숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
Process / Program
process와 program를 우선 정의내려 보자. program은 disk에 위치한다. 반면 process는 memory에 위치한다. process는 disk에 위치한 program file을 memory에 올린 것이다. 이 때 program file 전체를 모두 memory에 올릴 수도, 필요한 일부분만 memory에 올릴 수도 있다. 정리하자면, process는 Runnable(Running) program이다.
Process의 구성
process는 위에서 언급했듯이 Memory에 위치한다. 구체적으로 Stack, Heap, Data, Text(Code) 등의 영역으로 구분된다. process는 자신만의 물리적 Memory 공간을 할당받아 그 안에서 자신만의 가상 주소 체계를 갖는다. process의 가상 주소 0번지는 Stack의 처음이고, 가상 주소의 가장 끝은 Text의 끝이다. process는 memory로만 구성되지는 않으며 register도 있다. Program Counter (PC), Stack Pointer 등이 있다. PC는 다음에 실행할 명령어를 가리키게 되며, Stack Pointer는 Stack 내의 특정 공간의 위치를 저장해준다.
Process 생성
fork()와 같은 system call을 사용해 process를 생성할 수 있다. 위에서 설명했듯이 process를 생성한다는 것은 program를 memory로 load하는 작업이다. 더 정확히는 process 자신의 가상 주소 공간 안으로 load한다. disk와의 I/O는 시간이 많이 걸리는 작업이기 때문에, 한꺼번에 전부를 load하지는 않고 가장 먼저 필요한 일부분을 우선 load한 뒤 실행 도중 나머지 code와 data를 page 단위로 나눠 load한다. stack 내에 지역변수, 함수 parameter, return address 등이 저장되며, heap에서 malloc(), free() 등의 동적 할당 작업을 수행하고, 그 사이 OS는 I/O setup (표준 fd 할당) 등의 여타 초기화 작업을 진행한다. process 시작 시에는 진입점 main()을 찾게 되면 os에서 process로 cpu 제어권이 넘어온다.
Process Status
process는 여러 상태를 갖게 된다. 왜냐하면 os는 한 번에 하나의 process만을 수행하는 것이 아니라, dispatcher라는 전환기를 사용해 여러 process를 아주 짧은 간격으로 번갈아 실행하기 때문이다. 하나의 cpu는 한 번에 하나의 process밖에 실행하지 못하므로, 필연적으로 다른 process들은 실행 중인 상태가 아니게 된다. 결국, 여러 가지 상태를 정의해야 한다.
2가지 State
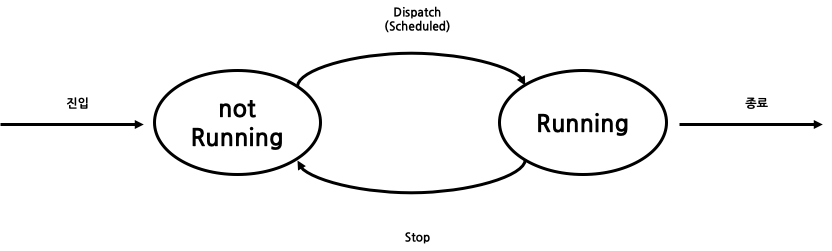
우선 수행(Running), 비수행(not Running)의 두 단계로 process의 상태를 나눌 수 있다. Running이라는 것은 프로그램의 일부 또는 전부가 memory에 올라갔다는 뜻이다. 그 동안 다른 process는 not Running 상태이다. 이후 Time Quntum (TQ)이 지나가거나(Interrupt) disk I/O 요청 등의 cpu가 process를 전환해야 할 시기가 오게 되면 dispatcher가 수행할 다음 process를 선택하게 된다. 그 동안 이전에 수행됐던 해당 process는 not Running 상태가 된다.
3가지 State
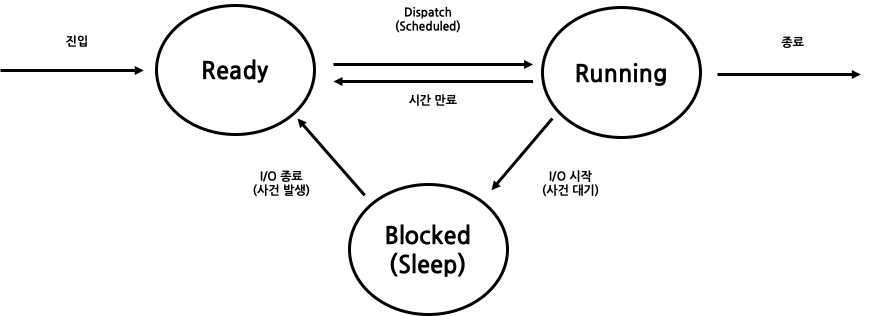
not Running 상태를 Ready / Blocked 상태로 나눌 수 있다. Ready 상태는 process가 run할 수 있는 준비가 된상태로, run을 할 조건은 충족됐지만 os가 우선순위 등을 이유로 아직 실행하지 않은 것을 뜻한다. Blocked 상태는 간단하게 말해 자고 있는(Sleep) 상태이다. 대개 disk I/O를 뜻한다. disk I/O 도중에는 SATA와 같은 disk interface가 대부분의 작업을 수행하지, cpu는 별 일을 하지 않는다. 따라서 Blocked 상태의 경우에는 언제든 다른 process에게 cpu 점유를 뺏길(preemption) 수 있다.
