Paper Info
Submit Date: Sep, 26, 2019
Introduction
최근 NLP에서 주로 사용되는 BERT 기반 pre-train model들은 HW의 제약으로 인해 크게 2가지의 문제점에 직면했다. memory limitation과 communication overhead이다. 기존의 연구들은 model parallelization 및 향상된 memory managerment을 적용해 memory limitation 문제는 해결했지만, communication overhead까지 해결하지는 못했다. 본 논문에서는 위의 두 문제를 모두 해결하기 위한 2가지 parameter reduction 기법을 제안한다. factorized embedding parameterization과 cross-layer parameter sharing이다. 그 결과로 만들어진 ALBERT는 BERT-large model 대비 18배 적은 parameter들로 1.7배 빠른 학습 속도를 보인다. 이에 더해 NSP loss를 대채하는 SOP(sentence-order prediction) loss라는 self-supervised loss를 새로 도입해 더 많은 성능 향상을 꾀했다. 그 결과, GLUE, SQuAD, RACE 등의 NLU benchmark에서 SOTA를 달성했다. 특히 RACE에서의 accuracy는 89.4%로 매우 높은 수치를 보였다.
The Elements of ALBERT
Model architecture choices
ALBERT는 기본적인 BERT 구조를 따른다. 차이점은 activation function으로 GELU를 채택한 것이다. 때문에 BERT 계열 model에서 관례적으로 사용해왔던 notation들을 그대로 사용한다. \(E\)는 embedding size, \(L\)은 encoder layer 개수, \(H\)는 hidden size이다. feed-forward size를 \(4H\)로 설정했고, attention head 개수는 \(h=H/64\)이다. Transformer notation에 따르면 \(d_k \times h = d_{model}\)이었는데, \(E=d_{model}\)이므로 ALBERT의 \(d_k\)는 64라는 것을 알 수 있다.
Factorized embedding parameterization
기존의 BERT-like model들은 대개 WordPiece embeddign size와 hidden layer size를 같게 채택했다 (\(E\equiv H\)). 하지만 이는 아래의 두가지 관점에서 적절하지 않은 정책이다.
modeling 관점에서 봤을 때, WordPiece embedding은 context-independent한 representation을 저장한다. 반면 hidden layer embedding은 context-dependent한 representation을 저장한다. 때문에 두 embedding의 size가 같아야만 할 필요는 없다. 또한 두 embedding size를 같게 해야만 한다는 조건은 전체 parameter를 좀 더 효율적으로 사용하지 못하도록 하는 제약이 되기도 한다.
paractical 관점에서 봤을 때, 최근의 NLP 경향은 vocabulary size \(V\)를 키우고자 한다. 실제로 본 논문을 포함한 대부분의 BERT-like model들은 \(V=30,000\)을 채택하고 있다. 그런데 \(E \equiv H\)인 상황에서 \(V\)를 증가시키게 될 경우 embedding matrix의 size가 비약적으로 커지게 된다. embeding matrix는 \(V \times E\)의 shape를 갖기 때문이다. 극소수를 제외한 대부분의 vocabulary는 거의 사용되지 않는다는 점에서 이는 크나큰 낭비라고 할 수 있다.
때문에 ALBERT는 embedding matrix를 2개의 작은 matrix로 decompose하는 방식을 채택했다. 기존의 embedding 방식은 \(V\) dimension을 갖는 one-hot vector를 바로 \(E\) dimension을 갖는 embedding space에 project했다. ALBERT는 이를 두 단계로 나눠 우선 \(E\) dimension을 갖는 embedding space에 project하고, 그 결과로 도출된 vector를 \(H\) dimension을 갖는 hidden space에 project한다. 기존의 embedding 방식에서의 #parameters는 \(V \times H\)였다면, 본 논문에서 제시하는 Factorized embedding parameterization의 #parameters는 \(V \times E + E \times H\)로 큰 차이를 보이는 것을 확인할 수 있다. \(H\)가 증가할수록 #parameters의 차이는 더 커지게 된다.
Cross-layer parameter sharing
기존의 BERT parameter sharing에 관련된 연구는 대개 FFN의 parameters를 sharing하거나, attention parameters를 sharing하는 식으로 진행되어 왔다. 하지만 ALBERT는 모든 parameters를 sharing한다. 때문에 #parameters가 비약적으로 감소한다.
