숭실대학교 컴퓨터학부 홍지만 교수님의 2020-2학기 운영체제 강의를 정리 및 재구성했다.
RR과 MLFQ
Round Robin 기법은 평균 응답 시간은 최소화시켰지만, 평균 반환 시간은 최악이라는 점에서 한계가 있었다. 물론 평균 응답 시간이 짧기 때문에 사용자가 속도가 빠른 시스템으로 인지하도록 착각을 유도할 수 있었다. 하지만 짧은 task에 대해서도 slicing을 수행해 여러 번 나눠 작업을 수행하며 오랜 시간이 지난 후에 최종적으로 작업이 종료되기에 짧은 task에 있어서 너무나 불리한 정책이었다. MLFQ는 이러한 RR의 한계점을 극복하기 위해 고안해낸 방법이다. RR의 장점인 짧은 평균 응답 시간은 유지하면서, RR의 단점인 짧은 task의 불리함을 해결하자는 것이다. RR에서는 Queue를 1개만 운용했다면, MLFQ는 다양한 Time Quantum을 가지는 여러 Queue를 동시에 운용한다. 각각의 Queue들은 RR의 Queue와 동일한 방식으로 작동한다.
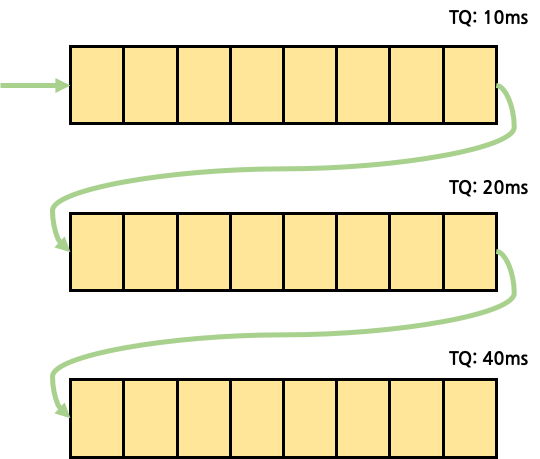
여러 개의 Queue는 상단에서 하단으로 내려갈수록 Time Quantum은 길어지고, 이는 당연히 process가 CPU를 점유했을 시 한 번에 실행되는 시간이 길어짐을 뜻한다. 반면 상단에서 하단 Queue로 내려갈수록 우선 순위는 떨어져 점유 가능성은 낮아진다. 더 정확히는, 하단에 있는 Queue가 Pop되려면 해당 Queue의 상단에 있는 모든 Queue가 empty 상태여야만 한다.
SJF, STCF와 같은 정책을 다시 생각해보자. 짧은 시간을 갖는 task에 대해서 우선순위를 부여하려고 하는 방식이었다. 하지만 CPU의 입장에서 처음 마주하는 process가 들어올 때 해당 process의 총 작업 시간이 얼마인지는 알 수 있는 방법이 없다. 따라서 SJF와 STCF와 같은 정책은 현실에서는 적용하기 불가능하다. MLFQ는 짧은 task들이 불리한 RR의 단점을 해결하기 위한 것이 목적이었다. MLFQ는 process의 실행 시간을 알 수 있는 방법이 없기 때문에 어디까지나 process의 실행 시간을 유추하게 된다. 우선은 새로 들어오는 모든 process가 짧은 process라고 가정하고 가장 TQ가 짧은 최상단 Queue에 push한다. 만약 첫번째 Queue에서 process가 끝나지 않았다면 아래에 있는 Queue에 push하게 된다. 우선 순위를 낮추되, 한 번 점유하면 오래 실행되도록 하는 것이다. 이는 해당 process가 실행 시간이 좀 더 길 것이라고 유추한다는 의미이다. 만약 2번째 Queue에서도 process가 종료되지 않았다면 3번째 Queue에 push하게 된다. 3번째 Queue는 1,2번째 Queue가 empty일 때에만 pop이 되기 때문에 우선 순위는 많이 떨어지지만, 한 번 점유하게 되면 오랜 시간 실행되게 된다. 이렇듯 각 process에게 고정적인 우선순위를 부여하는 기존의 scheduling 정책과 반대로 MLFQ는 동적으로 우선순위를 결정하게 된다.
MLFQ Rule
MLFQ가 작동하는 규칙에 대해 자세하게 살펴보자. 다음과 같은 5개의 규칙을 따른다.
- 우선순위가 더 높은 (더 상단의 Queue에 위치한) task를 먼저 수행한다.
- 우선순위가 같은 (같은 Queue에 위치한) task 중에서는 먼저 들어온 task를 수행한다.
- 처음 실행되는 task에 대해서는 가장 높은 우선순위를 부여한다(최상단 Queue에 push한다).
- TQ를 모두 소모하면, 우선순위가 낮아진다(아래의 Queue에 push한다).
- TQ를 모두 소모하기 전에 CPU 점유를 해제하면, 같은 우선순위를 유지한다(같은 Queue에 push한다).
MLFQ의 한계
기본 상태의 MLFQ는 크게 3개의 한계점이 존재한다.
-
기아 Starvation 발생 가능성
실행 시간이 길어 우선순위가 낮아진 task는 계속 신규 task가 들어오게 될 경우 기아 상태에 빠지게 된다.
-
시간에 따라 process의 특성이 변하더라도 한 번 내려간 우선순위 조정 불가
I/O Bound(CPU 연산보다 I/O 위주)인 task는 상단 Queue에 위치한다. 반면 CPU Bound인 task는 하단 Queue에 위치한다. 하지만 CPU Bound에서 I/O Bound로 process의 특성이 변경될 경우, 한 번 내려간 우선순위는 다시 올라가지 않는다. 따라서 해당 process는 제대로 실행되지 못한다.
-
무의미한 I/O를 빈번히 발생시켜 우선순위를 강제로 유지 (gaming)
Time Quantum이 끝나기 전에 CPU 점유를 해제하면 우선순위가 유지된다는 점을 악용해 매 Time Quantum이 끝나기 직전에 무의미한 I/O를 지속적으로 발생시키게 되면 해당 task는 계속 높은 우선순위를 유지하게 된다.
MLFQ 개선
위의 한계들을 극복하기 위해 새로운 rule을 도입할 수 있다.
-
일정 시간 \(S\)가 지나면, 모든 task들의 우선순위를 초기화한다(모든 task들을 최상위 Queue에 push한다).
이러한 작업을 Boosting이라고 부른다. MLFQ의 1, 2번 문제를 해결할 수 있다. \(S\)는 hyperparameter로, heuristic하게 결정해야 하는 값이다. \(S\)를 너무 큰 값으로 지정하게 되면 Starvation이 여전히 발생하게 되고, 너무 작은 값으로 지정하게 되면 짧은 task(I/O Bound 또는 대화형 task)가 불리해진다.
-
CPU 사용 시간의 합이 TQ에 다다를 경우 우선순위를 낮춘다(아래의 Queue에 push한다).
해당 Queue 내에서 사용한 총 CPU time을 보관해 TQ에 다다르게 될 경우 그동안 CPU를 몇 번 양도했는지와 관계없이 우선 순위를 낮춰 다음 Queue에 push한다. 이를 통해 MLFQ의 3번 문제를 해결할 수 있다.
MLFQ Tuning
MLFQ에는 여러 hyperparameter들이 있다. 가장 대표적으로 Queue의 개수, 각 Queue의 Time Quantum, boosting에서의 \(S\)등이 있다. 이러한 값들은 모두 heuristic하게 결정해야 한다.