧은 시간동안 실행하고, 이후 다른 process로 전환(context switch)한다. 이러한 과정을 계속 반복하게 된다. 이를 Time Sharing(시분할)이라고 한다. 이 때 기존에 실행되던 process의 상태를 disk에 저장하게 되는데, disk에 저장한다는 것은 결국 I/O가 발생한다는 것이므로, 실행 속도가 느릴 수 밖에 없었다. 또한 다른 process의 memory 공간에 침범을 할 위험성도 존재했다. 즉, process 간 isolation이 제대로 보장되기 힘들었다.
Virtual Memory
이러한 문제를 해결하기 위해 memory 가상화 개념이 도입되었다. 각 process마다 가상의 memory 주소 체계를 도입해 실제 물리 memory의 공간과 mapping을 시키는 것이다. 이 과정에서 page table, MMU가 등장하게 된다. page table은 가상 memory의 공간을 page 단위로 나눠 물리 memory의 주소와 mapping시키는 table이다. 이 과정을 Memory Management Unit (MMU)가 수행하게 되는데, MMU는 과거에는 OS에 구현이 되어있었으나, 현대의 대부분의 CPU는 HW로 MMU를 탑재하고 있다. 가상 memory 공간은 각 process마다 별개로 보유하고 있다. page table 역시 마찬가지이다. 따라서 서로 다른 process들의 가상 memory 상에서의 주소가 같다고 하더라도 실제 물리 memory에서의 주소는 다른 page를 가리키게 된다. 이러한 방식으로 process간 isolation을 보장하게 된다.
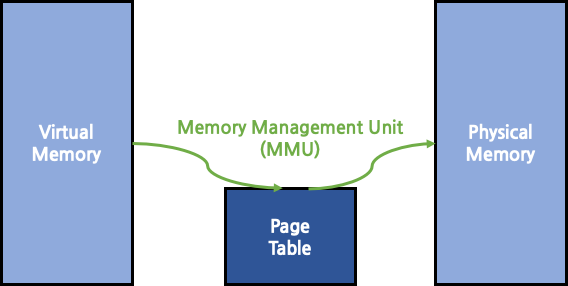
Memory Management
Memory Management의 목적
Memory Management는 아래의 3가지 목적을 갖는다.
-
투명성 (Transparency)
구체적인 방법을 모르는 상태에서도 원활하게 사용할 수 있도록 하는 것이다. 가상화가 대표적인 예시이다. 실행되는 process 입장에서는 자신의 memory 체계가 가상 memory인지조차도 깨닫지 못하게 한다. 이는 가상화의 정의(속임)에도 부합한다.
-
효율성 (Efficiency)
시간 복잡도와 공간 복잡도를 낮추는 것이다. 특히 공간 복잡도를 중요시 여기는데, 만약 page table의 크기가 너무 클 경우 memory를 많이 사용하게 되므로 공간 복잡도에서 효율적이지 못하다고 할 수 있을 것이다.
-
보호 (Protection)
2가지 관점에서 Protection이 있는데, process 간 isolation을 보장하는 것과 OS kernel의 isolation을 보장하는 것이다. 둘 모두 가상 memory를 통해 달성할 수 있다.
Memory Management의 Issue
Memory Management에는 아래와 같은 주요 Issue가 있다.
-
배치 (Placement)
memory의 여러 빈 공간 중 어느 곳에 새로운 process를 삽입할 것인가에 대한 issue이다.
-
재배치 (Replacement)
memory에 올라가 있던 process가 종료되어 빈 공간이 생길 때, 이러한 빈 공간을 어떻게 최소화할 지에 대한 issue이다.
-
보호 (Protection)
memory 상의 여러 process 및 OS가 어떻게 서로의 공간을 침범하지 않을지에 대한 issue이다.
-
반입 (loading)
요청을 하는 시점에 반입을 할 지(on-demand loading), 요청이 올 시점을 예측해 반입을 할 지에 대한 issue이다.
Memory Management의 종류
단일 사용자 전용 시스템 (Single User System)

memory를 동시에 점유할 수 있는 process의 수가 최대 1개이기 때문에 배치, 재배치를 고려할 필요가 없다. 만약 주어진 memory보다 더 큰 process가 들어오게 될 경우, overlay 기법을 사용하게 된다.