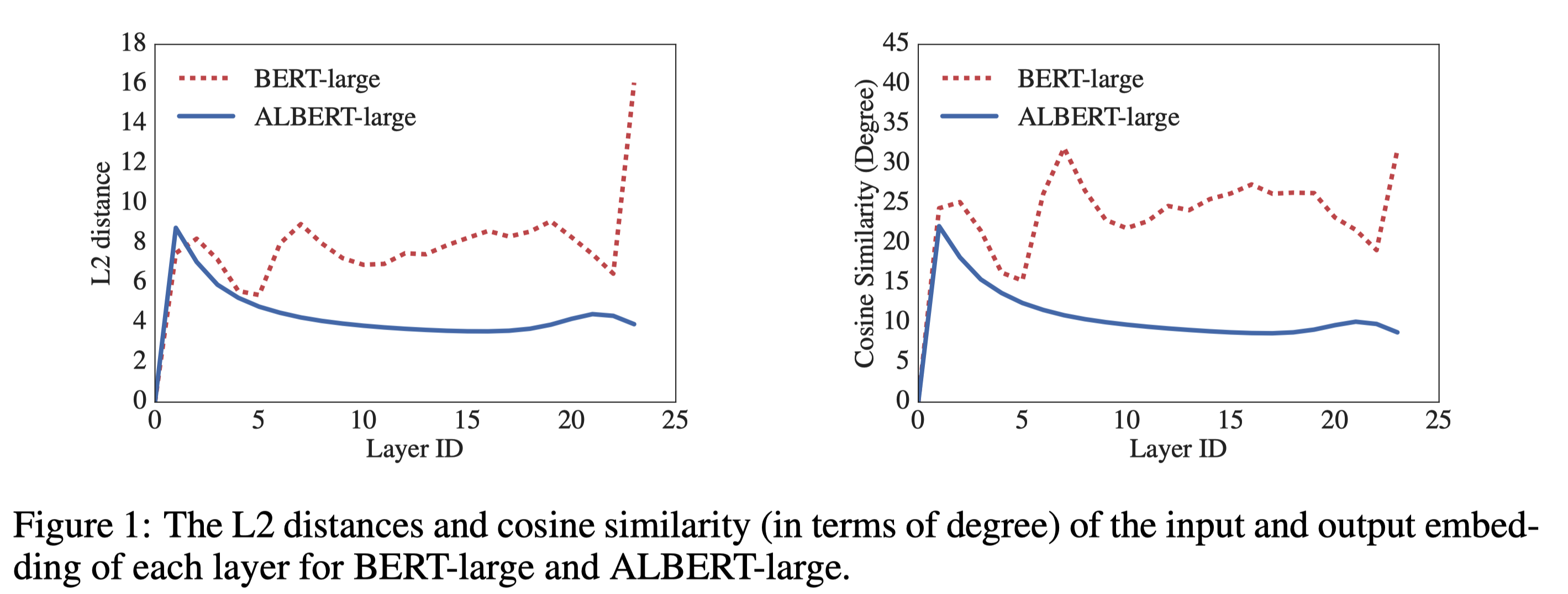
BERT-large와 ALBERT-large를 비교하는 실험을 진행했다. 두 model의 #layers는 24로 동일하기에 전체 layer들의 input embedding과 output embedding 사이의 L2 distance, cosine similarity를 비교해 그래프로 나타냈다. 그 결과 BERT-large는 input과 output 사이의 차이의 변동이 layer마다 큰 반면, ALBERT는 안정적으로 점차 수렴해나가는 것을 확인할 수 있었다. input과 output 사이의 차이가 조금씩 수렴해나간다는 것은 각 layer들 중 특정 layer들에게만 과도하게 영향을 받지 않고, 여러 layer들이 균등하게 영향을 미친다고 볼 수 있기 때문에 더 stable한 training이 가능하다.
Inter-sentence coherence loss
original BERT model은 MLM loss와 NSP loss를 사용했다. NSP는 inter-sentence modeling을 위한 학습 방법인데, 두 sentence가 주어졌을 때 두 sentence가 같은 document에서 나왔을 경우 positive, 다른 documents에서 나왔을 경우 negative인 binary classification task이다. 이러한 inter-sentence modeling을 통해 NLI(Natural Language Inference) 등의 downstream task에서 성능 향상을 이끌어낼 수 있지만, NSP 자체가 비효율적이라는 결론은 이미 많은 연구를 통해서 밝혀졌다.
