숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
Hard Disk
hard disk는 가장 범용적으로 사용되는 저장 장치이다. main memory와 다르게 영속적(persistent)으로 data를 저장할 수 있다. hard disk는 물리적으로 회전(rotation)하면서 data를 저장할 장소를 찾는다. 전체 구성 요소는 다음과 같다.
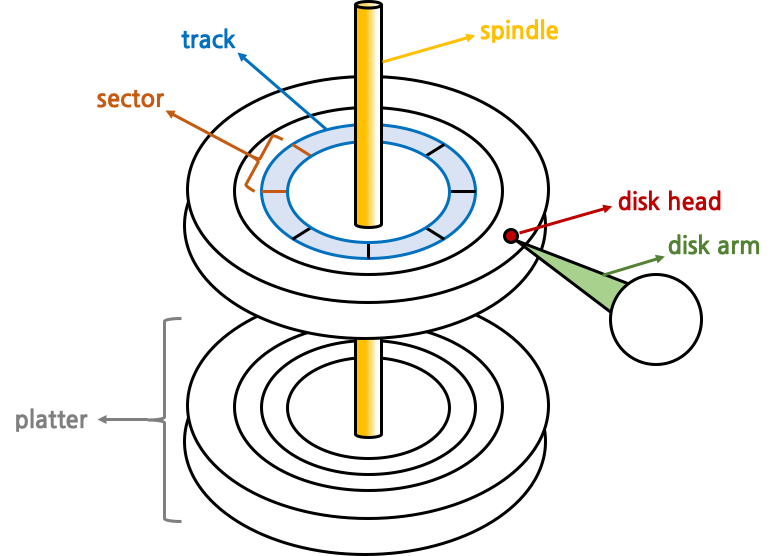
hard disk는 여러 층으로 이루어져 있다. 각 층은 platter라는 하나의 원판으로 구성되고, 모든 원판의 중심을 통과하는 spindle이 있다. spindle은 실제로 rotation을 수행하는 장치이다. 각 platter는 여러 track으로 구성되는데, 원하는 track을 선택하기 위해 disk arm이 이동하게 된다. disk arm의 끝에 달려있는 disk head가 실제로 data를 읽게 된다. 각 track은 sector로 구분되는데, sector는 가상 memory에서의 frame 또는 block과 같이 data가 한번에 읽고 씌여지는 단위이다. disk arm은 원하는 track으로 이동할 때 사용하고, 원하는 sector로 이동하기 위해서는 spindle이 flatter를 rotation시켜야 한다. 따라서 disk I/O의 단계는 다음과 같이 정리된다.
- disk arm을 해당 track으로 이동 (seek time)
- 해당 sector로 roatation (rotational delay)
- 실제로 data를 read (transfer time)
disk I/O에 소요되는 시간은 seek time + rotational delay + transfer time이 된다. 이 중 rotational delay, transfer time은 HW의 성능에 의해 좌우되기 때문에 실제로 disk scheduling을 통해 향상시키고자 하는 것은 seek time이다.
Disk Scheduling
disk의 seek time을 줄일 수 있는 disk scheduling algorithm들에 대해 알아보자. queue에 읽어야 할 track number가 다음과 같은 순서로 들어온다고 가정한다. 또한 disk arm의 시작 위치는 15라고 가정한다.
\[15, 8, 17, 11, 3, 23, 19, 14, 20\]FCFS(First Come First Service)
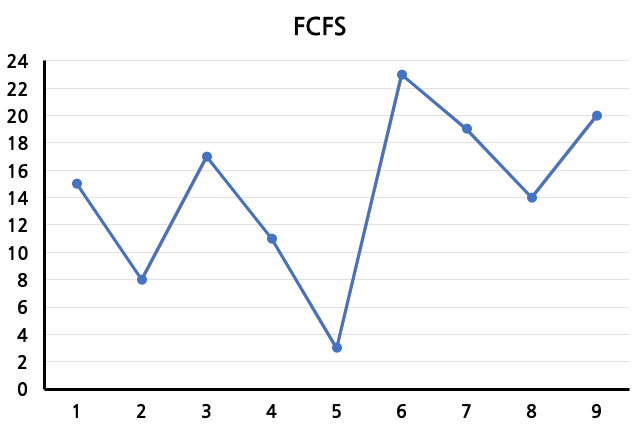
queue에 들어온 순서대로 track으로 이동하는 것이다. 즉, FIFO와 동일한 방식이다. 모든 track에 대해 공정하게 접근하지만, 비효율적인 이동이 다수 발생할 수 있다는 단점이 있다.