5가지 State
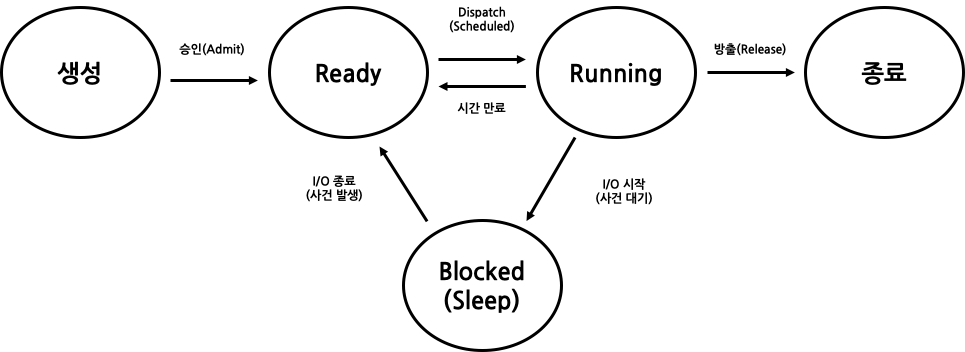
생성과 종료 상태가 추가된 것이다. 추가된 State는 특별한 점이 없지만, 여기서는 각 화살표에 대해 주목해봐야 한다. Ready 상태에서 Running 상태로 가는 것을 Dispatch라고 부른다. 또한 Running 상태에서 Blocked 상태로 가는 것(I/O initiate)를 사건 대기라고 명명하고, I/O가 끝난 경우를 사건발생 이라고 부른다. 즉, I/O 가 끝나는 것이 사건이다.
9가지 State
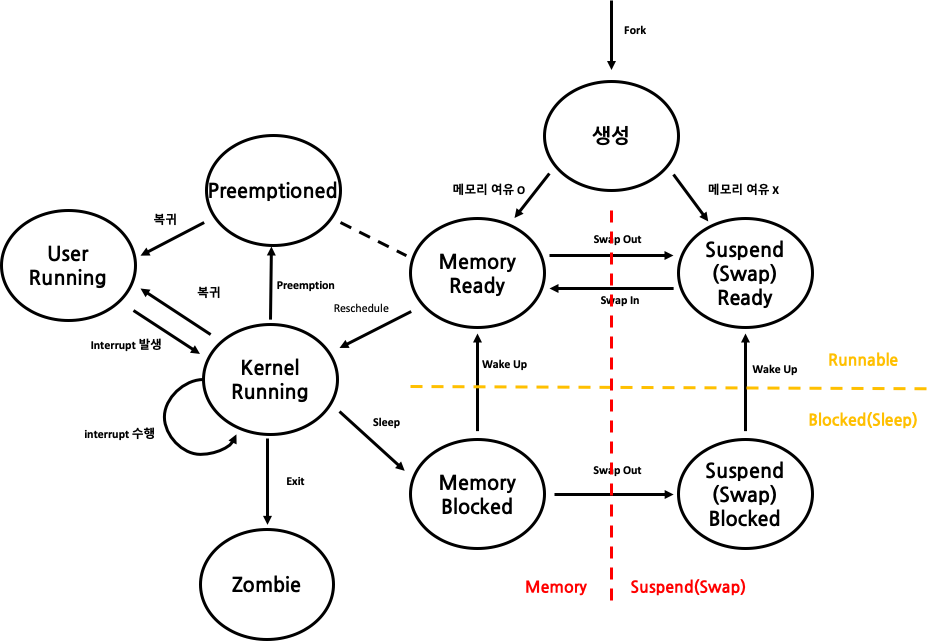
많은 상태가 추가됐는데, 우선 생성 상태에서부터 따라가보자. process 생성 시 memory의 여유가 충분할 경우에는 바로 Ready 상태로 갈 수 있겠지만, 만약 그렇지 않다면 Suspend 상태로 가게 된다. program file이 memory가 아닌 disk 내의 swap 공간으로 이동된 경우를 뜻한다. Suspend 상태에서 할 수 있는 작업은 Swap In(memory로 이동해 Ready 상태가 되는 것)밖에 없다. Ready 상태에서는 Kernel mode로 가거나 User mode로 갈 수 있다. User mode로 가는 방법은 2가지가 있는데, Kernel mode를 거쳐가거나, preemption을 해 거쳐가는 것이다. preemption이란 ‘선점’으로 번역되고는 하는데, 직관적으로 와닿지 않는 번역이다. 본 뜻은 다른 process가 차지하고 있던 CPU를 빼앗는 것이다. User mode에서는 I/O를 시작하거나 System Call 호출, Interrput 등이 발생하게 되면 Kernel mode로 이동하게 된다. Kernel Mode에서 수행이 끝나면 다시 preemption을 통해 User Mode로 돌아가거나 Memory Blocked 상태로 넘어갈 수 있다. Memory Blocked 상태에서 memory에 여유가 사라지면 해당 process는 Suspend상태로 넘어갈 수 있다. 한편, Kernel Mdoe에서는 exit()을 호출해 종료를 위해 Zombie 상태가 될 수도 있다.
