숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
단기 Scheduling
Scheduling에는 여러 종류가 있다. 장기(long-term) scheduling은 process가 CPU에 의해 실행될 자격을 부여할 지를 결정하는 것이다. 중기(medium-term) scheduling은 process(의 일부)가 Memory에 올라갈 자격을 부여할 지를 결정하는 것이다. 단기(short-term) scheduling은 CPU에 실행될 다음 process를 선택하는 것으로, Dispatcher라고 불린다. 아래에서는 단기 scheduling에 대해서 다룬다.
Scheduling
여러가지 Scheduling 기법에 대해 알아보자. 하지만 여기서 다루는 기법들은 어디까지나 Ideal한 가정 하에 성립하는 것으로 현실에 그대로 적용되기는 불가능에 가깝다. 앞으로 다루는 Scheduling들은 다음의 가정을 따른다.
- 모든 task는 동일한 시간 동안에 실행된다.
- 모든 task는 동일한 시간에 도착한다.
- 모든 task는 시작되면 완료될 때까지 실행된다.
- 모든 task는 CPU만 사용한다. (I/O 배제)
- 모든 task의 실행 시간은 알려져 있다.
preemption vs non-preemption
Scheduling에 대해 알아보기 전에 우선 preemption에 대한 개념을 확실히 정의하고 가는 것이 좋다. preemption이란 이전에도 설명했듯이, 다른 process가 이미 차지하고 있던 CPU를 빼앗는 행위를 뜻한다. non-preemption이라는 것은 preemption의 반댓말(빼앗김)이 아닌, 빼앗기지 않는다는 의미이다. 다시 말해, 자신이 이미 CPU를 차지하고 있고 다른 process에게 넘겨주지 않는다는 것을 non-preemption이라고 한다.
평가 기준
-
Turn around time (반환 시간)
\[T_{turn\_around} = T_{completion} - T_{arrival}\] -
Response time (응답 시간)
\[T_{response} = T_{start}-T_{arrival}\] -
Fairness
얼마나 고르게 여러 process에 cpu를 분배했느냐에 대한 척도이다. 성능과 상충되는 기준이다.
종류
First In First Out (FIFO) / First Come First Service (FCFS)
Queue를 이용한 non-preemption 방식이다. 대기 시간을 기준으로 Scheduling을 수행한다. 예시를 통해 이해해보자.
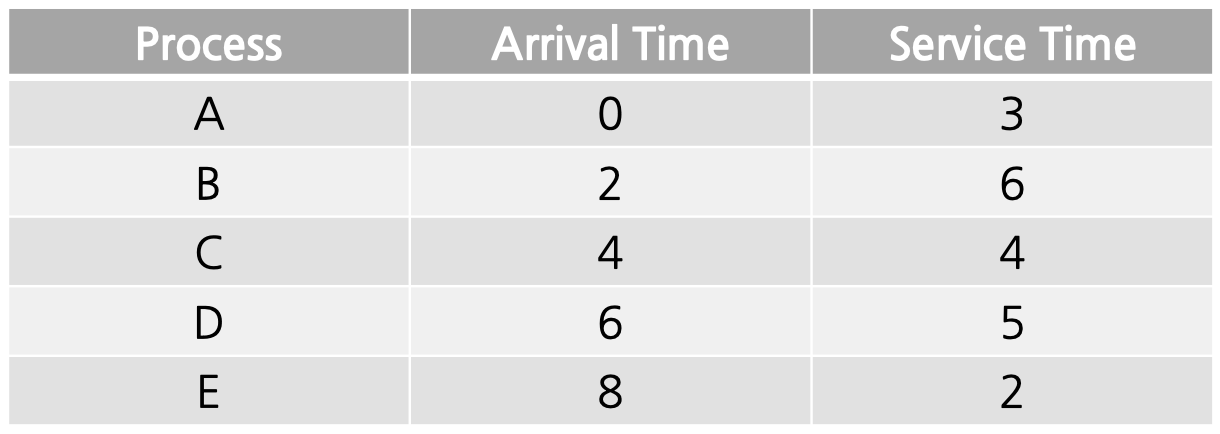
위의 5개의 process가 있다고 가정해보자. Arrival Time과 Service Time이 주어졌다. FIFO Scheduling을 수행하면 아래와 같이 실행되게 된다.
