숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
Thread
Process
OS에서 process의 역할을 정리해보자. 우선 process는 자원 소유의 단위이다. 자원이라는 것은 main memory, I/O device, file system 등을 의미한다. 대표적인 예시로 process별로 main memory에 서로 다른 공간을 할당하는 것이 있다. 두번째로 process는 scheduling의 단위이다. context switching은 process 사이에 발생하면서 다음 실행될 process를 선택한다. 이러한 process의 2가지 역할은 서로 독립적이다. 따라서 os는 두 가지 역할을 모두 process라는 하나의 개념으로 수행하지 않고, 별개의 단위를 만들어냈다. 우선 자원 관리 역할은 process가 그대로 수행한다. 이 때의 process를 task라고 명명하기도 한다. 반면 scheduling의 단위는 thread 또는 경량(lightweight) process라고 새로 정의한다.
Multi-thread
os가 하나의 process 내에 여러 thread를 지원하는 것을 다중 쓰레딩(kernel-level multi thread)라고 한다. MS-DOS와 같은 단일 사용자 process의 경우에는 오직 하나의 process만 동시에 실행될 수 있으며, 해당 process 내에 하나의 thread만이 존재한다. 즉, thread라는 개념이 없는 것과 마찬가지이다. 초기의 UNIX와 같은 다중 사용자 process는 여러 process가 동시에 실행될 수 있지만, 각 process 내에 하나의 thread만이 존재한다. Windows, Mac OS, BSD와 같은 비교적 최신 운영체제는 모두 multi thread를 채택하고 있다. 여러 process가 동시에 실행될 수 있으면서, 각 process 내에 여러 thread가 함께 존재하는 것이다.
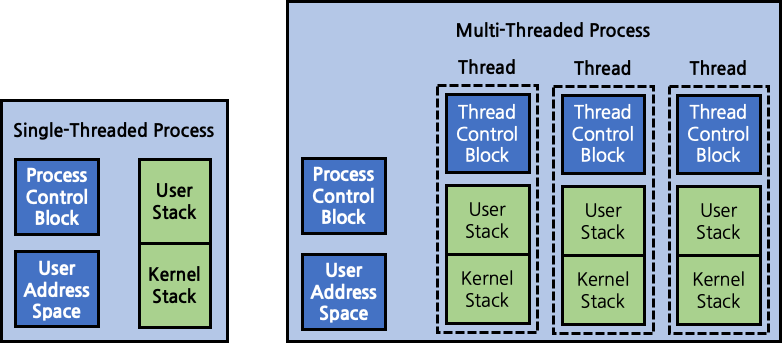
다증 쓰레딩 환경에서 process는 자원 할당의 단위, 보호의 단위로써의 의미를 갖는다. process 별로 자원을 할당하고, 다른 process가 자신의 자원에 접근하지 못하도록 보호하는 것이다. 한편 dispatching(scheduling)의 단위는 process가 아닌 thread가 수행하게 된다. 각 thread는 context switching 수행을 위해 별개의 독립된 program counter를 보유한다. 또한 별개의 독립된 stack을 각자 보유한다. 반면 heap, data, bss, text와 같은 memory 영역은 process 내의 다른 thread들과 공유한다. 즉, process에게 할당된 stack memory 영역을 여러 thread들이 나누어 사용하고, 나머지 memory 영역은 process 단위로 공유하는 것이다. 따라서 기본적으로 memory 등의 모든 자원은 process 내의 모든 thread들이 공유한다고 볼 수 있다.
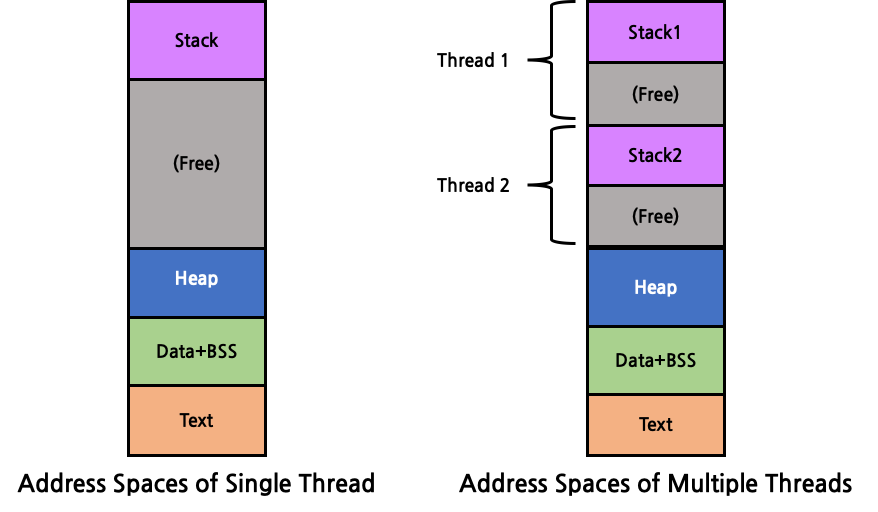
그렇다면 multi-thread를 사용함으로써 얻는 이점은 어떤 것이 있을까? 우선 성능 향상에 큰 도움이 된다. process를 여러 thread 별로 할당해 I/O를 많이 하는 thread, CPU 연산을 많이 하는 thread를 분리한다면 I/O 때문에 대기하는 시간을 단일 process 방식보다 훨씬 줄일 수 있을 것이다. 또한 process를 생성하는 것에 비해 이미 존재하는 process 내에서 새로운 thread를 생성하는데 드는 비용이 더 적다는 장점도 있다. 이에 더해 context switching도 thread 간의 전환이 process 단위보다 더 빠르다. 마지막으로, process 간에는 자원을 공유할 수 없기 때문에 서로 통신하기 위해서는 kernel이 개입해야 하지만, thread는 kernel 호출 없이도 서로 원활하게 통신할 수 있다.