고정 분할 다중 프로그래밍 시스템 (Fixed Partition Multi Programming System)
-
절대 번역 어셈블러 (Absolute Aseembler)
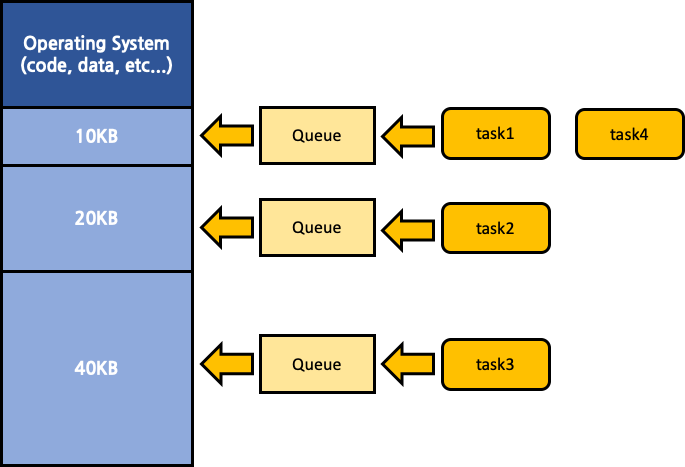
memory를 초기에 고정된 크기로 분할시킨 뒤에, 각각의 segment마다 독립적인 queue를 운용하는 것이다. 각 process는 compile time에 결정된 segment에 할당이 되기 때문에, 자신이 배정된 segment는 다른 process가 점유하고 있고, 다른 segment가 비어있는 상황에서도 자신의 segment가 비워질 때 까지 대기해야만 한다. 구현이 간단하다는 장점이 있지만 memory의 낭비가 심하다는 단점이 있다.
-
재배치 가능 어셈블러 (Relocating Assembler)
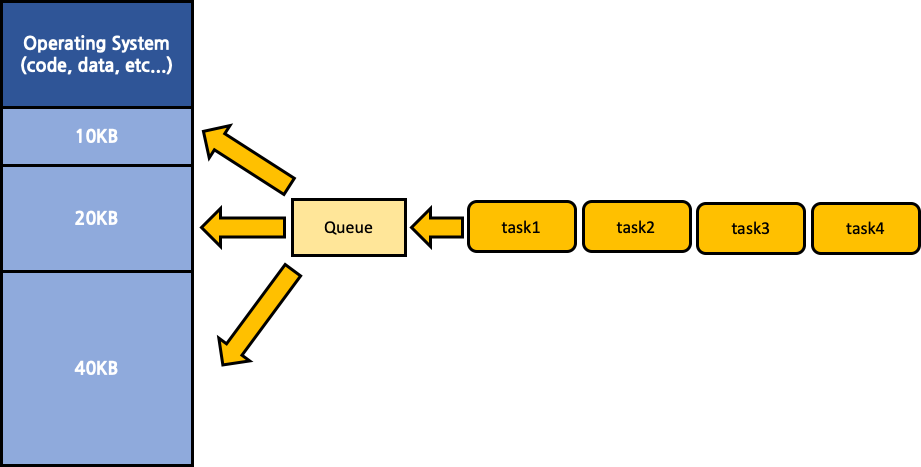
memory를 초기에 고정된 크기로 분할시키는 것은 동일하지만, 하나의 공통된 queue를 운용해 각각의 segment에 분배하는 것이다. 이를 통해 재배치가 가능해진다. 즉, compile time의 정적인 결정에 의존하지 않고 memory 내 segment들의 상태에 따라 동적으로 배치되는 것이다. 절대 번역 어셈블러에 비해 효율적이나 구현이 어렵다는 단점이 있다.
위의 2가지 배치 방법은 모두 다 고정적으로 memory를 분할하기 때문에 내부 단편화(internal fragmentation)현상이 발생할 수 밖에 없다 내부 단편화(internal fragmentation)란, segment의 크기보다 더 작은 process가 들어오게 될 경우 해당 segment 내부에 빈 공간이 생기게 되는 현상이다. 각 segment마다 빈 공간이 발생하게 되고, 해당 공간들은 사용되지 못한다. 이는 결국 memory의 낭비가 심해짐을 뜻한다. 또한 동시에 memory에 올릴 수 있는 process(활성 process)의 개수가 정적으로 제한된다는 큰 단점 역시 존재한다.