NSP가 비효율적인 이유를 정리하자면 다음과 같다. NSP는 topic prediction과 coherence prediction을 결합한 task이다. 그런데 두 prediction의 난이도에는 큰 차이가 있다. topic prediction이 coherence prediction보다 훨씬 난이도가 낮은 task이다. 떄문에 NSP는 두 prediction을 모두 학습하기 보다는 topic prediction에 과도하게 의존하게 된다. 하지만 topic prediction은 inter-sentence modeling이라고 보기 힘들기 때문에 결국 MLM만으로 대체가 가능한 것이다.
때문에 ALBERT는 NSP를 대신할 inter-sentence modeling을 찾았고, 그 결과 coherence prediction에만 집중하는 task를 고안해냈다. SOP(Sentence-Order Prediction)이다. SOP는 NSP와 동일하게 binary classification인데, 같은 document에서 나온 두 sentence가 서로 올바른 문장 순서로 등장했을 때 positive, swap되어 나왔을 때 negative이다. ALBERT는 이러한 SOP를 통해 inter-sentence한 downstream task에서 큰 성능 향상을 이뤄낼 수 있었다.
Model setup

위에서 언급한 original BERT와의 차이점 때문에 ALBERT는 original BERT보다 #parameters가 압도적으로 적다. ALBERT-large는 BERT-large 대비 18배 적은 #parameters를 갖는다. 가장 #parameters가 큰 ALBERT-xxlarge 역시 BERT-large 대비해서는 70%의 #parameters이다.
Experimental Results
Experimental setup
original BERT와 동일하게 BookCorpus, English Wikipedia data로 pretrain을 진행했다. sequence의 최대 길이도 동일하게 512로 제한했고, vocabulary size \(V\)는 30,000으로 지정했다. tokenizer는 SentencePiece를 사용했다. MLM에서는 \(n\)-gram을 사용했는데 이 때 \(n\)은 3 이하의 random한 값으로 지정했다. batch size는 4096, optimzer는 LAMB를 사용했고, learing rate는 0.00176이다. 전체 125,000 step을 학습시켰다.
Evaluation benchmarks
GLUE(General Language Understanding Evaluation), SQuAD(Stanford Question Answering Dataset), RACE(ReAding Comprehension from Examinations) 3가지 benchmark를 사용했다.
Overall comparision between BERT and ALBERT
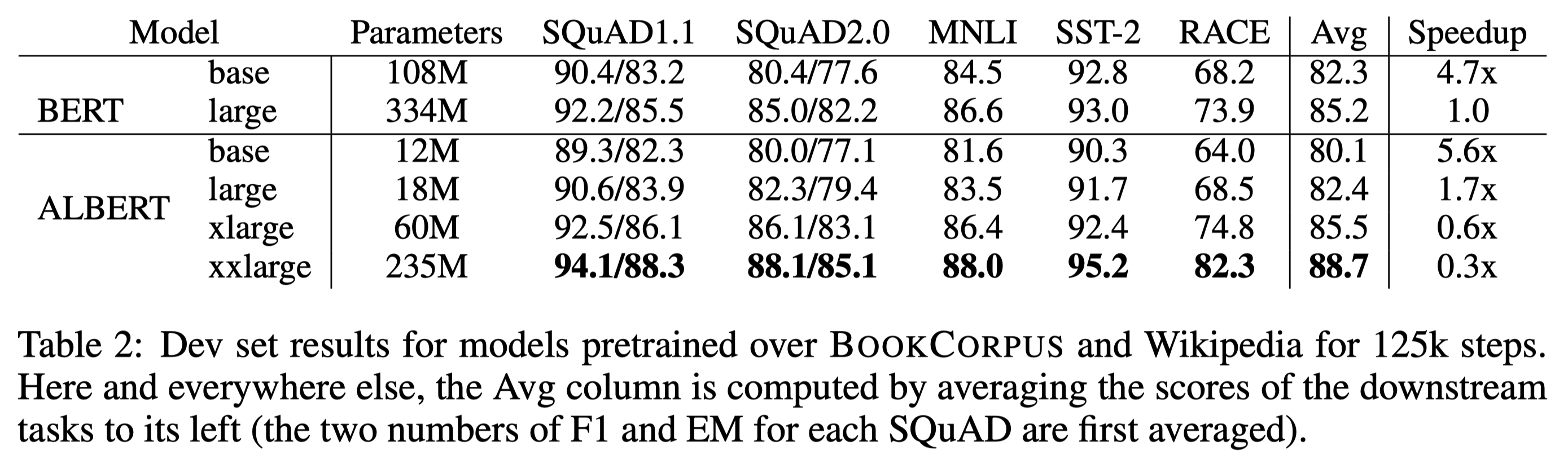
ALBERT-xxlarge model은 BERT-large model의 70%의 #parameters만으로도 모든 downstream task에서 더 좋은 성능을 보였다. Speedup은 training time을 의미하는데, ALBERT-large는 BERT-large보다 1.7배 빠른 학습 속도를 보인 반면, ALBERT-xxlarge는 대략 3배 느린 학습 속도를 보였다.