SSTF (Shortest Seek Time First)
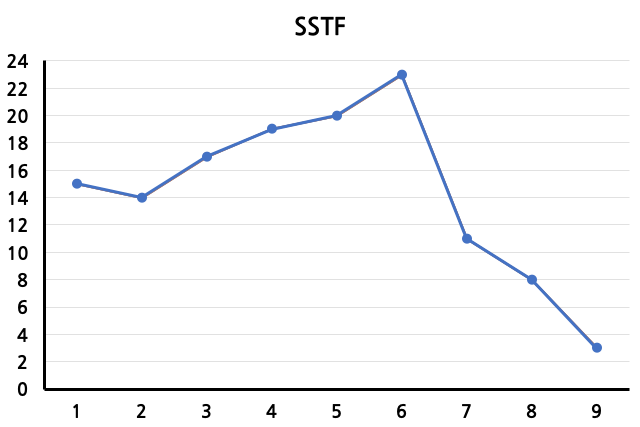
현재 disk arm의 위치에서 가장 적게 움직여 도달할 수 있는 track으로 먼저 이동하는 방식이다. FIFO에 비해 효율적이지만, 양극단(0, 24)에 가까운 track에 대해서는 starvation이 발생할 수 있다. 또한 하나의 track만이 계속 사용될 경우 arm이 움직이지 않고 고정되는 arm stickiness 현상이 발생할 수도 있다.
SCAN
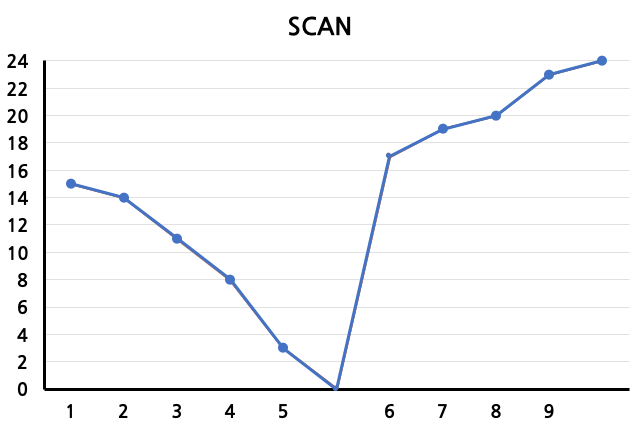
한 방향으로의 관성을 갖고 움직여 양극단에 도달했을 경우에 반대 방향으로 전환해 이동하는 방식이다. 위의 경우는 track number가 감소하는 방향으로 시작한다고 가정한 것이다. 5시점까지 수행해 track 3으로 이동한 후, 최저점(0)에 도달한 뒤에 방향을 전환하게 된다. 마지막 9시점에서 23까지 이동하고 난 후 최고점(24)에 도달하게 된다. 이후 다시 방향을 전환하게 될 것이다. SSTF와 동일하게 starvation, arm stickiness가 발생할 수 있다.
C-SCAN
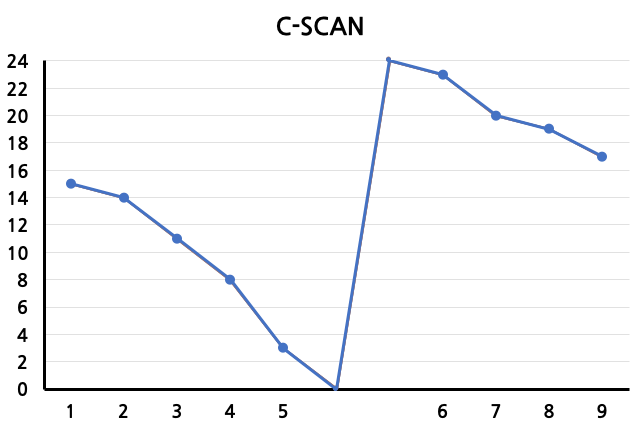
SCAN과 유사하지만 한 방향으로만 track을 읽어들이는 정책이다. 1~5시점까지는 track number를 감소시키면서 track을 읽어들이고, 5시점 이후에 최저점(0)에 도달한 뒤 최고점(24)로 이동해 다시 track number를 감소시키며 track을 읽어들인다. 이 역시 starvation, arm stickiness가 발생할 수 있다.
C-LOOK
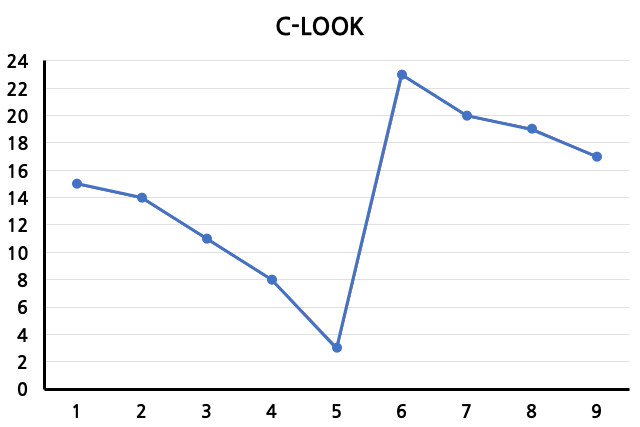
C-SCAN과 유사하지만 양극단(0, 24)까지 이동하지 않고 queue에서 가장 작은 track number(3), 가장 큰 track number(23)까지만 이동한다. 여전히 starvation, arm stickiness가 발생할 수 있다.