Process 실행
os가 process를 실행하는 과정을 살펴보자. 우선 process list에 새로운 항목을 생성해야 한다. 이후 memory page를 할당하고, disk에 있는 program executable file을 memory page에 load한다. 마지막으로 진입점(main())으로 포인터를 이동시킨다. 더 세부적인 과정은 아래와 같다.

Mode
process는 다양한 연산을 수행할 수 있어야 한다. 그런데 그 중에는 I/O나 memory 접근 등의 특수 권한이 필요한 연산도 있다. 이러한 연산들을 process가 수행하게 하기 위해서는 어떻게 할까? 가장 간단한 방법으로는 process에게 별도의 제한 없이 모든 연산을 수행할 수 있게 하는 것이다. 하지만 접근 권한이 없는 곳에 접근하는 연산을 수행하게 되면 당연히 문제가 발생하게 된다. 현대의 OS는 이러한 문제를 해결하기 위해 User mode와 Kernel mode를 구분하는 정책을 채택했다. 특수 권한이 필요한 명령들은 Kernel mode에서 실행하고, 그 외 일상적인 연산들에 대해서는 User mode에서 실행하도록 구분짓는 것이다. User mode에서도 HW resource에 대해서는 모두 접근 가능하며, Kernel mode는 이에 더해 추가적으로 모든 system resource에 대해서도 접근할 수 있다. 기본적으로는 process는 User mode이며, 수행하는 연산에 따라 잠시 Kernel mode로 전환되었다가 다시 User mode로 복구된다. program의 현재 상태 word를 저장하는 PSW bit가 있는데, 이를 통해 현재 process의 mode가 어떤 type인지 파악할 수 있다.
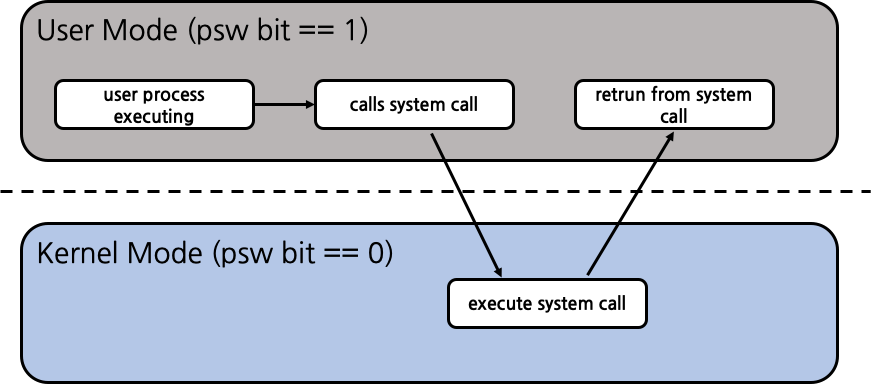
Interrupt
interrupt란 process가 User mode에서 Kernel mode로 변경되도록 하는 것이다. Interrupt는 크게 HW interrupt와 SW interrupt로 구분할 수 있다. 일반적으로 interrupt라 불리우는 것은 대개 HW interrupt를 의미하며, 현재 수행 중인 process와 관계 없이 외부에서 유발되는 사건에 의해 비동기적으로 발생하는 interrupt를 뜻한다. 대표적으로 I/O가 종료되거나, Time Quntum이 다 되어 running process를 전환해야 할 경우(clock interrupt)가 있다. SW interrupt는 trap과 system call이 있다. trap은 현재 process의 명령어를 수행하는 도중 error나 exception이 발생해 이에 대한 처리를 하는 비동기적 호출이다. system call은 superviser call이라고도 불리우며, 명시적으로 system call (OS function)을 호출(동기적 호출)하는 것이다.