Process/Thread
process와 thread의 유사점/차이점을 정리해보자. 우선 context switching의 단위라는 점이 공통적이다. 또한 program counter를 보유한다는 점도 공통적이다. 반면 process는 PCB(process control block)으로 관리하지만, thread는 TCB(thread control block)으로 관리한다는 점이 차이가 있다. 또한 process는 다른 process의 자원(memory 공간 등)에 접근할 수 없는 반면, thread는 다른 thread의 자원에 접근 가능하다는 차이점이 있다. 마지막으로, process 단위의 context switching 후에는 memory 주소 공간이 달라지지만, thread 단위의 context switching 후에는 memory 주소 공간의 변화가 없다는 차이점이 있다.
States of Threads
thread의 상태는 process의 상태와는 별개이다. process의 상태를 떠올려보면, suspend 상태가 존재했다. thread 상태에서는 suspend가 존재하지 않는다. suspend라는 것은 main memory가 아닌 disk의 swap 영역에 위치하는 상태인데, 이는 process 전체가 swap 영역으로 옮겨지는 것이기에 thread 단위의 작업이 아니다. 즉, process가 swap-out된다면 해당 process에 속한 모든 thread가 함께 swap-out되는 것이다. 즉, suspend는 thread의 state와는 아무런 연관이 없다. thread의 상태는 크게 다음의 4가지가 있다.
- 생성(spawn)
-
블록(block)
thread가 어떠한 사건을 기다리는 상태이다. 자신의 register, program counter, stack pointer를 저장한다. dispatcher는 같은 process나 다른 process 내의 다른 thread를 수행한다.
-
비블록(unblock)
사건이 발생해 thread가 준비 queue에 push되는 상태이다.
- 종료(finish)
ULT(User-level Thread) / KLT(Kernel-level Thread)
사용자는 kernel-level thread를 직접 제어하지 못한다. KLT는 오직 kernel만이 제어할 수 있는 thread이다. single-thread 운영체제일 경우에는 KLT가 구현되어 있지 않다. 사용자는 현재 환경이 KLT가 구현되어 있는지도 알지 못하고, KLT를 제어할 수도 없기 때문에 user-level thread를 사용하게 되는데, 대개 pthread와 같은 thread library를 활용한다. thread library는 실행 운영체제가 single-thread일 경우 여러 ULT를 하나의 process로 보내게 된다. 만약 KLT가 구현되어 있는 multi-thread 운영체제라면 알맞게 KLT와 mapping을 시켜 여러 process로 보내게 된다.
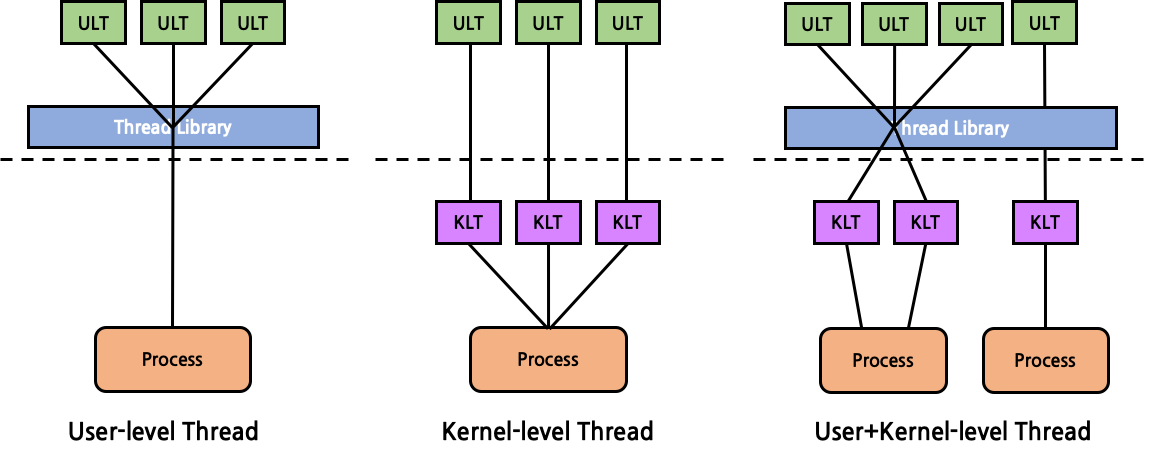
ULT와 KLT를 비교해보자. 한 process 내의 thread 사이 dispatch를 수행할 때를 생각해보자. 우선 ULT는 각 thread가 모두 사용자 주소 공간에 위치하기 때문에 dispatch를 할 때에 kernel mode로 변경될 필요 없이 user mode에서 모두 수행 가능하다. 반면 KLT는 dispatch를 할 때마다 kernel mode로 변경되어야만 한다. 즉, mode 전환 여부에 있어서는 ULT가 KLT보다 유리하다. 또한, ULT는 운영 체제에 종속적이지 않고 어떠한 kernel의 변경 없이도 원활히 수행될 수 있는 반면, KLT는 운영 체제에 따라 존재하지 않을 수도 있다는 차이점도 있다. 한편, ULT의 경우에는 하나의 thread에서 system call을 호출할 경우 같은 process 내의 모든 thread들이 함께 block이 된다는 치명적인 단점이 있다. 즉, 순수한 ULT만으로는 다중 처리의 장점을 살리지 못하게 된다. 반면 KLT의 경우에는 한 thread가 block된다고 하더라도 다른 thread들은 자유롭다. 즉, 여러 dispatcher에 하나의 process에 속한 여러 thread를 동시에 scheduling이 가능하다. 진정한 의미의 다중 처리가 가능한 것이다.