가변 분할 다중 프로그래밍 시스템 (Variable Partition Multi Programming System)
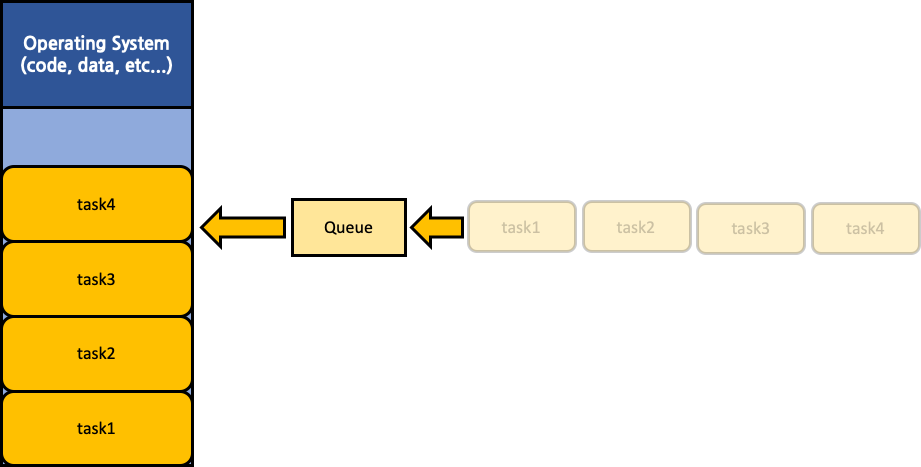
내부 단편화 문제를 해결하기 위해 가변 분할 다중 프로그래밍 시스템이 등장했다. 공통된 하나의 queue를 운용하는 방식은 동일하지만, memory를 초기에 segment로 분할시키지 않고 통합해 관리하는 것이다. 이는 내부 단편화 현상은 해결하지만, 외부 단편화(external fragmentation)현상이 발생하게 된다. 외부 단편화(external fragmentation)란, 하나의 process가 종료됐을 경우 해당 process가 차지하고 있던 공간에 새로운 process가 들어오지 못하고 계속 빈 상태로 유지되는 현상을 뜻한다. 만약 종료된 process가 10KB인데 queue에서 대기하고 있는 process들이 모두 다 10KB 이상일 경우에는 해당 공간은 계속 낭비되게 될 것이다. 이러한 현상을 해결하기 위해서는 compaction 또는 coalescing을 수행해야 한다. compaction은 memory 전체에서 외부 단편화 현상을 제거하는 것이고, coalescing은 특정 두 process 사이의 외부 단편화 현상을 제거하는 것이다.
재배치 기법
위와 같이 여러 fragmentation이 발생했을 경우 여러 fragmentation 중 하나를 선택해 새로운 process를 삽입해야 한다. 물론 해당 framentation이 process의 크기보다 작을 경우 삽입이 불가능하겠지만, 가능한 후보 fragmentation이 여러 개라면 그 중 하나를 선택해야만 할 것이다. 이렇듯 재배치 상황에서 fragmentation을 선택하는 전략에는 아래의 4가지가 있다.
-
First Fit
memory의 처음부터 탐색해 알맞는 첫번째 후보를 선택하는 전략이다.
-
Best Fit
memory의 처음부터 탐색해 가장 크기가 작은 후보(크기의 차이가 적은 후보)를 선택하는 전략이다.
-
Worst Fit
memory의 처음부터 탐색해 가장 크기가 큰 후보를 선택하는 전략이다.
-
Next Fit
memory의 처음부터가 아닌 직후부터 탐색해 알맞는 첫번째 후보를 선택하는 전략이다.
Buddy Algorithm
가변 분할 다중 프로그래밍 시스템은 외부 단편화 현상을 해결하기 위해 compaction, coalescing과 같은 작업을 지속적으로 수행해야 하는 단점이 존재한다. 이를 해결하기 위해 외부 단편화 발생을 최소화하는 Buddy Algorithm이 있다. 가변 분할 다중 프로그래밍 시스템의 일종인데, 기존의 시스템과의 차이점은 release가 발생해 free block이 생성될 때 마다 근처의 여유 block과 merge를 수행한다는 것이다. 이를 통해 큰 크기의 block을 운용하고, 새로운 process가 들어올 때 해당 process의 크기에 가장 적합한 크기가 될 때까지 이분할을 수행해 내부 파편화 크기를 최소화한다. 동시에 free block을 큰 size로 묶어 운용하기 때문에 외부 파편화 발생 빈도도 현저히 줄어들게 된다. Buddy Algorithm은 주로 Red-Black Tree를 이용해 구현한다.