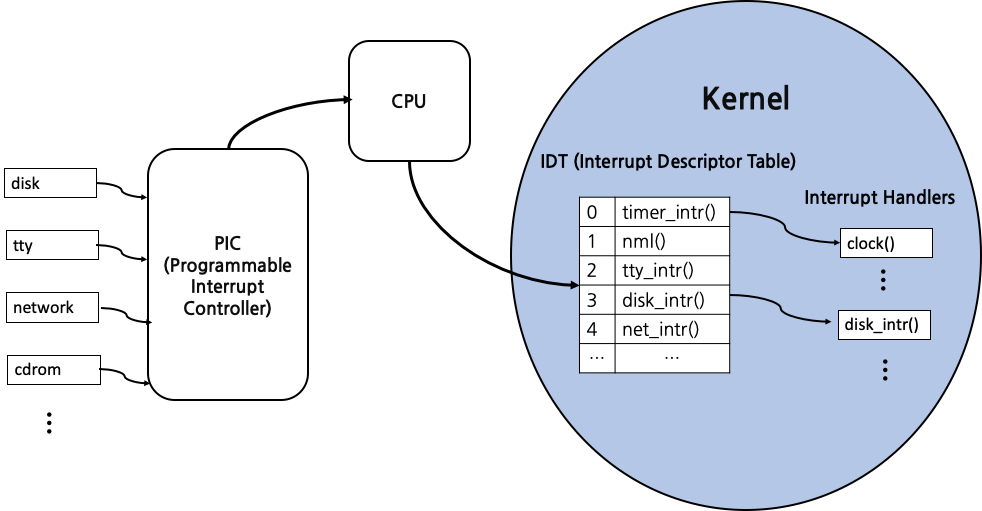
HW Interrupt / Trap 처리 과정
비동기 interrupt (HW Interrupt, Trap)의 처리 과정에 대해 알아보자. Programmable Interrupt Controller가 여러 HW에서 interrupt 정보를 수집하고, interrupt가 발생했을 경우 CPU에 신호를 전달한다. CPU는 Kernel의 Interrupt Descriptor(Vector) Table에서 해당 interrupt의 entry pointer 값을 찾는다. 이 때 mode가 User mode에서 Kernel mode로 전환되게 된다. 찾은 pointer 값은 interrupt handler 내부의 특정 함수를 가리키게 되는데, 이를 이용해 실제 interrupt 처리가 수행되게 된다.
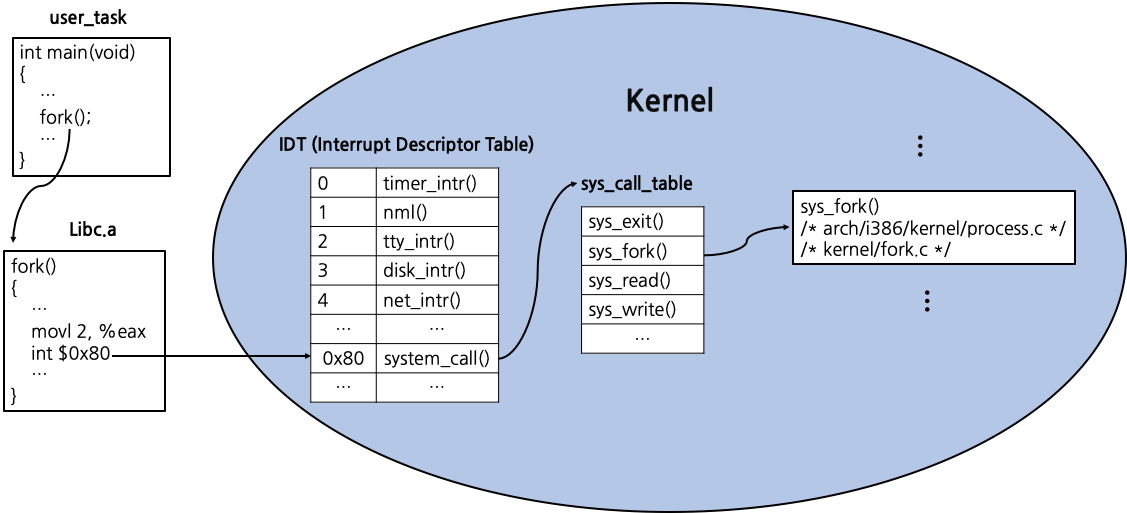
System Call
System Call 처리 과정
fork()를 호출하는 예시를 따라가며 system call 처리 과정을 이해해보자. system call도 결국 interrupt이기 때문에 위에서 살펴본 interrupt 처리 과정과 유사하다. c source code에서의 fork() 함수는 assembly code에서 MOVL과 INT의 두 명령어로 변환된다. 이 중 INT 명령어는 interrupt 명령어이다. 이를 통해 IDT를 찾아가게 된다. system call은 결국 interrupt의 한 종류이기 때문에 IDT에서 한 공간을 system call의 entry가 차지하고 있다. 이 pointer값을 이용해 찾아간 interrupt handler는 system call들에 대한 주소들을 저장하는 table sys_call_table을 갖고 있는데, 해당 table 내부에서 sys_fork()에 대한 주소를 찾은 뒤 system call handler가 sys_fork()명령을 실행하도록 명령한다.