평균 반환 시간을 계산해보자.
\[A's\ T_{arround\_time} : 3-0 = 3\] \[B's\ T_{arround\_time} : 9-2 = 7\] \[C's\ T_{arround\_time} : 13-4 = 9\] \[D's\ T_{arround\_time} : 18-6 = 12\] \[E's\ T_{arround\_time} : 20-8 = 12\] \[Avr\ T_{arround\_time}=\frac{3+7+9+12+12}{5}\\=\frac{43}{5}=8.6\]평균 응답 시간을 계산해보자.
\[A's\ T_{response\_time} : 0-0 = 0\] \[B's\ T_{response\_time} : 3-2=1\] \[C's\ T_{response\_time} : 9-4=5\] \[D's\ T_{response\_time} : 13-6=7\] \[E's\ T_{response\_time} : 18-8=10\] \[Avr\ T_{arround\_time}=\frac{0+1+5+7+10}{5}\\=\frac{23}{5}=4.6\]FIFO 방식은 Convoy Effect (홍위병 효과)라는 치명적인 단점이 존재한다. E를 예시로 들어볼 수 있는데, 실행 시간이 2로 매우 짧음에도 불구하고 늦게 들어왔다는 이유만으로 가장 나중에 실행되어 평균 반환, 응답 시간이 길어지게 되었다.
실생활에서의 예시를 들어보자. 편의점에 손님이 많아 카운터의 줄이 긴 상태이다. 자신은 음료수 하나만을 구매하려고 줄을 섰는데 바로 앞의 사람은 무려 10만원 어치의 상품을 결제 중이어서 한참을 기다리는 상황이다. “나는 10초면 계산이 끝나는데 먼저 양보해줬으면 좋겠다”는 생각이 들 것이다. 이처럼 매우 짧은 시간이 소요되는 task임에도 조금이라도 늦게 시작됐다는 이유만으로 매우 긴 시간 대기하는 상황을 Convoy Effect라고 한다.
Shortest Job First (SJF) / Shortest Process Next (SPN)
SJF 방식은 FIFO와 동일하게 non-preemption 방식이다. 그런데 먼저 들어온 순서보다는 task의 소요 시간을 기준으로 Scheduling을 수행한다.
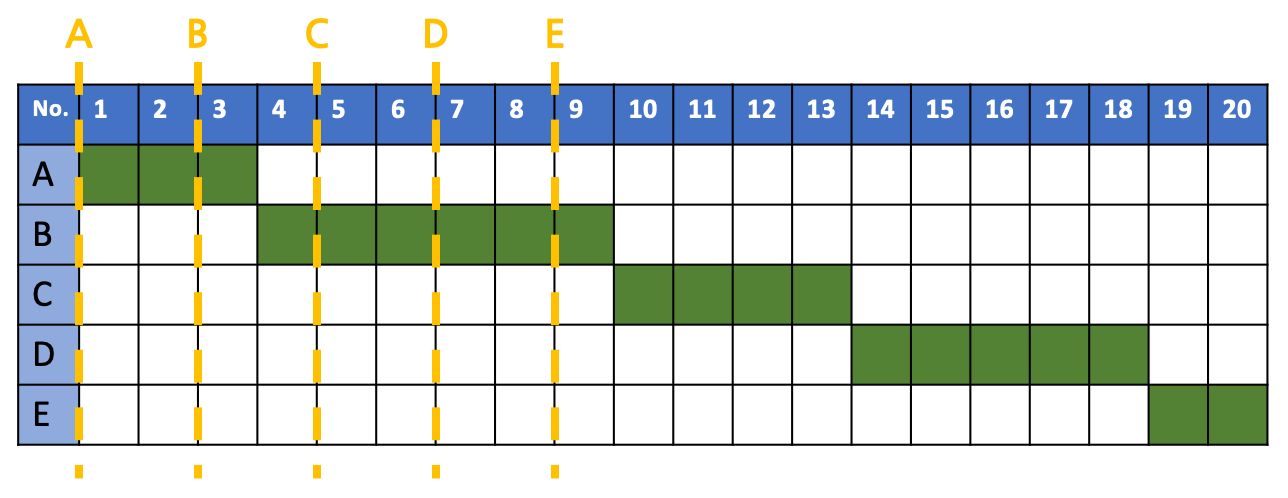
평균 반환 시간을 계산해보자.
