숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
Block
OS는 disk를 일정한 크기의 block으로 나누어 저장한다. 대개 block의 크기는 4KB이다. 각 block은 그 목적에 따라 아래의 4가지로 구분지을 수 있다.
-
Super block
file system의 global한 정보들을 담는 block으로 하나의 file system에 1개만 존재한다.
-
Allocation structure block
bitmap, linked list 등의 방법으로 inode struct와 data에 대해 used/unused 정보가 저장된다.
-
Key meta data block
inode struct의 table이 저장된다.
-
User data block
실제 data들이 저장된다.
아래는 2개의 allocation structure block이 각각 inode bitmap, data bitmap으로 운용되고, 최대 80개의 inode struct가 5개의 key meta data block에 저장되는 경우의 전체 disk 구조이다.


inode struct
inode struct에는 file에 대한 meta data가 저장된다. 각 file마다 하나의 inode struct가 부여된다. file의 size, mode, permission, 소유자, 각종 시각 등이 저장된다. unix의 ls 명령어로 출력되는 정보들, unistd.h의 stat() 함수에서 얻을 수 있는 struct stat 에 담긴 정보들은 모두 inode struct에서 가져온 것이다.
inode struct에서 가장 중요한 정보는 실제 data가 저장된 user data block의 pointer이다. file의 크기가 block의 size보다 클 경우에는 여러 block을 사용해야 하기 때문에 data block을 가리키는 여러 pointer 변수들이 inode struct에 존재하게 된다.
inode struct에서 pointer로 data block을 가리키는 방법에는 총 2가지가 있는데, direct pointer로 data block을 직접 가리키는 방법, indirect pointer로 disk block을 가리키는 pointer들이 저장된 block을 가리키는 방법이다. direct pointer만을 사용할 경우 한 file이 가질 수 있는 최대 size에 제약이 생기게 된다. 예를 들어 block size가 4KB이고, inode struct가 direct pointer 10개를 운용한다고 할 경우에는 한 file의 최대 size는 104KB=40KB가 된다. 반면 single indirect pointer 10개를 운용한다 할 경우 각 indirect pointer가 최대 저장할 수 있는 pointer의 개수는 block size / sizeof(pointer)이므로 4KB/4B = 1K이다. 각 pointer는 data block을 가리킬 수 있으므로 101K*4KB = 40MB가 된다.
directory
directory는 file의 한 종류이다. 그렇다면 directory의 inode struct는 어떻게 구성되어 있을까? inode struct의 일반적인 구성과 동일하다. directory의 data block에서의 data가 다른데, directory 하위 항목들에 대한 linked list를 저장된다. linked list의 각 node는 inode number와 name을 구성 요소로 갖는다. 이 때 inode struct pointer를 직접 저장하지 않고 단순 index 번호만 저장함으로써 공간을 절약한다. directory마다 단순 선형 linked list를 운용하게 될 경우 깊은 계층 구조를 갖는 directory에서 성능이 많이 하락하기 때문에 B-tree와 같은 자료구조를 사용해 성능을 향상시키기도 한다.
file descriptor & inode
각 process는 고유한 file descriptor table을 운용한다. 그 중 0번은 stdin, 1번은 stdout, 2번은 stderr file로 미리 예약되어 있다. file descriptor란 해당 process가 어떤 file을 open했을 때 return되는 값인데, 한 process가 한 file을 여러 번 open할 수도 있다. 이 때마다 file descriptor는 새로 할당되게 된다. 즉, 같은 file에 대해 다른 file descriptor를 동시에 가질 수도 있는 것이다. 각 file descriptor는 open file table을 가리킨다. open file table의 각 항목은 status(read/write 등), offset, inode sturct pointer 등을 저장한다. open file table에서 inode struct를 가리키고, inode struct의 block pointer가 실제로 data가 저장된 data block을 가리키는 것이다.
정리하자면, file descriptor table은 process마다 별개로 부여되는 local 구조이고, open file table, inode table은 전체 file system에서 하나를 운용하는 global 구조이다. 각 항목이 가리키는 방향은 file descriptor table → open file table → inode table → data block이다.