Factorized embedding parameterization
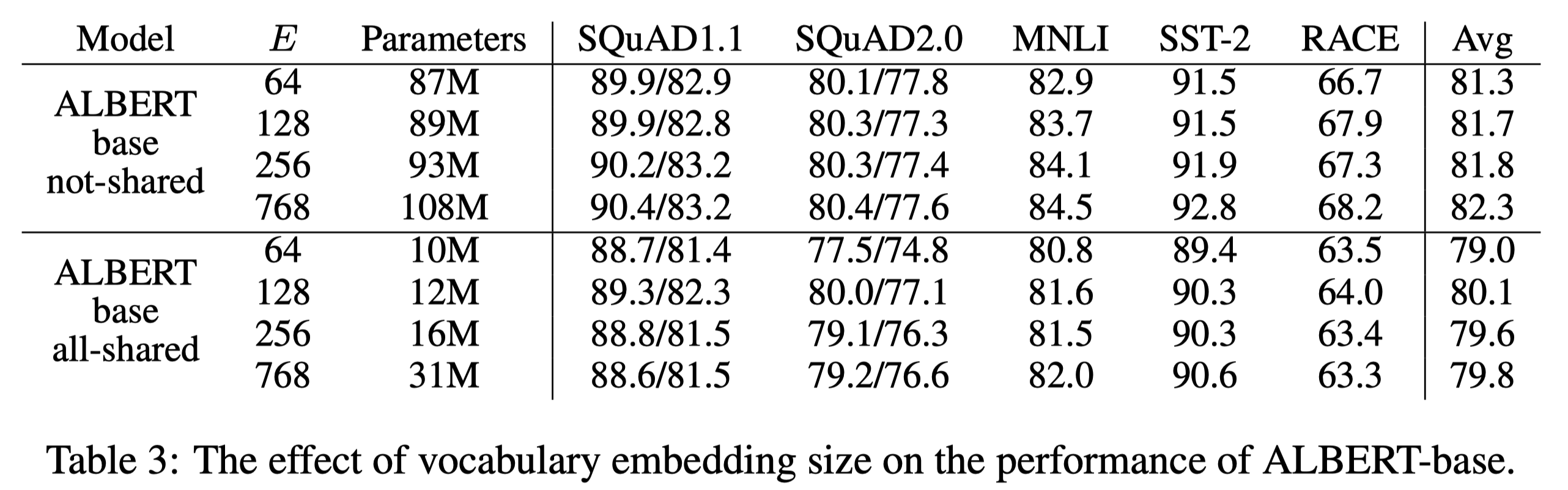
parameter sharing을 하지 않는 BERT-style과 parameter sharing을 수행하는 ALBERT-style을 비교하는 실험을 진행했다. 그 결과 parameter sharing이 없는 경우에는 embedding size와 성능이 비례하는 결과를 보였다. 반면 parameter sharing을 수행하는 경우에 있어서는 embedding size와 성능이 비례하지 않고, embedding size가 128일 때에 가장 좋은 성능을 달성했다. 떄문에 모든 ALBERT model에서는 \(E=128\)을 채택했다.