\[A's\ T_{arround\_time} : 3-0 = 3\] \[B's\ T_{arround\_time} : 9-2 = 7\] \[C's\ T_{arround\_time} : 15-4 = 11\] \[D's\ T_{arround\_time} : 20-6 = 14\] \[E's\ T_{arround\_time} : 11-8 = 3\] \[Avr\ T_{arround\_time}=\frac{3+7+11+14+3}{5}\\=\frac{38}{5}=7.6\]평균 응답 시간을 계산해보자.
\[A's\ T_{response\_time} : 0-0 = 0\] \[B's\ T_{response\_time} : 3-2=1\] \[C's\ T_{response\_time} : 11-4=7\] \[D's\ T_{response\_time} : 15-6=9\] \[E's\ T_{response\_time} : 9-8=1\] \[Avr\ T_{arround\_time}=\frac{0+1+7+9+1}{5}\\=\frac{18}{5}=3.6\]평균 응답, 반환 시간이 FIFO에 비해 줄어든 것을 확인할 수 있다. Convey Effect를 해결한 것이다. 구체적인 예시로, B가 끝난 직후의 상황에서 C나 D 대신 가장 실행 시간이 짧은 E가 선택됨으로써 E의 평균 반환, 응답 시간이 FIFO에 비해 획기적으로 줄어들게 되었다.
하지만 SJF scheduling도 Starvation(기아) Effect가 발생할 수 있는데, 이 역시 실생활의 예시로 이해해보자. 아까의 편의점 상황을 다시 떠올려 보자. 대신 이번에는 내가 10만원 어치의 구매를 한 고객이다. 계산대 앞에 섰으나 뒤에 금방 계산이 끝나는 사람이 있기에 먼저 양보를 했다. 그러나 그 뒤에 사람들도 모두 자신 역시 금방 계산이 끝난다며 먼저 계산을 하게 되었다. 결국 자신은 여러 사람의 계산이 모두 끝나기를 한참이나 기다린 뒤에 본인의 계산을 할 수 있게 되었다. 이처럼 짧은 시간이 소요되는 task들을 모두 기다리다가 무한정 기다리게 되는 상황을 Starvation Effect라고 한다.
Shortest Time-to-Completion First (STCF) / Shortest Remaining Time (SRT)
STCF는 위의 scheduling들과는 달리 preemption 방식이다. 즉, 이미 작업을 수행하던 process가 중단될 수 있다는 것이다. 새로운 process가 들어오게 될 경우, 현재 수행 중인 process의 잔여 시간보다 새로 들어온 process의 수행 시간이 짧을 경우에 preemption을 하게 된다.