Lock
thread는 서로 memory를 공유한다. 따라서 공통으로 사용하는 공유 변수가 있다. 여러 thread가 모두 변수의 값을 read만 하는 경우에는 문제가 발생하지 않지만, 만약 특정 thread가 변수의 값을 write하게 된다면 동기화 문제가 발생한다. 이를 해결하기 위해서는 한 thread가 변수를 write할 때에는 다른 thread가 해당 변수에 접근할 수 없도록 lock을 걸어주는 과정이 필요하다. lock~unlock의 구간을 critical section(임계 영역)이라고 한다. critical section은 해당 영역 내의 다수의 명령어를 atomic(원자적)하게 실행되도록 보장한다. lock에 대한 정책은 모든 thread에게 공정해야만 한다. 구체적으로, 우선 모든 thread가 적절한 시간 내에 critical section에 들어갈 수 있어야만 하고, critical section에 들어가기 위해 대기 중인 모든 thread들의 요청은 언젠가는 허가가 되어야 한다. 마지막으로 starvation이 발생하지 않아야 한다. lock은 적용 범위에 따라 사용하는 일부분만 lock을 하는 coarse-grained lock, 사용하는 모든 영역을 lock하는 fine-grained lock으로 구분되기도 한다.
lock에서 사용되는 용어들을 정리해보자.
-
mutual exclusion (상호 배제)
critical section에는 어느 시점에서든 반드시 단 1개의 thread만 접근 가능해야 한다는 개념이다.
-
race condition (경쟁 조건)
다수의 thread가 공유 data를 read/write하는 상황이다.
-
busy waiting
모든 thread가 critical section 접근 조건을 만족하지 못해, 반복적으로 접근 조건만을 검사하며 함께 대기하는 상황이다.
-
deadlock (교착 상태)
다수의 thread가 다른 thread가 어떠한 일을 해 줄 때까지 대기하는 상태로, 모든 thread가 다른 thread의 변화를 기다리며 대기하는 상황이다.
-
livelock
다수의 thread가 단순히 자신의 상태를 변화시키는 작업만 반복적으로 수행하면서 대기하는 상황이다.
mutual exclusion
mutual exclusion을 위한 세부 요구 조건이 있는데, 우선 mutual exclusion은 선택 사항이 아니라 필수 사항이라는 점이다. 즉, mutual exclusion은 강제되어야만 한다. 두번째로, critical section의 밖에 있는 어떤 thread도 critical section 내의 thread에게 간섭해서는 안된다. 세번째로, deadlock 및 starvation이 발생하지 않아야 한다. 네번째로, critical section에 아무도 접근하지 않을 때에는 대기하던 thread 중 하나가 즉시 critical section에 접근할 수 있어야 한다. 마지막으로, 어떠한 thread도 critical section을 무한히 점유할 수는 없다.
mutual exclusion을 구현하기 위한 여러 방법을 살펴보자. 단순화를 위해 binary mutual exclusion으로 가정한다. 즉, 2개의 process만이 존재하는 상황이다.
turn variable
int turn=0;
// thread 0
void thread0(void){
while(1){
while(turn);
/*
critical section...
*/
turn = 1;
}
}
// thread 1
void thread1(void){
while(1){
while(!turn);
/*
critical section...
*/
turn = 0;
}
}
turn이라는 boolean 변수를 활용해 turn==0일 때에는 thread0을, turn==1일 때에는 thread1을 실행한다.
하지만 이러한 정책은 한 thread가 연속적으로 critical section을 점유하지 못한다는 문제점이 있다. 구체적인 예시로, thread0이 critical section을 점유한 뒤 나오게 되면, thread1이 critical section을 점유하기 전까지는 절대 critical section을 점유할 수 없다. 만약 thread1이 critical section에 접근할 필요가 없는 thread라면 thread0은 무한히 대기하게 될 것이다. 즉, deadlock이 발생한 것이다.
flag
int flag[2] = {0, 0};
// thread 0
void thread0(void){
while(1){
while(flag[1]);
flag[0] = 1;
/*
critical section...
*/
flag[0] = 0;
}
}
// thread 1
void thread1(void){
while(1){
while(flag[0]);
flag[1] = 1;
/*
critical section...
*/
flag[1] = 0;
}
}
각 thread마다 하나의 boolean 변수를 사용해 자신이 critical section을 점유하고 있는지를 나타낸다. 따라서 turn variable 정책과는 달리 하나의 thread가 연속적으로 critical section을 점유할 수 있다. 상대방 thread가 critical section을 점유하고 있는지만 확인하기 때문이다. 이는 flag 변수의 개수를 늘리고 while문에서 확인할 flag 개수를 증가만 시킨다면 binary가 아닌 n개의 thread에 대해서도 적용 가능하도록 손쉽게 확장할 수 있다.