Cross-layer parameter sharing
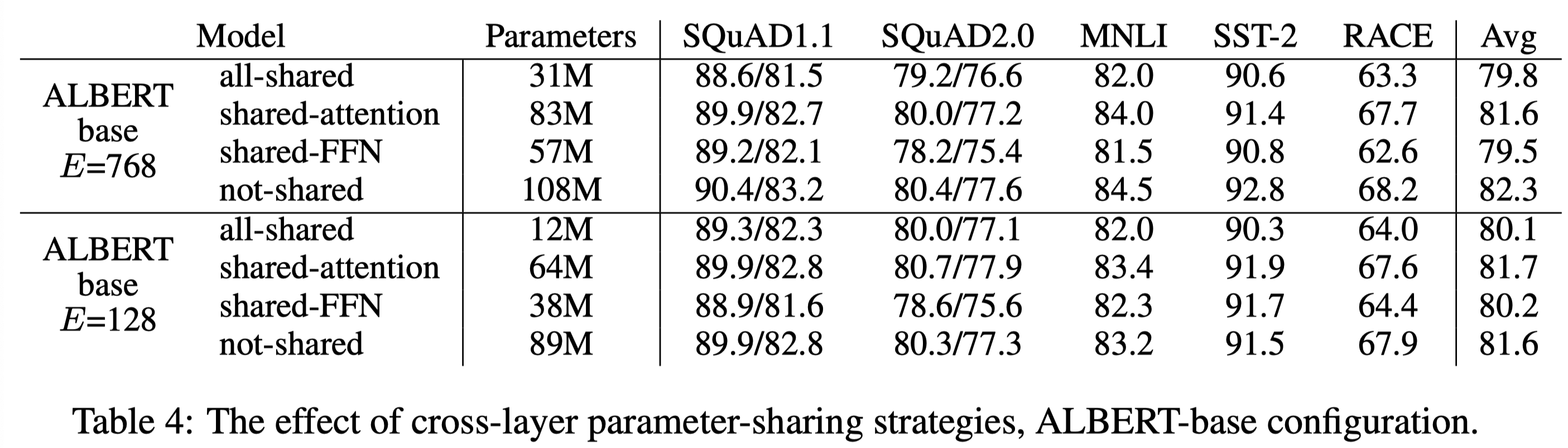
\(E=768\)과 \(E=128\)인 경우에 대해서 parameter sharing을 각각 다르게 적용해 그 영향을 실험했다. 그 결과, 모든 parameters를 sharing한 경우 \(E\)에 상관없이 항상 성능 하락이 있었다. 다만 \(E=128\)인 경우에는 하락이 평균 1.5 일어난 반면, \(E=768\)인 경우에는 하락이 평균 2.5로 차이가 있었다. 또한 attention parameters보다 FFN parameters의 sharing이 더 큰 성능 하락을 유발한다는 것 역시 확인할 수 있었다.
이 외에도 여러 따른 parameter sharing을 실험했는데, 대표적으로 \(L\)개의 layers를 \(M\) size를 갖는 \(N\) group으로 나누는 것이다(\(L = M \times N\)). 하지만 이 경우에는 \(M\)이 감소할수록 성능이 향상된다는 당연한 결론이 도출되었다. \(M\)이 감소하면 당연히 #parameters는 증가할 것이기 떄문에 결국 #parameters와 성능은 trade-off 관계라는 것을 확인할 수 있었다. 결론적으로 ALBERT에서는 모든 layer에 대해 동일하게 all parameter sharing을 하는 정책을 채택했다.
Sentence order prediction (SOP)

SOP의 효과를 측정하는 실험을 진행했다. None은 inter-sentence loss를 아에 사용하지 않고 MLM만 수행하는 경우(XLNet, RoBERTa 등)를 의미하고, NSP는 MLM + NSP를 수행하는 경우(original BERT 등), SOP는 MLM + SOP를 사용하는 ALBERT의 경우이다.
NSP를 수행했을 경우의 SOP accuracy를 주목해보자. 52.0%은 SOP가 binary classification이라는 점을 감안했을 때 사실상 학습이 되지 않은 것이다. 이는 NSP나 SOP를 모두 수행하지 않는 None에서 SOP의 accuracy가 53.3%라는 것을 보면 확실히 알 수 있다. 즉, NSP는 topic prediction만을 학습할 뿐 coherence prediction은 전혀 학습하지 못한 것이다.
반면 SOP를 수행했을 경우 NSP에 대한 accuracy를 보면 78.9%로 높은 수치를 보인다. 즉 SOP는 coherence prediction을 제대로 학습해 이를 NSP에 활용했다는 것을 알 수 있다.
결론적으로 SOP는 모든 downstream task에서 성능 향상을 발생시켰으며 평균적으로 1%의 성능 향상이 있었다.
What if we train for the same amount of time?

Table2에서는 각 model들의 pre-training time을 비교했다. BERT-large는 ALBERT-xxlarge보다 3.17배 빠른 pre-train 속도를 보인다는 것을 확인할 수 있었다. 일반적인 경우 training time이 길 수록 더 좋은 성능을 보이기 때문에 두 model을 같은 시간 동안 pre-train 시킨 후 성능을 비교해보고자 했다. BERT-large는 400k steps pre-training을 수행했고, 이 때 34시간이 소요되었다. ALBERT-xxlarge는 125k steps pre-training을 수행했고, 이 때 32시간이 소요되었다. 그 결과 ALBERT-xxlarge가 downstream task에서 평균적으로 1.5% 높은 성능을 보였고, 특히 RACE에서는 5%에 가까운 차이를 보였다.