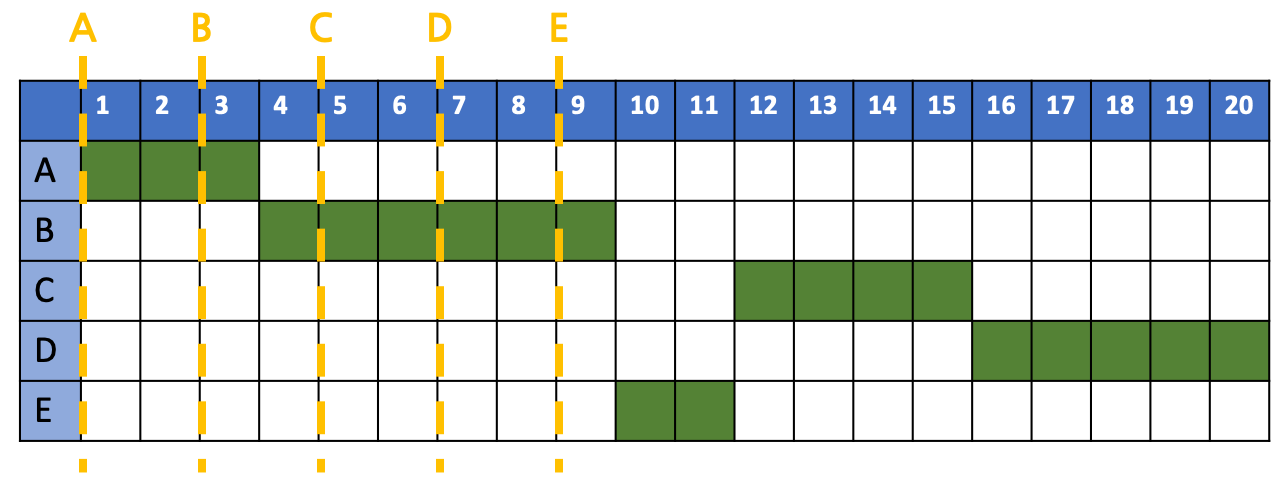
평균 반환 시간을 계산해보자.
\[A's\ T_{arround\_time} : 3-0 = 3\] \[B's\ T_{arround\_time} : 15-2 = 13\] \[C's\ T_{arround\_time} : 8-4 = 4\] \[D's\ T_{arround\_time} : 20-6 = 14\] \[E's\ T_{arround\_time} : 10-8 = 2\] \[Avr\ T_{arround\_time}=\frac{3+13+4+14+2}{5}\\=\frac{36}{5}=7.2\]평균 응답 시간을 계산해보자.
\[A's\ T_{response\_time} : 0-0 = 0\] \[B's\ T_{response\_time} : 3-2=1\] \[C's\ T_{response\_time} : 4-4=0\] \[D's\ T_{response\_time} : 15-6=9\] \[E's\ T_{response\_time} : 8-8=0\] \[Avr\ T_{arround\_time}=\frac{0+1+0+9+0}{5}\\=\frac{10}{5}=2\]C가 가장 큰 혜택을 보게 되었다. 4time이 지난 시점에 C가 새로 들어오게 되는데, 이미 수행중이던 B의 잔여 시간은 5초인 반면 C의 전체 수행 시간은 4초이기에 수행 중이던 B에게서 preemption을 해 C가 수행되게 된다. 하지만 STCF 역시 Starvation Effect를 해결하지는 못한다. 전체 수행 시간이 긴 process의 경우 계속 새로 들어온 작업들에 밀려 수행될 수 없게 된다.
Highest Response Ratio Next (HRRN)
HRNN은 다시 non-preemption 방식이다. 대신 이전의 일률적인 기준 (FIFO: 대기 시간, SJF: 수행 시간)이 아닌 두 기준을 결합한 수식을 사용하기로 했다.
\[(T_{wait}+T_{service})/T_{service}\]대기 시간과 실행 시간을 더한 값을 대기 시간으로 나눈 값이 큰 process를 먼저 선택한다.