System Call 추가
sys_call_table은 실제로 어디에 위치하고 있을까? 운영체제마다 세부 위치는 다르지만, /usr/src/[os kernel version]/arch 밑에 위치한다는 사실은 공통적이다. 만약 OS에 새로운 System Call을 추가하고 싶다면 해당 sys_call_table 파일을 열어 새로운 번호를 추가하는 것이 먼저이다. 이후 실제 해당 함수에 대한 원형을 선언해야 하는데, system call의 원형을 저장하는 header file은 /usr/src/[os kerner version]/arch/.../include/syscalls.h에 위치한다. 실제 함수 body를 정의한 뒤 이를 object file로 compile하면, 해당 object file을 /usr/src/[os kernel version]에 위치시키면 작업이 완료된다. 정리하자면 다음의 4단계를 거친다.
- syscall table에 새로운 함수 등록
- 함수 header
syscalls.h에 추가 - 함수 body가 작성된 C source code file 작성
- C source code file을 컴파일 해 Object file(
.o) 생성 후 kernel 경로에 저장
Context (문맥)
문맥은 크게 3가지로 구분될 수 있다. HW (register) 문맥, system 문맥, memory 문맥이 그 예이다. 실제 task_struct 구조체에서도 struct mm struct *mm으로 memory 문맥을, struct threadstruct로 HW 문맥을 구현했다.
Process 전환
Process 전환
schedule() 함수는 다음 실행할 process의 PCB를 return하는 함수이다. PCB란 Process Control Block으로 os가 process를 추상화한 것이다. linux에서는 PCB가 task_struct type이다. 이렇게 얻어낸 다음 process의 PCB와 현재 실행 중이던 process의 PCB를 switch() 함수에 인자로 넣으면(switch(prev PCB, next PCB)) 문맥 교환이 수행된다. 자세한 단계는 아래와 같이 진행된다.
- 현재 실행 중이던 process의 context를 저장
- 현재 실행 중이던 process의 PCB를 갱신 (상태를 Ready, Block, Sleep, Zombie 등으로 변경)
- PCB를 os의 schedule 정책에 따른 특정 queue로 이동
- os의 schedule 정책에 따라 다음 process를 선택
- 선택된 process의 PCB를 갱신 (상태를 Running으로 전환)
- 선택된 process가 이전 수행에서 사용했던 context를 복원
위에서 정리한 9단계 State를 참고하면, 아래의 경우에 대해 각각의 process 전환 이후의 상태를 특정할 수 있다.
exit()→schedule()→switch(): zombie 상태- I/O →
schedule()→switch(): block 상태 - clock interrupt →
schedule()→switch(): runnable (또는 memory가 부족할 경우 suspend) 상태
Mode Switch vs Process Switch
mode의 전환은 Kernel mode / User mode 사이의 전환을 말한다. mode 전환은 현재 실행 중인 process의 상태 (running, runnable, zombie …)를 바꾸지 않고 수행 가능하다. context를 따로 저장할 필요도 없기 때문에 많은 연산을 요구하지 않는다. 반면 process 전환은 실제 context를 따로 저장 및 교환해야 하기 때문에 mode 전환에 비해 훨씬 더 많은 연산을 요구하게 된다.
Process 전환의 한계
기본적으로 대부분의 os는 중첩 interrupt를 금지한다. 즉, 이미 interrupt가 발생해서 처리 중인 경우에는 그 사이에 발생된 새로운 interrupt에 대해 처리하지 않는다는 것이다.