Additional training data and dropout effects

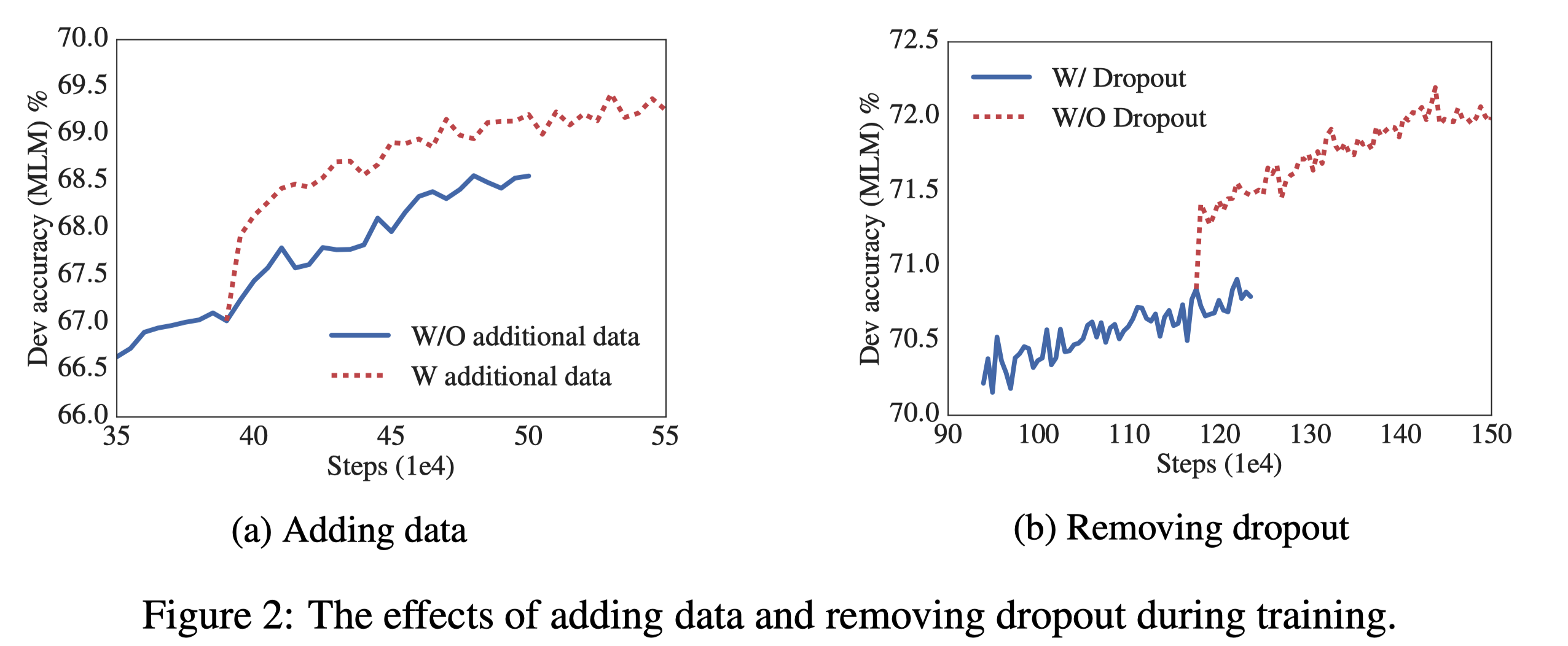
pre-train 단계에서 추가적인 dataset을 학습시키는 것, dropout을 제거하는 것으로 실험을 진행했다. 우선 Wikipedia와 BookCorpus로 pre-train된 상태에서 XLNet과 RoBERTa에서 사용했던 추가 dataset을 통해 추가적인 pre-train을 진행했다. Figure2-(a)를 보면 추가적인 dataset을 사용하는 것이 MLM accuracy를 비약적으로 상승시키는 것에 더해 downstream task에서도 성능을 향상시킨다는 것을 확인할 수 있었다. Table 7을 보면 downstream task 중 예외적으로 SQuAD는 성능이 오히려 하락했는데, 이는 SQuAD는 Wikipedia-based task이기 때문에 발생하는 현상이다. Wikipedia가 아닌 추가 dataset이 학습되면서 당연히 성능 하락이 발생할 수 밖에 없다.