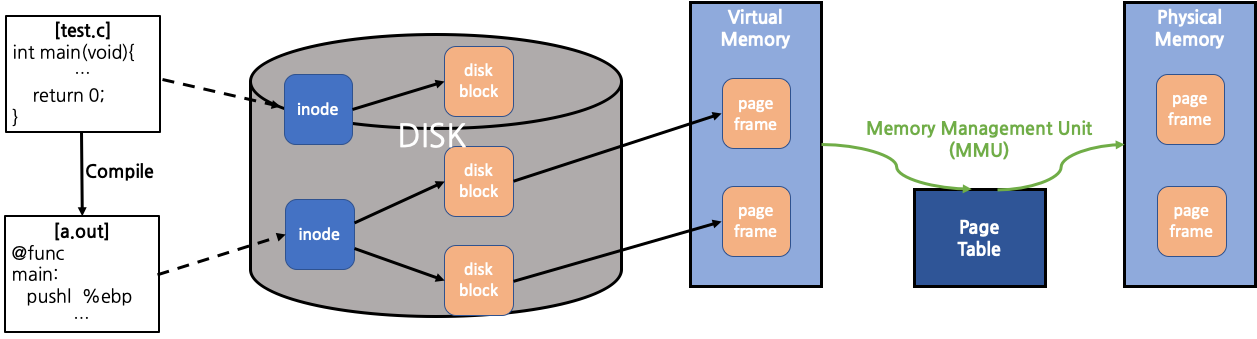
Process 실행 과정
disk에는 실행 파일이 저장되어 있다. disk에 있는 파일이 memory에 올라가 process가 된다. disk 상에서 실행 파일(.out, .exe 등)이 저장되는 format은 ELF (windows의 경우 PG) format이다. process가 memory에 올라갈 때와는 구조가 다른데, 아래와 같은 차이를 지닌다.

Process 구조

ELF format 구조
disk에 저장되는 파일은 stack/heap을 가질 필요가 없다. stack/heap은 process가 실행될 때 활용하는 공간이기 때문이다. disk에 저장되는 파일은 disk block 단위로 나눠 저장이 되는데, 대개 그 크기는 4KB이다. 한편, memory에서도 page frame 단위로 나누어 보관을 하는데, 그 크기는 disk block의 것을 따른다. 따라서 disk와 memory에서의 process 실행 시의 구조는 아래와 같은 흐름을 따르게 된다.