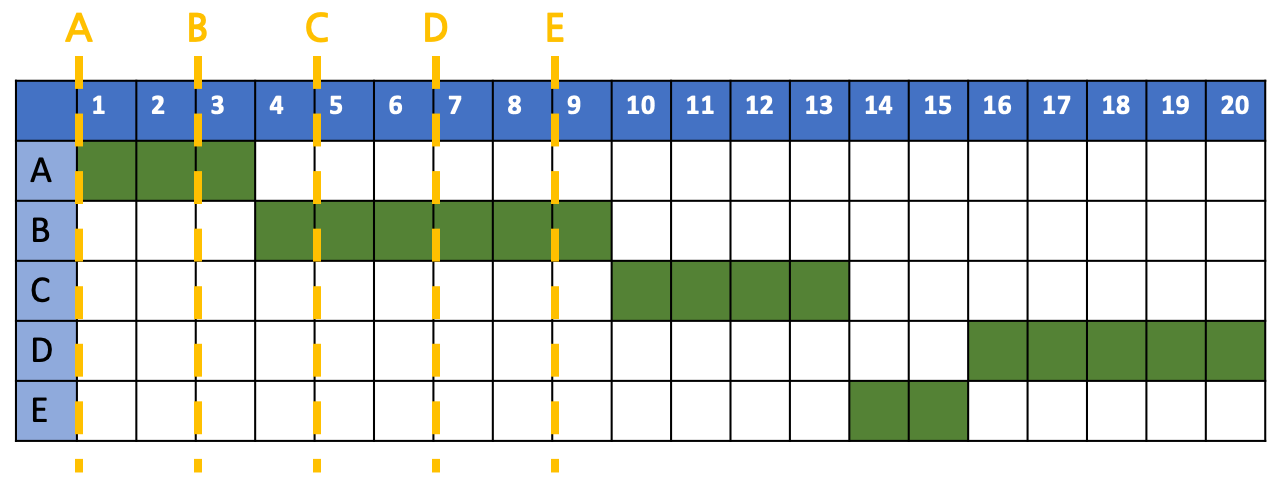
평균 반환 시간을 계산해보자.
\[A's\ T_{arround\_time} : 3-0 = 3\] \[B's\ T_{arround\_time} : 9-2 = 11\] \[C's\ T_{arround\_time} : 13-4 = 9\] \[D's\ T_{arround\_time} : 20-6 = 14\] \[E's\ T_{arround\_time} : 15-8 = 7\] \[Avr\ T_{arround\_time}=\frac{3+11+9+14+7}{5}\\=\frac{44}{5}=8.8\]평균 응답 시간을 계산해보자.
\[A's\ T_{response\_time} : 0-0 = 0\] \[B's\ T_{response\_time} : 3-2=1\] \[C's\ T_{response\_time} : 9-4=0\] \[D's\ T_{response\_time} : 15-6=9\] \[E's\ T_{response\_time} : 13-8=5\] \[Avr\ T_{arround\_time}=\frac{0+1+0+9+5}{5}\\=\frac{15}{5}=3\]B가 수행이 끝난 9time 직후를 보면 C, D, E 중 선택을 하는 상황이다. 각각의 time을 계산해보자.
\[C: \frac{(9-4)+4}{4}=\frac{9}{4}=2.25\] \[D: \frac{(9-6)+5}{5}=\frac{8}{5}=1.6\] \[E: \frac{(9-8)+2}{2}=\frac{3}{2}=1.5\]이 중 가장 큰 값인 C를 선택하게 된다. SJF에서는 C가 E에 밀려 더 나중에 수행됐다면, 여기서는 C가 E보다 대기 시간에서의 보정을 받아 더 먼저 수행된 것이다.
Round Robin (RR) / Time Slicing
preemption 방식이다. 일정 시간마다 서로 돌아가면서 공정하게 scheduling을 하고자 함이다. 이 때 들어온 순서대로 Queue에 넣고, Queue에서 pop을 해 새로운 process를 선택한다. 만약 수행이 끝났음에도 아직 남아있는 작업이 있다면 다시 Queue에 삽입한다. 가장 중요한 변수는 Time Slicing의 길이인데 만약 무한대에 수렴할 경우, non-preemption과 다를 바 없어지고, 0에 수렴할 경우 context switch 수행 횟수가 급격히 늘어나 overhead가 발생할 것이다. 아래의 예시는 Time Slicing의 길이가 1인 경우이다.