N-step-SCAN / FSCAN
queue를 길이가 N인 하위 queue로 분할한 뒤, 각 queue에 대해 개별적으로 SCAN 정책을 사용하는 방식이다. 하나의 queue가 처리되는 동안 들어오는 신규 요청들은 모두 다른 queue에 추가된다. 따라서 starvation, arm stickiness가 발생하지 않는다. N의 값에 따라 성능이 달라지는데, N의 값이 커질 경우 SCAN과 유사한 성능을 보이고, N=1일 경우에는 FCFS와 완전히 동일한 정책이다. 이 중 FSCAN은 N=2인 경우를 지칭한다.
RAID
disk의 성능 지표로는 총 3가지가 있다. 성능(performance), 용량(capacity), 신뢰성(reliability)이다. performance는 얼마나 I/O time이 짧은가에 대한 지표이고, capacity는 얼마나 많은 data를 저장할 수 있는가에 대한 지표,reliability는 data가 얼마나 안전하게 저장되는가에 대한 지표이다. RAID는 여러 disk가 있을 때 사용하는 disk 가상화 기술로, 위의 지표 중 capacity를 다소 희생해 reliability를 향상시키는 정책이다.
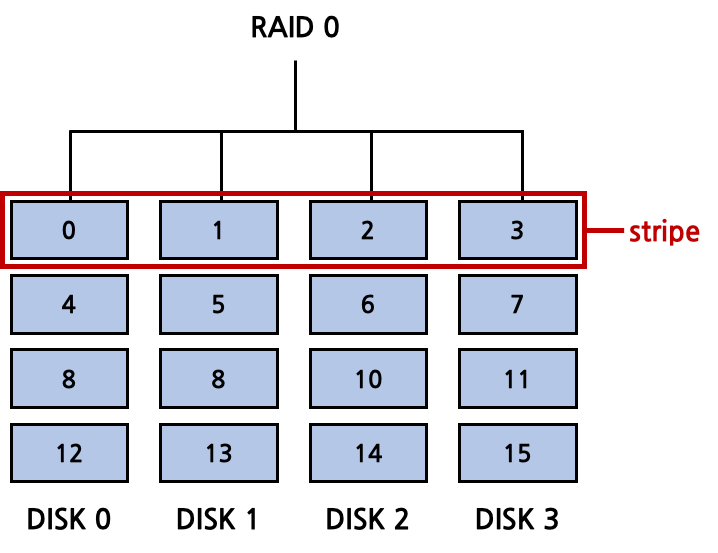
RAID 0
RAID 0은 capacity를 희생시키지 않고 performance를 향상시키는 정책이다. 큰 size의 data를 disk에 저장해야 할 때 여러 disk block을 사용해야 할 것이다. 이 때 대개 하나의 disk에 존재하는 block을 사용하게 되는데, RAID 0은 여러 disk의 block을 균등하게 사용하는 것이다. 이를 striping이라고 한다. 이로 인해 얻을 수 있는 이점은 performance인데, 하나의 disk에서 disk arm을 여러 번 이동시켜 여러 track을 읽어들일 필요 없이, 병렬적으로 (동시에) 각 disk에서 disk arm을 이동시켜 전체 seek time을 줄일 수 있다.
RAID 0은 capacity를 희생시키지 않기 때문에 N개의 disk가 있을 경우 N개의 disk 전부를 온전히 data 저장 용도로 사용할 수 있다.
RAID 1
RAID 1은 mirroring 기법을 사용한다. mirroring이란 같은 disk를 그대로 또다른 disk에 복사해 저장하는 것이다. 이를 통해 둘 중 하나의 disk가 crash된다고 하더라도 다른 mirroring disk의 data를 통해 복구할 수 있다.
RAID 1은 N개의 disk가 있을 경우 N/2개의 disk의 용량만큼 data를 저장할 수 있다. 대신 fault tolerance가 증가하게 된다. 즉, capacity를 희생해 reliability를 증가시킨 것이다.