Reading a File from Disk
disk에서 실제 file을 읽어들이는 과정을 따라가보자. super block만이 memory에 올라와 있고, bitmap이 담긴 allocation structure block은 disk에 남아있는 상태라고 가정해보자. 다음의 순서를 따른다.
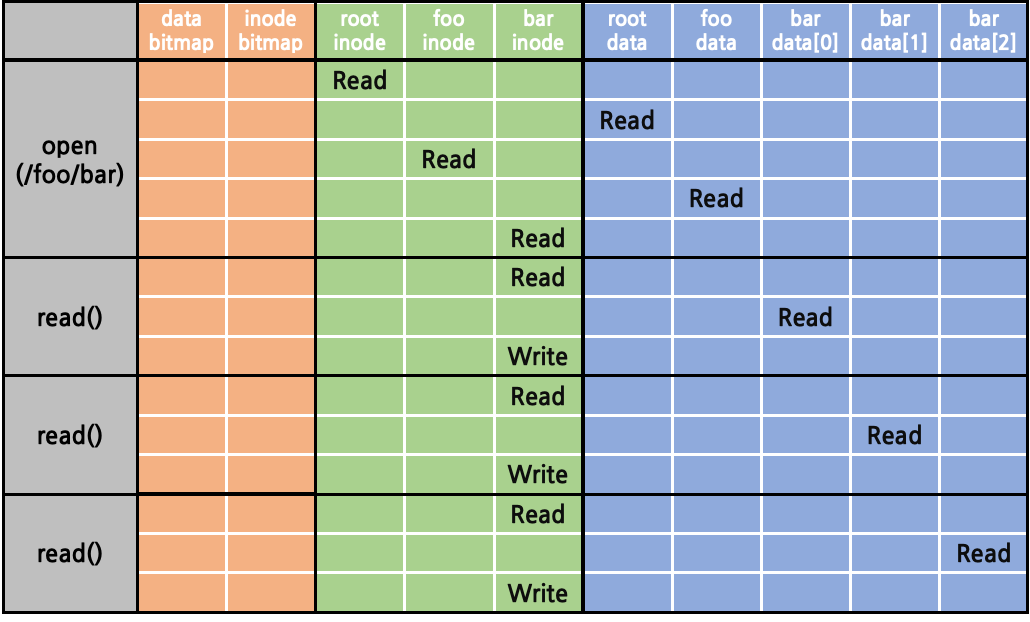
- root directory (“ / “) read
- root의 inode struct read
- root의 block pointer 획득
- root의 data block read
- root의 하위 항목들에 대한 linked list 획득
- foo directory (“ /foo “) read
- root의 하위 항목들에 대한 linked list에서 이름이 “foo”인 항목의 inode number 획득
- inode number를 통해 inode table에서의 주소 계산
- foo의 inode sturct read
- foo의 block pointer 획득
- foo의 하위 항목들에 대한 linked list 획득
- bar file (“ /foo/bar “) read
- bar의 하위 항목들에 대한 linked list에서 이름이 “bar”인 항목의 inode number 획득
- inode number를 통해 inode table에서의 주소 계산
- bar의 inode struct read
- bar[0] read
- bar의 inode struct에서 첫번째 data block pointer 획득
- data block read
- bar inode struct write(access time 등 갱신 위함)
- bar[1] read
- bar의 inode struct에서 두번째 data block pointer 획득
- data block read
- bar inode struct write(access time 등 갱신 위함)
- bar[2] read
- bar의 inode struct에서 세번째 data block pointer 획득
- data block read
- bar inode struct write(access time 등 갱신 위함)
Creating & Writing a File from Disk
disk에서 실제 file을 생성하고 write하는 과정을 따라가보자. 역시나 super block만이 memory에 올라와 있고, bitmap이 담긴 allocation structure block은 disk에 남아있는 상태라고 가정한다. 다음의 순서를 따른다.