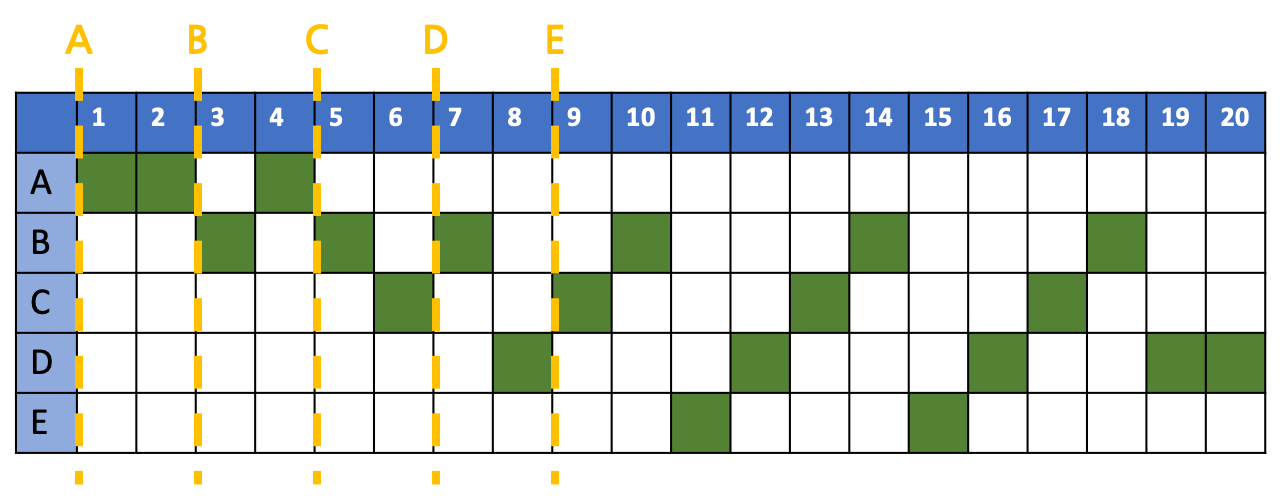
평균 반환 시간을 계산해보자.
\[A's\ T_{arround\_time} : 4-0 = 4\] \[B's\ T_{arround\_time} : 18-2 = 16\] \[C's\ T_{arround\_time} : 17-4 = 13\] \[D's\ T_{arround\_time} : 20-6 = 14\] \[E's\ T_{arround\_time} : 15-8 = 7\] \[Avr\ T_{arround\_time}=\frac{4+16+13+14+7}{5}\\=\frac{54}{5}=10.8\]평균 응답 시간을 계산해보자.
\[A's\ T_{response\_time} : 0-0 = 0\] \[B's\ T_{response\_time} : 2-2=0\] \[C's\ T_{response\_time} : 5-4=1\] \[D's\ T_{response\_time} : 7-6=1\] \[E's\ T_{response\_time} : 10-8=2\] \[Avr\ T_{arround\_time}=\frac{0+0+1+1+2}{5}\\=\frac{4}{5}=0.8\]MLFQ (Multi-level Feedback Queue)
RR에서 좀 더 발전해 Time Slicing의 길이가 다른 Queue를 여러 개 운용하는 것이다.
Scheduling: MLFQ(Multi Level Feedback Queue)
Incorporating I /O
I/O를 고려하는 scheduling이다. I/O 수행 중에는 CPU를 사용하지 않는다. 따라서 해당 기간 동안에 CPU를 휴식시키지 않고, 다른 process를 수행하도록 하는 것이다.
성능 비교
| Scheduling | 선택 함수 | preemption | 응답 시간 | 문맥 교환 비용 | 유리한 process | Starvation |
|---|---|---|---|---|---|---|
| FIFO/FCFS | max[w] | non-preemption | 길 수 있음 | 최소 | 연산 많은 process | X |
| SJF/SPN | min[s] | non-preemption | 연산 적을수록 짧음 | 커질 수 있음 | 짧은 process | O |
| STCF/SRT | min[s-e] | preemption | 짧음 | 커질 수 있음 | 연산 적은 process | O |
| HRRN | max((w+s)/s) | non-preemption | 짧음 | 커질 수 있음 | 다소 공정 | X |
| RR | 상수 | preemption | 연산 적을수록 짧음 | 최대 | 모두에게 공정 | X |