하지만 이러한 정책은 busy waiting을 발생시킨다는 문제점이 있다. 만약 다른 thread의 flag를 검사하는while문과 자신의 flag를 1로 변화시키는 명령어 사이에 context switching이 발생하게 된다면 두 flag가 모두 1이 되어 두 thread 모두 critical section에 접근하게 된다. 이는 critical section의 정의에 부합하지 않는 상황이다. 이는 실제 lock을 수행하는 명령과 lock 수행을 돕는 변수의 값 변경 사이에 context switching이 발생한 것으로 lock step 사이에 scheduling이 발생했다고 볼 수 있다.
busy waiting
int flag[2] = {0, 0};
// thread 0
void thread0(void){
while(1){
flag[0] = 1;
while(flag[1]);
/*
critical section...
*/
flag[0] = 0;
}
}
// thread 1
void thread1(void){
while(1){
flag[1] = 1;
while(flag[0]);
/*
critical section...
*/
flag[1] = 0;
}
}
lock step 사이에 context switching이 발생하는 것을 막기 위해서 flag를 먼저 변경시킨 뒤 대기한다. 그러나 이 경우에도 flag의 변경과 while문 사이에 context switching이 발생하게 되면 모든 flag가 1이 되게 된다. 이러한 경우 모든 thread가 flag를 확인하는 while문을 무한히 수행하게 된다. busy waiting이 발생한 것이다.
busy flag again
int flag[2] = {0, 0};
// thread 0
void thread0(void){
while(1){
while(flag[1]){
flag[0] = 0;
delay(10);
flag[0] = 1;
}
/*
critical section...
*/
flag[0] = 0;
}
}
// thread 1
void thread1(void){
while(1){
while(flag[0]){
flag[1] = 0;
delay(10);
flag[1] = 1;
}
/*
critical section...
*/
flag[1] = 0;
}
}
다른 thread의 flag를 검사하는 while문 내에서 자신의 flag를 일정 시간 간격으로 toggle하는 것이다. 이러한 경우 delay 시각 내에 context switching이 발생하게 되면 다른 thread가 critical section에 접근할 수 있게 된다. 하지만 이 역시 두 thread의 delay가 동시에 발생하는 최악의 경우에는 livelock 상태에 빠지게 된다. 하지만 이는 현실에서는 발생하기 불가능에 가깝기 때문에 무시되고는 한다. SW 상으로 critical section 정책을 구현하는 것에 있어서는 위의 정책이 가장 최선이다.
interrupt disable
// thread 0
void thread0(void){
while(1){
interrupt_disable();
/*
critical section...
*/
interrupt_enable();
}
}
// thread 1
void thread1(void){
while(1){
interrupt_disable();
/*
critical section...
*/
interrupt_enable();
}
}
HW적으로 critical section 접근 이전에 interrupt를 disable한 뒤, critical section 이후에 interrupt를 enable함으로써 context switching이 발생하지 않도록 만드는 것이다. 그러나 real time OS에서 context switching을 금지한다는 것은 있을 수 없는 일이기에 현실성이 없다.
atomic instruction
int flag[2] = {0, 0};
void thread0_atomic_instruction(void)
{
while(flag[1]);
flag[0] = 1;
}
void thread1_atomic_instruction(void)
{
while(flag[0]);
flag[1] = 1;
}
// thread 0
void thread0(void){
while(1){
thread0_atomic_instruction();
/*
critical section...
*/
flag[0] = 0;
}
}
// thread 1
void thread1(void){
while(1){
thread1_atomic_instruction();
/*
critical section...
*/
flag[1] = 0;
}
}
기존의 flag 정책에서 문제가 발생하는 상황은 다른 thread의 flag를 검사하는 while문과 자신 flag의 값을 변경하는 명령어 사이에 context switching이 발생하는 경우였다. 이를 막기 위해 HW 상에서 두 명령어를 묶어 atomic하게 실행되도록 하는 것이다. 이를 위해서 HW는 testset과 exchange라는 명령어를 제공하게 된다.
Deadlock
deadlock은 어느 경우에 발생하는지, 어떻게 해결할 수 있는지에 대해 알아보자.
deadlock은 아래의 4가지 조건이 모두 충족되었을 때 발생한다.
-
mutual exclusion (상호 배제)
critical section을 동시에 최대 1개의 thread만 점유할 수 있는 것이다.
-
Hold-and-wait (점유 대기)
critical section을 점유할 수 없을 경우 critical section이 비워질 때까지 대기한다.
-
Non preemption (비선점)
한 번 점유한 경우 다른 thread에 의해 강제로 점유를 뺏기지 않는다.
-
Circular wait (환형 대기)
자원 할당 그래프 (Resource Allocation Graph)에서 cycle이 생성된 경우이다. 즉, 서로 다른 thread의 행동을 기다리면서 무한히 대기하는 상황이다.
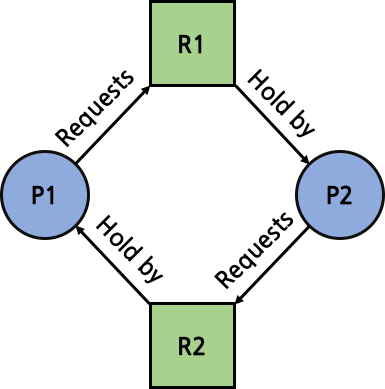
1~3의 조건은 deadlock의 필요 조건이다. 즉, 조건 중 어느 하나라도 충족하지 않으면 deadlock은 발생하지 않는다. 하지만 1~3의 조건이 모두 충족되었다고 해서 무조건 deadlock이 발생하는 것은 아니다. 1~4의 조건이 모두 만족해야만 deadlock이 발생한다. 즉 1~4의 조건은 deadlock의 필요충분 조건이다.