단순 프로그램 실행이 아닌 좀 더 복잡한 경우를 살펴보자. fork()를 호출한 경우이다.
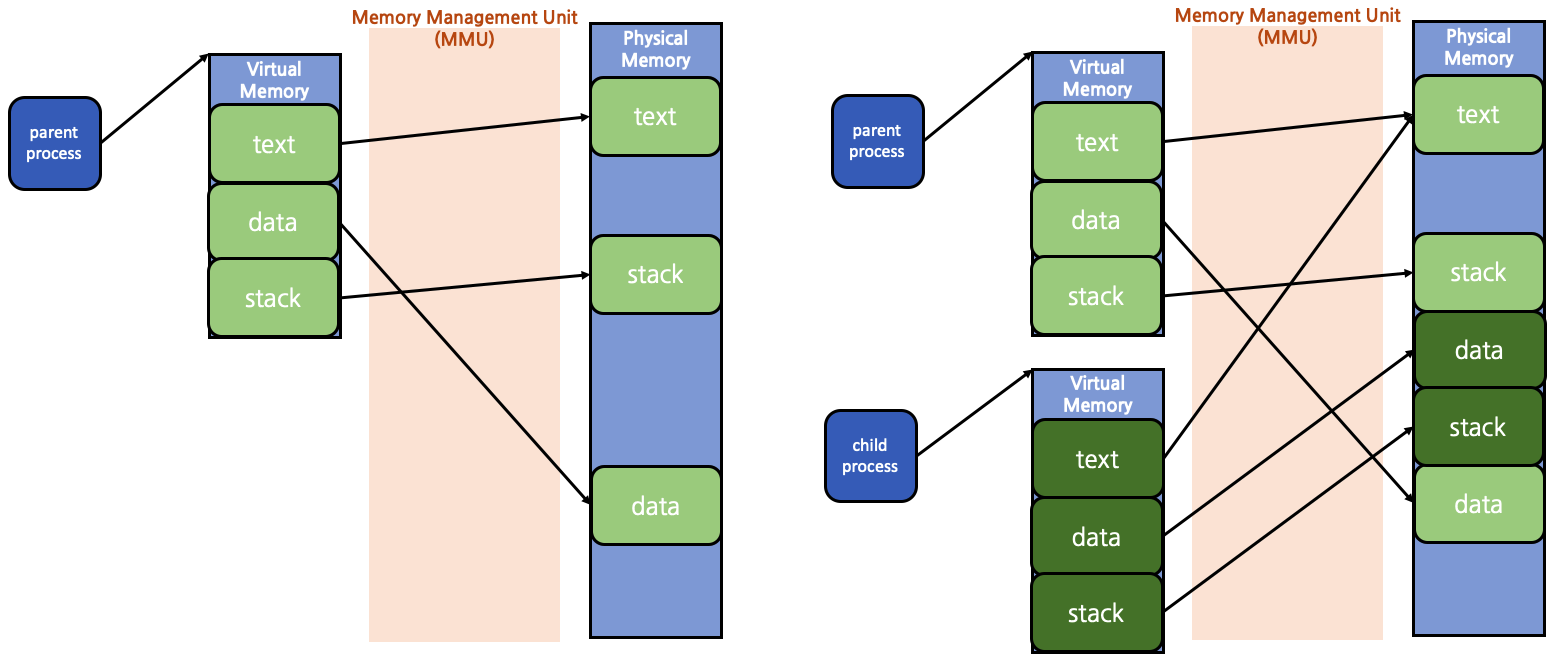
좌측은 fork() 호출 전, 우측은 fork() 호출 후이다. fork()는 부모 process와 자식 process가 동일한 code를 사용하기 때문에 text 영역은 서로 공유하게 된다(같은 물리 memory를 가리킨다). 반면 data와 stack 영역에 대해서는 물리 memory에 새로운 page frame을 생성해 자식 process에게 할당하게 된다. 이러한 방식은 여러 자식 process가 생성될 경우 memory 낭비가 심하다는 단점이 존재한다. 자식 process라고 하더라도 내부에서 지역 변수 및 전역 변수 등을 수정하지 않는 경우라면 굳이 새로운 page frame을 생성하지 않아도 되기 때문이다. 이러한 단점을 해결하기 위해 현대 OS는 대부분 COW (Copy On Write) 방식을 채택하고 있다.