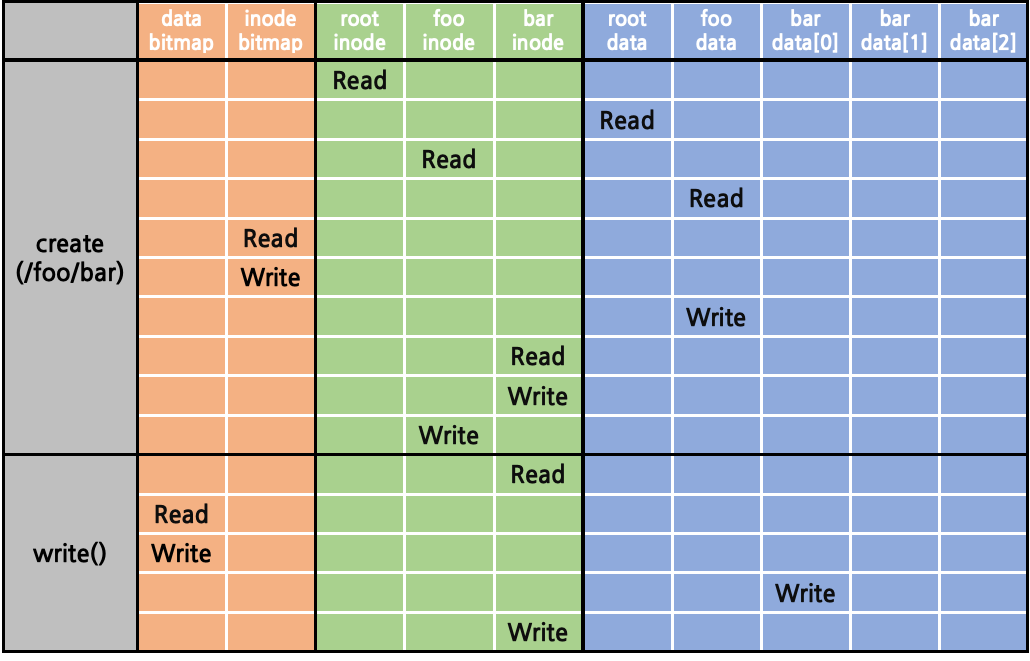
- root directory (“ / “) read
- root의 inode struct read
- root의 block pointer 획득
- root의 data block read
- root의 하위 항목들에 대한 linked list 획득
- foo directory (“ /foo “) read
- root의 하위 항목들에 대한 linked list에서 이름이 “foo”인 항목의 inode number 획득
- inode number를 통해 inode table에서의 주소 계산
- foo의 inode sturct read
- foo의 block pointer 획득
- foo의 하위 항목들에 대한 linked list 획득
- bar file (“ /foo/bar “) create
- 현재 사용 중인 inode number을 확인하기 위해 inode bitmap read
- 미사용 중인 inode number 선택 후 사용 중으로 변경하기 위해 inode bitmap write
- foo의 하위 항목들에 대한 linked list에 획득한 inode number와 “bar” 명칭으로 항목 추가하기 위해 bar data block write
- bar inode struct read (inode struct 초기화 위함)
- bar inode struct write (inode struct 초기화 위함)
- foo inode struct write (access time 등 갱신 위함)
- bar file (“ /foo/bar “) write
- write 가능한 여유 있는 data block 존재 여부 확인하기 위해 bar inode struct read
- 현재 사용 중인 data block number 확인하기 위해 data bitmap read
- 미사용 중인 data block number 선택 후 사용 중으로 변경하기 위해 data bitmap write
- bar data block write
- bar inode write (access time 등 갱신 위함)
FFS (Fast File System)
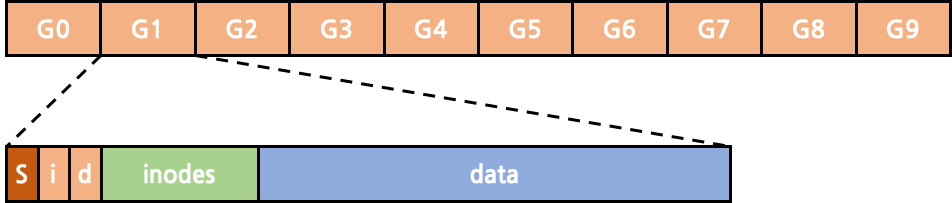
fast file system은 기존의 unix file system에서 성능을 더 향상시킨 file system이다. 기존의 file system은 disk 전체에 super block, inode bitmap, data bitmap이 disk에 오직 1개만 존재했다. 또한 inode 역시 disk의 한 영역에 몰려서 저장되어 있어 실제 data block들과의 disk상에서의 물리적 거리가 멀 수 밖에 없었다. FFS는 이러한 단점을 해결하고자 disk 전체를 여러 group으로 나누고, 각 group마다 super block, bitmaps, inodes, data block들을 부여한다. 이를 통해 inode에서 참조하는 data block과 실제 inode가 저장된 block 사이의 물리적 거리가 줄어들어 seek time이 감소한다.