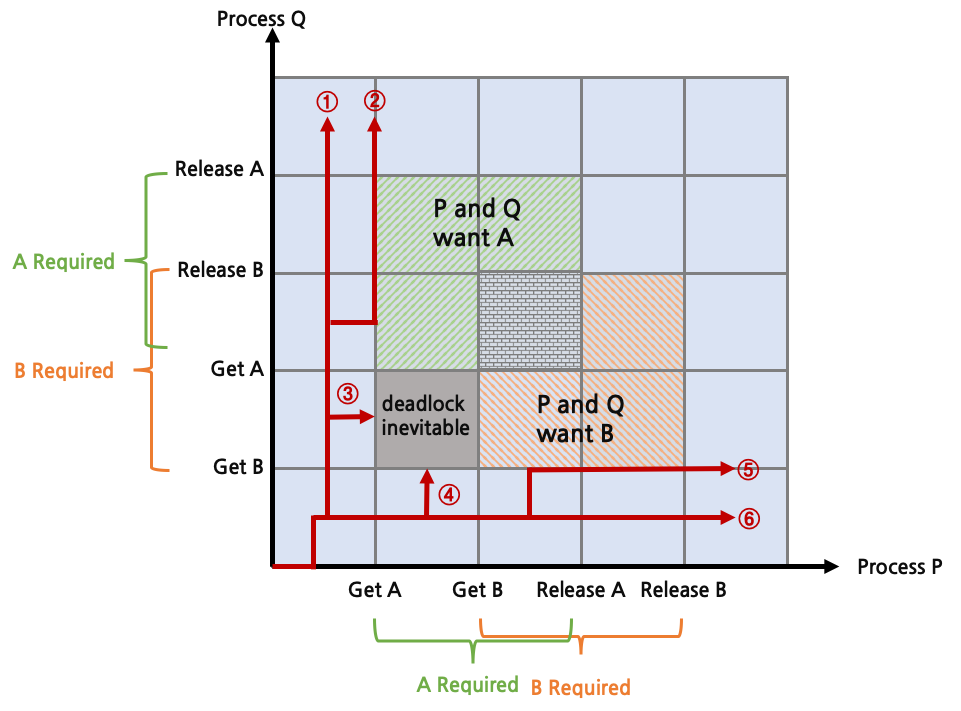
위는 Process P와 Q가 자원 A와 B를 경쟁적으로 사용하는 상황에서의 deadlock 발생 가능성을 나타낸 것이다. 총 6개의 시나리오에 대해서 살펴보자.
- Q가 B를 획득하고, A를 획득한다. Q는 모든 작업을 수행하고 B와 A를 순서대로 release한다. 이후에 P로 전환되어 자유롭게 실행된다.
- Q가 B를 획득하고, A를 획득한다. P로 전환되지만 A를 획득할 수 없어 block된다. Q가 마저 실행되고 B와 A를 release한 뒤에 P가 실행된다.
- Q가 B를 획득한 뒤 P로 전환되어 P가 A를 획득한다. 이후에 Q로 전환될 경우 Q가 A를 획득할 수 없어 block되고, P가 계속 실행될 경우 B를 획득할 수 없어 block된다. deadlock이다.
- P가 A를 획득한 뒤 Q로 전환되어 Q가 B를 획득한다. 이후에 P로 전환될 경우 P가 B를 획득할 수 없어 block되고, Q가 계속 실행될 경우 A를 획득할 수 없어 block된다. deadlock이다.
- P가 A를 획득하고, B를 획득한다. Q로 전환되지만 B를 획득할 수 없어 block된다. P가 마저 실행되고 A와 B를 release한 뒤에 Q가 실행된다.
- P가 A를 획득하고, B를 획득한다. P는 모든 작업을 수행하고 A와 B를 순서대로 release한다. 이후에 Q로 전환되어 자유롭게 실행된다.