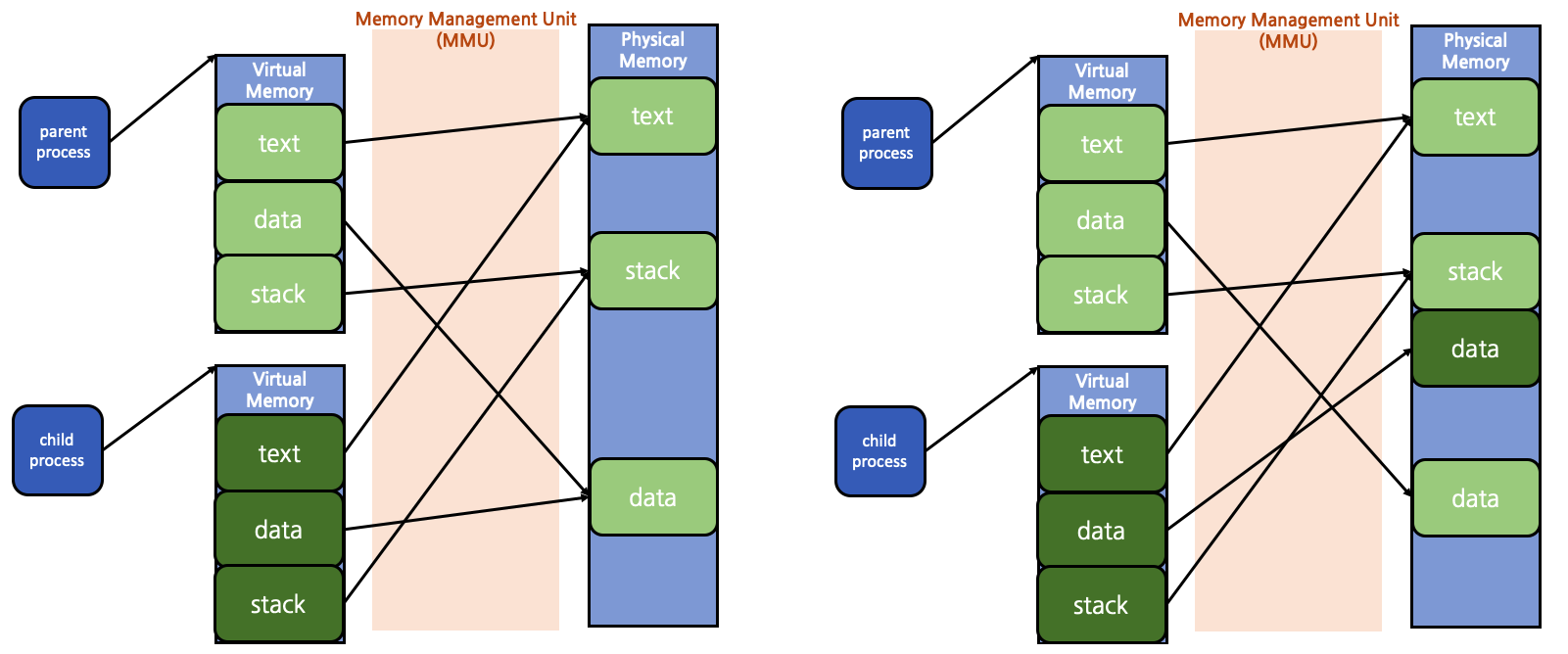
좌측은 COW 방식에서의 fork() 호출 직후이고, 우측은 fork() 호출 후 전역 변수에 대한 변경이 일어난 뒤이다. COW 방식에서는 fork()를 한다고 해서 바로 data 및 stack 영역에 대한 새로운 page frame을 생성하지 않고 우선 부모 process의 것을 공유한다. 이후 자식 process에서 값 변경이 발생한 시점에 새로운 page frame을 생성해 자식 process에게 할당하게 된다.
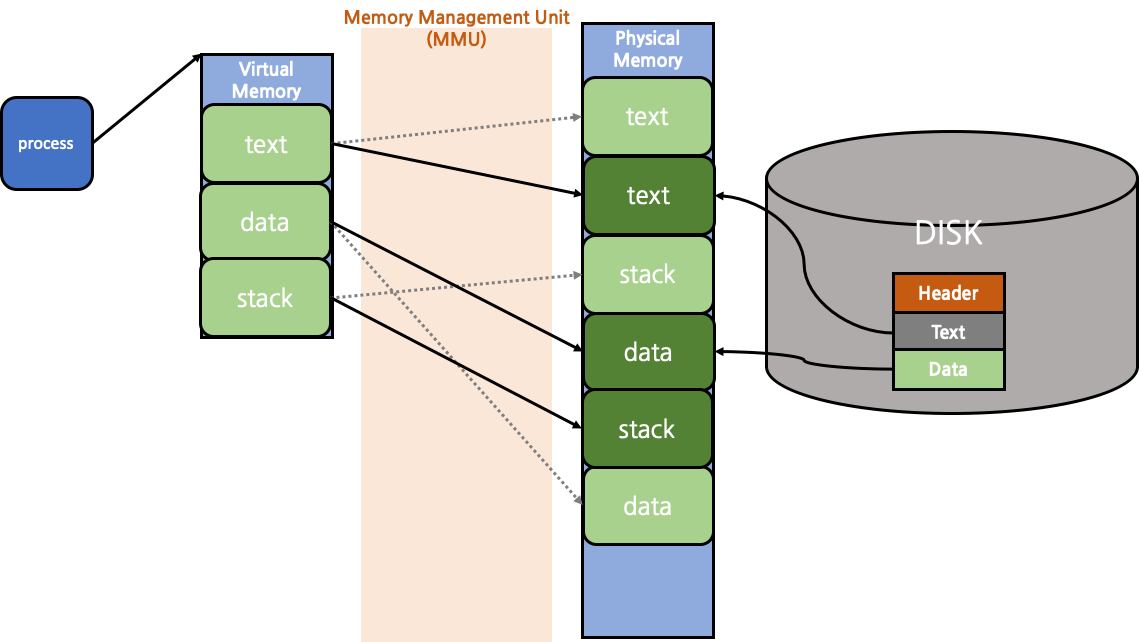
exec()의 경우에는 fork()와는 다르게 동작하는데, exec()는 실행중이던 process의 모든 memory 영역을 교체하게 된다. 기존에 사용하던 page frame과의 연결을 끊고, exec() 호출 시 넘겨준 새로운 실행 파일을 disk에서 읽어들여 새로운 text page frame, data page frame, stack page frame을 생성해 연결한다.