또한 FFS는 directory 구조 역시 개선했는데, 기존의 file system은 단순한 계층 구조였기에 하위 file들의 data block이 부모 directory의 data block과 멀리 떨어져 있을 가능성이 농후했다. FFS는 동일한 directory에 있는 file에 접근할 확률이 40%나 된다는 통계에 기반해 (Name-based Locality) directory와 그 하위 file들을 disk 내에서 같은 group 안에 배치하도록 했다. 이를 통해 seek time을 감소시킬 수 있었다.
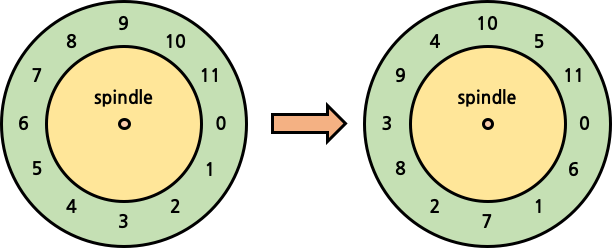
마지막으로, FFS는 disk layout에 대해서 최적화를 수행했다. 초기 hard disk는 HW의 성능이 떨어져 rotation 속도가 많이 느렸다. 하지만 점차 HW가 발전함에 따라 rotation 속도가 비약적으로 상승했고, 연속된 sector를 읽어들이기에는 이미 head가 다음 sector를 지나쳐버리는 증상이 발생하게 되었다. 이를 해결하기 위해 FFS는 다음 sector를 연속적으로 배치하지 않고, 1칸 뒤에 배치하는 식으로 sector 배치를 변경했다.
이 외에도 FFS는 block의 크기를 줄여 내부 단편화 현상을 감소시키고, symbolic link를 도입하는 등의 여러 변화를 채택했다.
Crash Consistency
Disk Crash Scenario
disk I/O 과정에서 crash가 발생하는 경우에 대해서 살펴보자. 이미 존재하는 file에 대해 새로운 data를 append하는 경우에는 data bitmap, inodes, data block을 갱신해야 한다. 위의 3가지 block들에 대한 갱신은 atomic하게 이루어져야 한다. 이 과정에서 발생할 수 있는 crash scenario는 다음의 6가지이다.
-
data block만 정상 갱신, data bitmap, inodes는 crash되는 경우
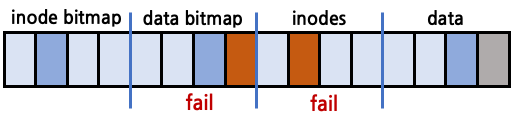
data bitmap과 inodes가 모두 crash되었기 때문에 bitmap과 inodes 사이의 불일치(inconsistent)는 없다. 따라서 consistent한 상황이다. 대신 data block은 갱신이 되었는데, 해당 block은 data bitmap에서도 unused로 표시가 되어 있고, inodes에도 data block 포인터가 연결이 되어 있지 않기 떄문에 garbage data이다.
-
inodes만 정상 갱신, data bitmap, data block은 crash되는 경우
data bitmap은 crash, inodes는 정상 갱신되었기 때문에 inconsistent한 상황이다. inodes는 이미 data block을 가리키는데 해당 data block에는 data가 쓰여 있지 않고, data bitmap에서도 해당 data block은 unused로 표시가 되어 있다.