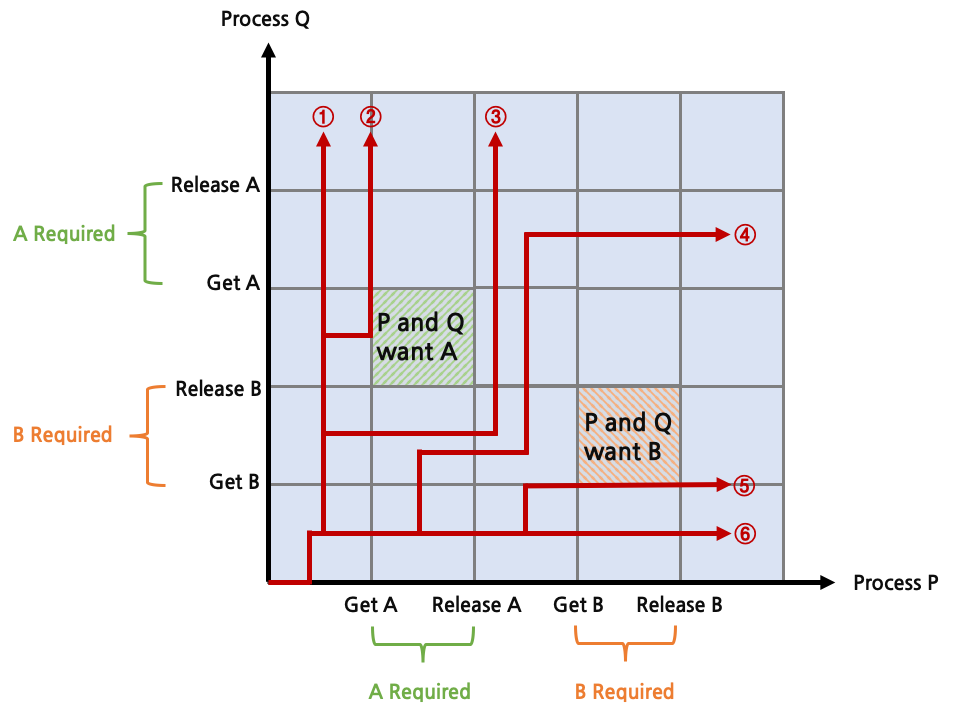
위와 같이 한 process가 두 자원은 동시에 점유하지 않을 경우에는 deadlock이 발생하지 않게 된다. 위의 deadlock 발생 상황과의 차이점은 한 process가 동시에 두 자원을 점유하지 않는다는 것이다.
Deadlock Prevention
deadlock을 해결하는 방법은 크게 2가지가 있다. deadlock이 발생할 가능성이 생기면 이를 예방하는 것이 그 중 하나이다. deadlock의 필요 조건(상호 배제, 점유 대기, 비선점)은 고려하지 않고 circular wait이 발생하지 않도록만 하는 것이다. 하지만 process가 사용할 모든 자원을 미리 알고 있어야 circular wait이 발생하는지를 예측할 수 있기 때문에 현실적으로 구현이 불가능에 가깝다. deadlock prevention의 방법으로는 process 시작 거부와 자원 할당 거부가 있다.
Process 시작 거부
자원에 대한 vector와 matrix를 정의해 계산하고, 이를 이용해 deadlock 발생을 예측해 회피한다. OS는 process 수행 이전에 아래의 정보들을 모두 알고 있어야만 한다.
-
자원: system에 존재하는 자원의 전체 개수
\[R = (R_1,R_2, ...,R_m)\] -
가용: system에 존재하는 자원 중 현재 사용 가능한 자원의 개수
\[V=(V_1,V_2,...,V_m)\] -
요청: process가 요청하고 있는 자원의 개수
\[C=\begin{pmatrix}C_{11}&...&C_{1m}\\&...&\\C_{n1}&...&C_{nm}\end{pmatrix}\]\(C_{ij}\): process \(i\)가 자원 \(j\)를 \(C_{ij}\)만큼 요청
-
할당: process가 할당받고 있는 자원의 개수
\[A=\begin{pmatrix}A_{11}&...&A_{1m}\\&...&\\A_{n1}&...&A_{nm}\end{pmatrix}\]\(A_{ij}\): process \(i\)가 자원 \(j\)를 \(A_{ij}\)만큼 할당받음
위의 vector와 matrix는 정의에 따라 아래와 같은 수식들이 성립된다.
-
전체 자원의 개수는 가용 가능한 자원과 전체 process들에게서 사용중인 자원의 합이다.
\[R_j=V_j+\sum_{j=1}^m{A_{ij}}\] -
요청 자원은 전체 자원의 양보다 많을 수 없다.
\[C_{ij}\le R_j\] -
할당 자원은 요청 자원보다 많을 수 없다.
\[A_{ij}\le C_{ij}\]
process 시작 거부 방식은 모든 자원들에 대해 아래의 수식을 만족할 때에만 해당 process를 시작한다.
\[R_j\ge C_{(n+1)j}+\sum_{i=1}^n{C_{ij}}\ \ \ for\ all\ j\]모든 자원들에 대해 process가 요청하는 전체 자원의 합과 새로운 process가 요청하는 자원을 더한 값이 실제 자원의 양보다 작을 때에만 process를 시작하는 것이다. 이는 최악의 경우에도 실행됨을 보장하기 위함이다. 최악의 경우라는 것은 모든 process들이 동시에 자신이 요청할 수 있는 최대 자원량을 한꺼번에 요청하는 상황을 뜻한다. 이러한 보수적인 조건을 만족했을 때에만 process가 실행되는 것이기에 현실에서 사용할 수 없는 방식이다.
자원 할당 거부 (은행원 algorithm)
자원 할당 거부를 통한 deadlock prevention는 은행원 algorithm을 사용한다. 은행원 algorithm이란 system의 상태를 safe state와 unsafe state로 구분한다. safe state란 deadlock이 발생하지 않도록 process에게 자원을 할당할 수 있는 경로가 존재하는 상태를 의미하고, unsafe state란 해당 경로가 존재하지 않는 상태를 말한다. 은행원 algorithm은 safe state를 유지할 수 있는 thread의 요청에 대해서만 수락해 자원을 할당해주고, unsafe state가 되는 thread의 요청에 대해서는 계속 거절한다.
다음은 safe state가 계속되어 정상적으로 모든 process가 실행되는 경우 대한 예시이다.