dropout을 제거하는 실험도 진행했는데, 이는 model의 크기가 충분히 거대해 overfitting이 발생하지 않았기 때문이다. Figure 2-(b)를 보면 dropout을 제거했을 때 MLM accuracy가 비약적으로 상승하는 것을 확인할 수 있었다. Table 8을 보면 dropout 제거는 downstream task에서도 더 좋은 성능을 이끌어냈다.
Current State-Of-The-Art on NLU tasks
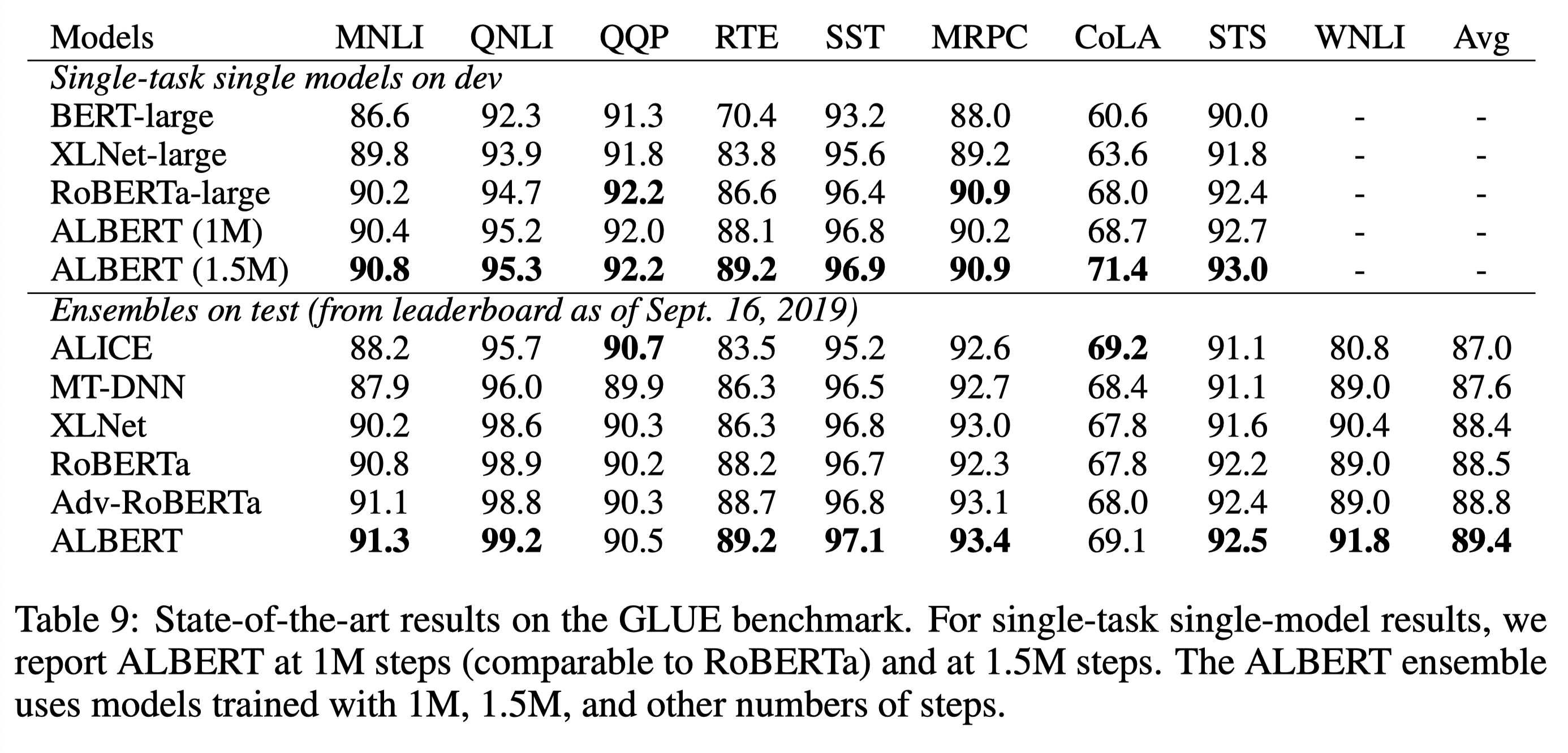
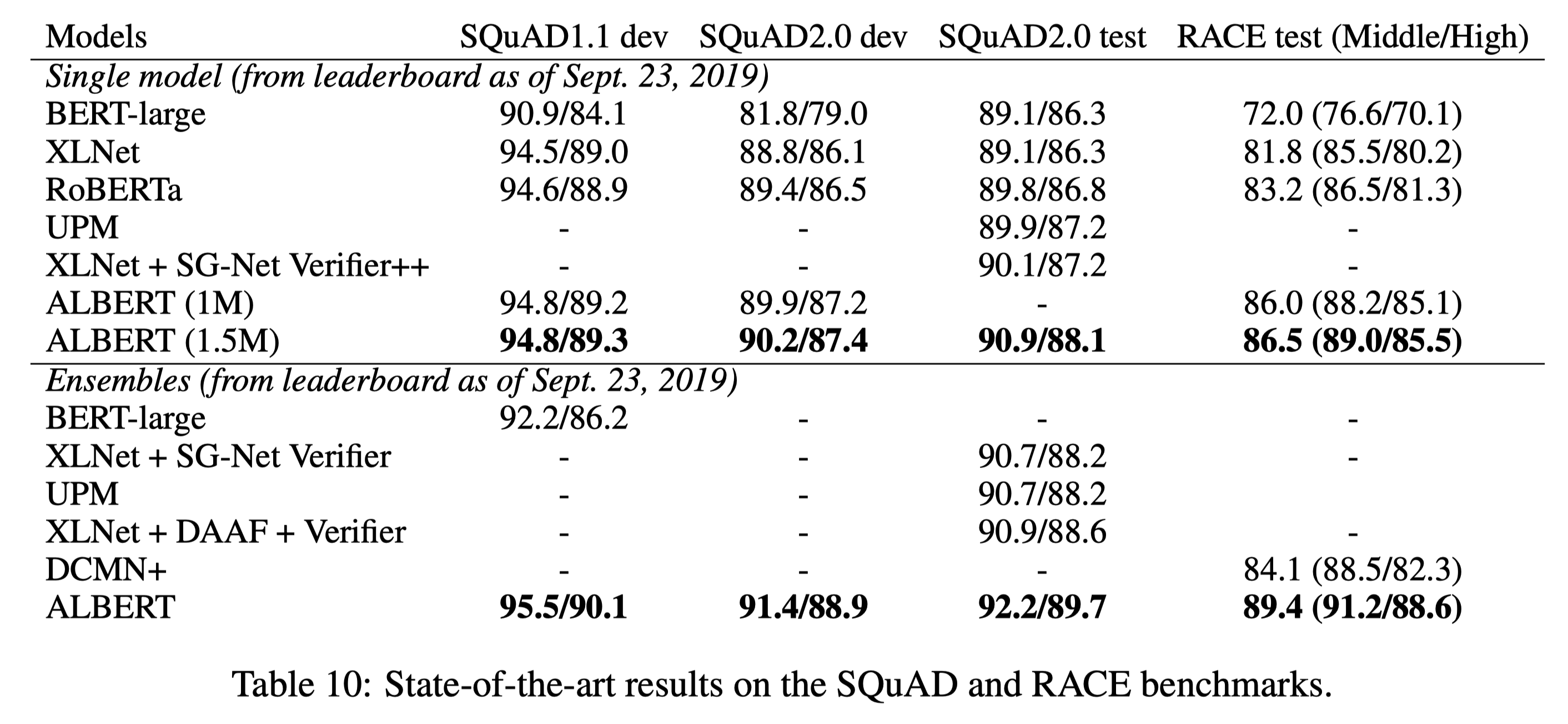
GLUE와 SQuAD, RACE에 대해서 기존의 SOTA model들과 성능을 비교했다. 이 때 ALBERT-xxlarge model을 사용했으며, single model과 ensemble model 모두 성능을 비교했다. 거의 모든 task에서 ALBERT가 SOTA를 달성했음을 확인할 수 있다. 구체적으로 ALBERT ensemble model은 89.4 GLUE score를 달성했으며, 이는 original BERT model보다 17.4 높고, XLNet보다 7.6 높으며 RoBERTa보다도 6.2 높은 수치이다. RACE에서는 ALBERT single model이 86.5 score를 달성했는데, 이는 기존의 SOTA였던 DCMN+ ensemble model보다도 2.4 높은 수치이다.
Discussion
ALBERT가 기존의 model 대비 훨씬 적은 #parameters로 더 좋은 성능을 달성했지만, 거대한 크기 때문에 training time, inference time은 더 느리다는 한계가 있다. 이를 해결하는 것이 앞으로의 주된 과제이다. 또한, SOP가 NSP를 대체할 수 있는 매우 좋은 학습 방법이라는 것은 명백하지만 아직 MLM과 같은 self-supervised training이 잡아내지 못하는 reperesentation power를 모두 cover하지는 못했다고 추측한다.