-
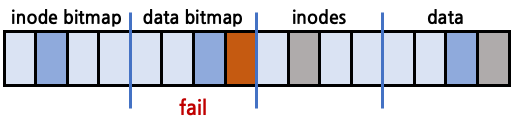
data bitmap만 정상 갱신, inodes, data block은 crash되는 경우

data bitmap은 정상 갱신되었지만, inodes는 crash되었기 때문에 inconsistent한 상황이다. data block에는 write가 되지 않았고, inodes에서도 해당 data block을 가리키지 않는데 datat bitmap에서는 used로 표시가 되어있는 경우이다. 이후 해당 data block은 사용되지 못하고 낭비될 것이다.
-
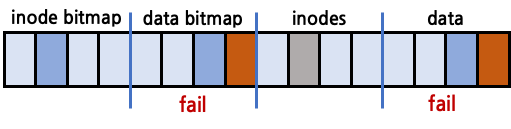
data bitmap, inodes는 정상 갱신, data block만 crash되는 경우
data bitmap과 inodes가 모두 정상갱신 되었기 때문에 consistent한 상황이다. data block에 write만 되지 않은 것이기 때문에 garbage data가 저장된 상태이다.
-
inodes, data block은 정상 갱신, data bitmap만 crash되는 경우
data bitmap은 crash되고, inodes는 정상 갱신되었기 때문에 inconsistent한 상황이다. 이 경우 inode에서 data block을 가리키고, 해당 data block에는 정상적인 data가 쓰여져 있음에도 data bitmap에서 unused로 표시가 되어 있기 때문에 언제든 덮어씌워질 수 있고, 다른 inode가 동일한 data block을 가리킬 수도 있다.
-
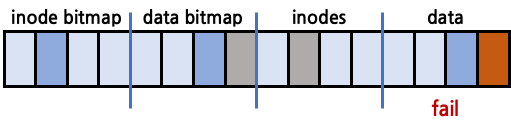
data bitmap, data block은 정상 갱신, inodes만 crash되는 경우
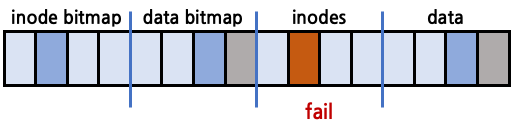
data bitmap은 정상 갱신, inodes는 crash되었기 때문에 inconsistent한 상황이다. 이 경우 data block에도 정상적인 data가 쓰여져 있고 data bitmap에서도 used로 표시가 되었지만 inodes에서 해당 data block을 가리키지 않기 때문에 해당 data block은 어떤 file에도 연결되지 못한다. 이를 orphan data block이라고 한다.
FSCK
FSCK는 unix에서 file system에서의 crash inconsistency를 찾아내 해결하는 도구이다. 초기의 file system은 crash inconsistency를 발견하더라도 무시했다가 rebooting 과정에서 이를 해결했다. FSCK는 rebooting 없이도 이를 해결하고자 개발되었다. FSCK 동작 중에는 file system이 어떠한 다른 동작도 수행하지 않는다고 가정한다.
FSCK는 inodes 정보를 기반으로 bitmap을 재갱신한다. 개념적으로 간단하고 별도의 write overhead가 없다는 장점이 있지만, 과도하게 많은 연산을 수행하고, consistent한 경우에 대해서는 해결이 불가능하다는 단점이 있다.
Journaling (WAL: Write-Ahead Logging)
Journaling은 disk I/O, 특히 write 연산 시에 log를 기록해 저장했다가 이를 crash inconsistency를 해결하는데 사용하는 방식이다. write 요청이 올 경우 disk는 이를 즉시 갱신하지 않고 write 작업 중 수행할 연산들에 대한 log를 미리 작성한다. 이후 만약 write 도중 disk crash가 발생할 경우, 해당 log를 확인해 다시 write를 수행한다. 이러한 log를 저장하는 용도로 disk에 journal block을 새로 추가한다. log의 저장 단위는 transaction이다.