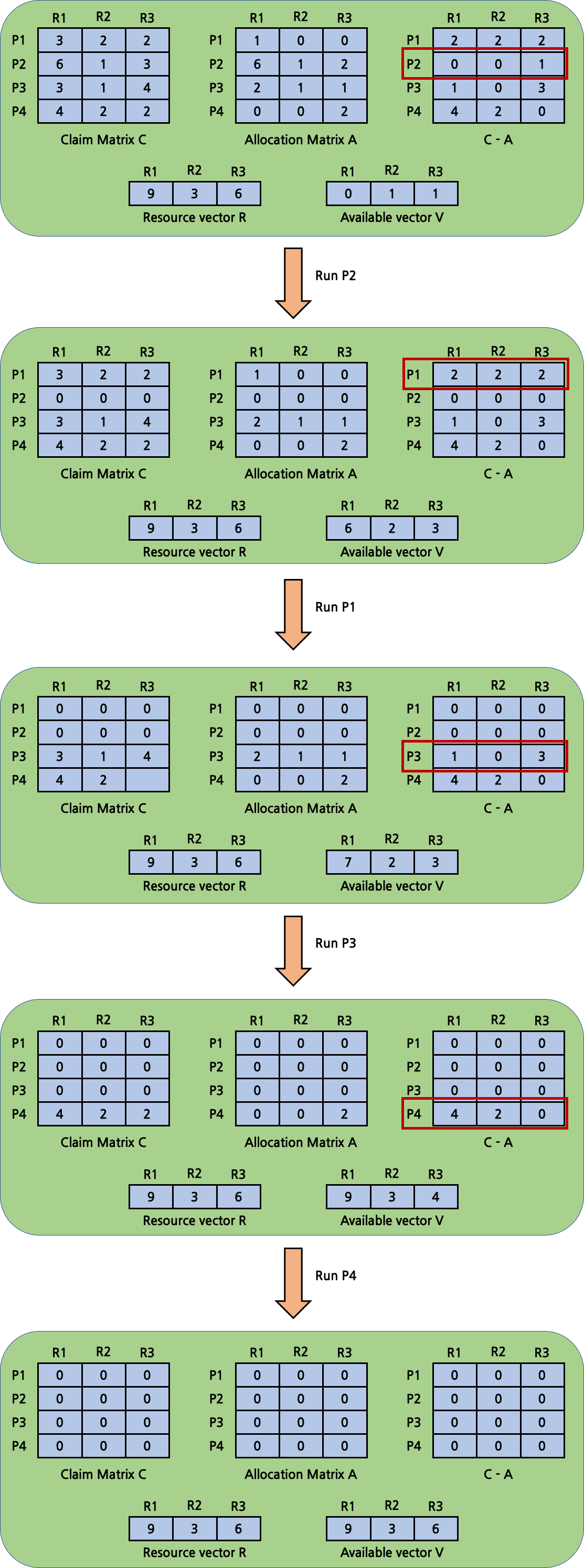
\(C-A\)는 추가적으로 할당해야 할 자원들의 matrix이다. \(V\)와 비교해 더 작은 값들을 갖는 \(C-A\)의 row를 찾은 뒤 해당 process를 실행시키게 된다. 이후 \(A\)에서 해당 process의 값들이 \(V\)에 더해지게 된다. 해당 process의 값들은 \(C\)와 \(A\), \(C-A\)에서 모두 0이 된다.
아래는 unsafe state에 대한 예시이다. 실행할 수 있는 process가 없는 경우이다.
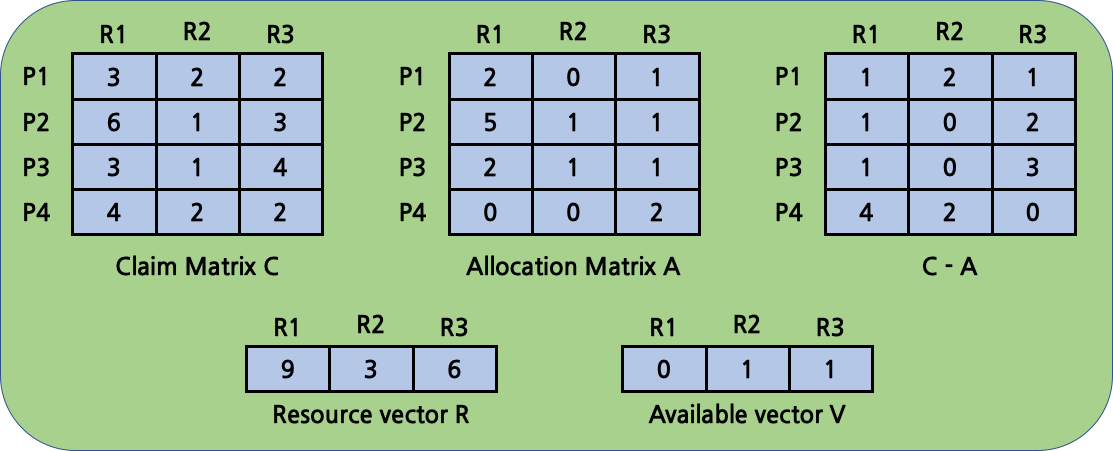
Deadlock Detection
deadlock detection은 deadlock prevention에 비해 상대적으로 낙관적인 방법이다. process의 시작이나 자원 접근에 대해 제약을 가하지 않고, 요청이 들어오면 항상 할당을 한다. 대신 주기적으로 system에서 deadlock이 발생했는지를 검사하고 발생했을 경우 이를 해결하게 된다.