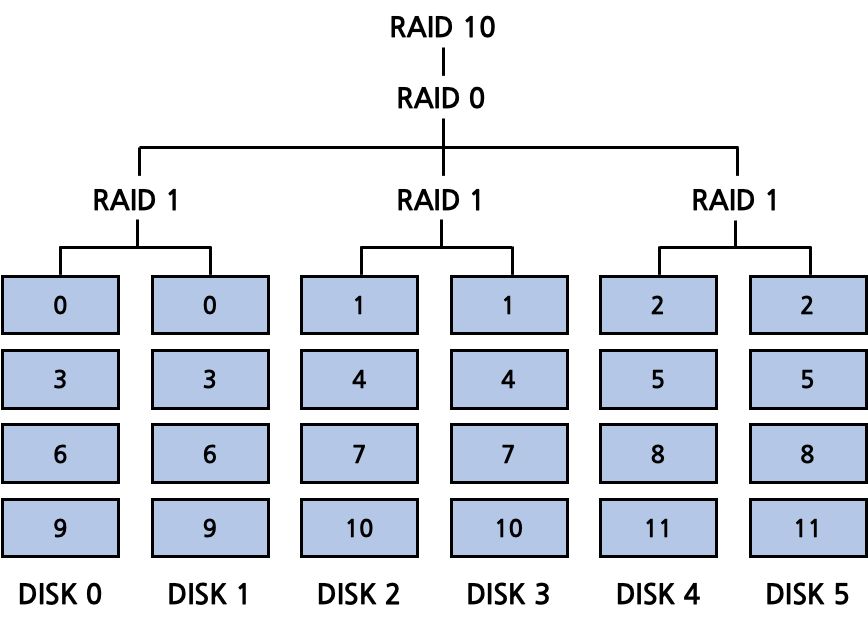
RAID 10 / RAID 01
RAID 1에 대해 RAID 0을 수행하는 정책이다. capacity는 N/2가 된다. reliability와 performance가 모두 향상된다.
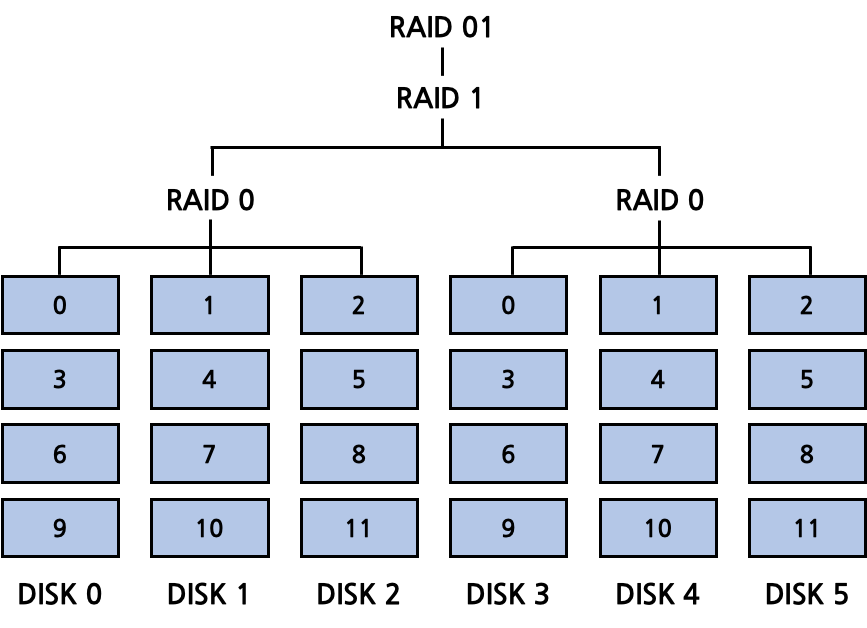
RAID 01
RAID 0에 대해 RAID 1을 수행하는 정책이다. capacity는 N/2가 된다. reliability와 performance가 모두 향상된다.
RAID 2/3/4
RAID 2/3/4는 parity disk를 사용하는 방식이다. 이중 RAID 2는 다수의 parity disk를 사용하는 것이고, RAID 3,4는 하나의 parity disk를 사용한다. parity disk란 data 복구를 위해 존재하는 disk로 다른 disk들의 data를 검사할 수 있는 값을 저장하게 된다. 이 때 사용하는 단위는 RAID 3은 bit 단위, RAID 4는 block 단위이다. RAID 3/4는 최대 1개의 disk에 대한 crash를 복원할 수 있는데, 만약 data 저장 disk가 crash됐을 경우 parity disk의 값을 사용해 복원할 수 있고, 만약 parity disk가 crash됐을 경우 다른 disk들의 값을 사용해 parity data를 다시 생성한다.

RAID 5
RAID 4에서 parity disk를 별도로 운용하지 않고 여러 disk에 나눠 저장하는 것이다. 이는 parity disk의 I/O 횟수가 일반 data 저장 disk에 비해 많아 parity disk의 수명이 짧아지는 단점을 보완한 것이다.

RAID 6
서로 다른 parity 연산을 수행해 2개의 disk를 추가로 사용하는 방식이다. 최대 2개의 disk의 crash까지 복구 가능하다.