Deadlock Detection
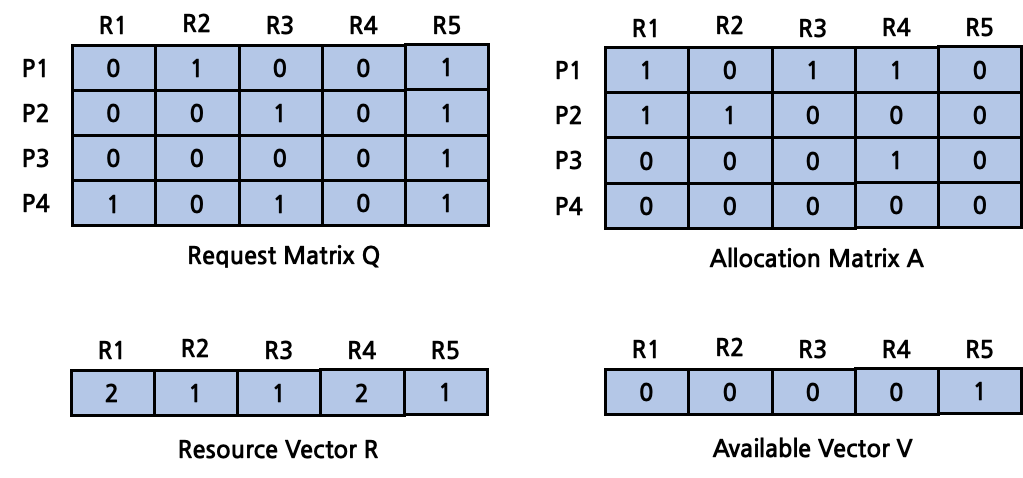
deadlock prevention과 비슷하게 동작한다. algorithm은 다음과 같다.
- 임시 vector \(W\)를 생성해 초기 값으로 \(V\)를 복사한다.
- \(Q\)의 row를 탐색하며 모든 자원이 \(W\)보다 작은 process가 있을 경우 해당 process를 mark한다. 그러한 process가 없을 경우 deadlock이 발생한 것이므로 algorithm을 종료한다.
- process를 찾았을 경우 \(W\)에 \(A\)에서의 process의 값을 더한다. 2단계로 돌아가 다시 수행한다.
Deadlock Solution
여러 deadlock solution이 있지만, 그 중에서 대표적인 solution들을 살펴본다.
-
deadlock에 연관된 모든 process 중지
실제 많은 OS에서 채택하고 있는 방식이다.
-
deadlock에 연관된 모든 process roll-back 후 재수행
특정 checkpoint까지 roll-back 후 재수행하는 방식이나, 어떤 process가 먼저 수행될 지는 nondeterministic하기 때문에 deadlock이 재발생할 수도 있다.
-
deadlock이 해소될 때까지 연관된 process를 하나씩 종료
비용이 가장 적은 것, 지금까지 사용한 dispatcher 시간이 적은 것, 지금까지 생산한 출력량이 적은 것, 이후 남은 수행 시간이 가장 긴 것, 할당받은 자원이 가장 적은 것, 우선 순위가 낮은 것부터 종료시킨다.
-
deadlock이 해소될 때까지 연관된 자원들을 하나씩 preemption
가장 비용이 적은 자원부터 하나씩 preemption한 후 deadlock detection algorithm을 수행해 deadlock 존재 여부를 파악한다. 자원을 preemption당한 process는 해당 자원을 할당 받기 전으로 roll-back된다.
Dinning Philosopher Problem
식사하는 철학자 problem은 deadlock의 대표적인 예시이다. 여러 철학자가 원탁 테이블에 앉아 식사를 하는데, 철학자가 왼쪽의 포크를 먼저 집은 뒤, 오른쪽에 있는 포크를 집어 식사를 한다. 식사를 마치면 두 포크를 테이블에 내려놓는다. 철학자들은 포크 2개를 모두 가진 상태에서만 식사를 할 수 있다. 이 때 포크가 철학자의 인원수와 동일하게 배치가 되어있다고 하면 deadlock이 발생할 것이다. pseudo code는 다음과 같다.
#define N 5 //number of philosopher
semaphore fork[N];
void philosopher(int i)
{
while(1){
think();
semWait(fork[i]);
semWait(fork[(i+1) mod N];
eat();
semSignal(fork[(i+1) mod N]);
semSignal(fork[i]);
}
return;
}
int main(void)a
{
for(int i = 0; i < N; i++) //semaphore 모두 로 초기화
semInit(fork[i], 1);
for(int i = 0; i < N; i++)
philosopher(i);
return 0;
}
solution은 동시에 테이블에 앉을 수 있는 최대 인원수를 N-1로 제한하는 것이다. 이 때 semaphore를 사용한다.
pseudo code는 다음과 같다.
#define N 5 //number of philosopher
semaphore fork[N];
semaphore table;
void philosopher(int i)
{
while(1){
think();
**semWait(table);**
semWait(fork[i]);
semWait(fork[(i+1) mod N];
eat();
semSignal(fork[(i+1) mod N]);
semSignal(fork[i]);
**semSignal(table);**
}
return;
}
int main(void)
{
for(int i = 0; i < N; i++) //semaphore 모두 로 초기화
semInit(fork[i], 1);
**semInit(table, N-1);**
for(int i = 0; i < N; i++)
philosopher(i);
return 0;
}