Paper Info
Submit Date: Oct 6, 2020
Introduction
NLP에서 Tokenization은 전처리 과정에서 가장 중요한 issue 중 하나이다. 가장 적절한 Tokenization 전략을 찾기 위한 연구는 수도 없이 이루어져 왔다. 그 중 가장 대표적인 방식이 BPE이다. BPE는 많은 연구를 통해 보편적으로 가장 효율적인 Tokenization 기법으로 알려졌지만, 아직 language나 task에 구애받지 않고 가장 효율적인가에 대해서는 명확하지 않다. 본 논문에서는 English에 비해 언어 형태론적으로 더 난해한 언어인 Korean에 적합한 tokenization 기법을 찾아내고자 한다. BPE는 가장 보편적인 language인 English를 기준으로 연구된 방식이기에 Korean에 적합하지 않을 수 있다는 생각에서 시작된 연구이다. 본 논문에서는 Korean-English translation, natural language understanding, machine reading comprehension, natural language inference, semantic textual similarity, sentiment analysis, paraphrase identification 등 많은 task에서 실험을 진행했다.
Background
MeCab-ko: A Korean Morphological Analyzer
MeCab은 Conditional Random Fields(CRFs)를 기반으로 하는 Japanese 형태소 번역기이다. Japanese와 Korean의 형태론, 문법 상의 유사성에서 착안해 Korean에 적용시킨 것이 MeCab-ko이다. MeCab-ko는 Sejong Corpus를 통해 학습되었으며, 많은 Korean NLP task에서 사용되어 왔고 매우 좋은 성능을 보였다.
Byte Pair Encoding
BPE는 data에서의 등장 빈도를 기반으로 묶는 data-driven statistical alogirhtm이다.
Neural Machine Translation of Rare Words with Subword Units
Related Work
몇몇 연구에서는 단순 BPE보다 해당 language의 구문에 대한 정보를 기반으로 한 segmentation 기법과 BPE를 혼합해 적용하는 것이 더 좋은 성능을 보인다고 주장해왔다. 특히 non-English language, 그 중 형태론적으로 unique한 특성을 갖는 language에 대해서 더욱 두드러진다. Hindi/Bengali, Arabic, Latvian 등에 대해서 BPE와 함께 unique한 segmentation 기법을 혼용한 연구가 진행되었으며, Korean에 있어서도 동일한 연구가 진행되었다. 하지만 Tokenization이 아닌 NMT task에 있어서 사용되는 parallel corpus filtering 전처리에 관한 연구였다는 점에서 본 논문과는 목적이 다르다.
Tokenization Strategies
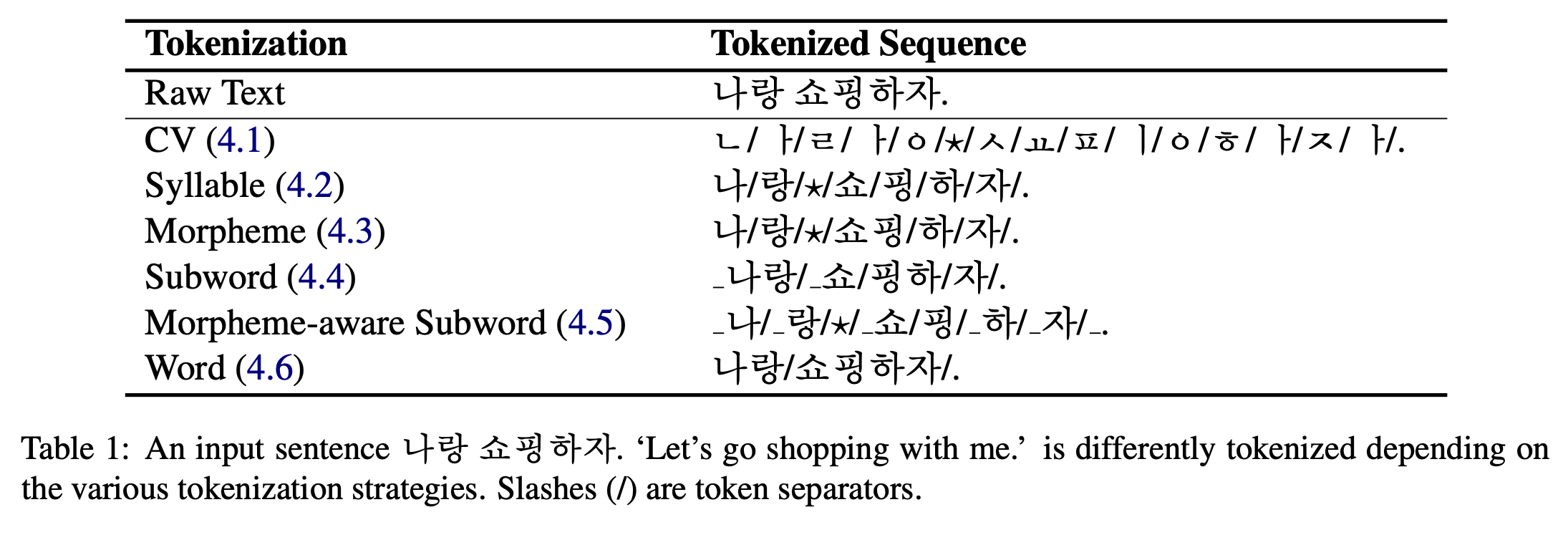
Consonant and Vowel (CV)
자모 단위로 tokenizing을 하는 기법이다. 공백에 대해서 special token \(\star\)를 추가했다.
Syllable
음절 단위로 tokenizing을 하는 기법이다. 역시나 공백에 대한 special token \(\star\)를 사용한다.
Morpheme
MeCab-ko의 형태소 단위 tokenizer를 사용한다. 하지만 이를 사용하면 original input에서의 공백이 제거가 되고, 따라서 original sentence로의 복원이 불가능해진다. 이를 해결하기 위해 공백 special token \(\star\)를 추가했다.
Subword
SentencePiece를 사용한 BPE를 적용했다. original sentence의 단어 단위를 구분하기 위해서 original sentence의 공백에 대응하는 token \(\_\)를 매 단어의 시작에 삽입했다.
Morpheme-aware Subword
위의 Subword 방식에서 한 발 더 나아가 언어론적 특징을 기반으로 한 segmentation 전략을 BPE와 결합한 방식이다. Morpheme 방식을 먼저 적용한 뒤, 형태소의 list에 대해서 BPE를 적용하게 된다. Morpheme를 적용한 후에 BPE를 사용하기 때문에 형태소 경계를 뛰어넘는 BPE는 발생하지 않는다. (“나랑 쇼핑하자.”에서 ‘쇼핑’, ‘하’는 각각이 별개의 형태소이기 때문에 (‘핑’,’하’)가 Pair로 묶일 수는 없다.)
Word
original input에서 공백을 기준으로 단어 단위로 tokenizing을 수행하는 가장 단순한 방식이다.
Experiments
Korean to/from English Machine Translation
Dataset
AI Hub에서 제공하는 Korean-English parallel corpus를 사용했다. 800K sentences pairs의 news data를 포함하고, 784K의 train data, 8K의 dev data, 8K의 test data로 구분했다.
BPE Modeling
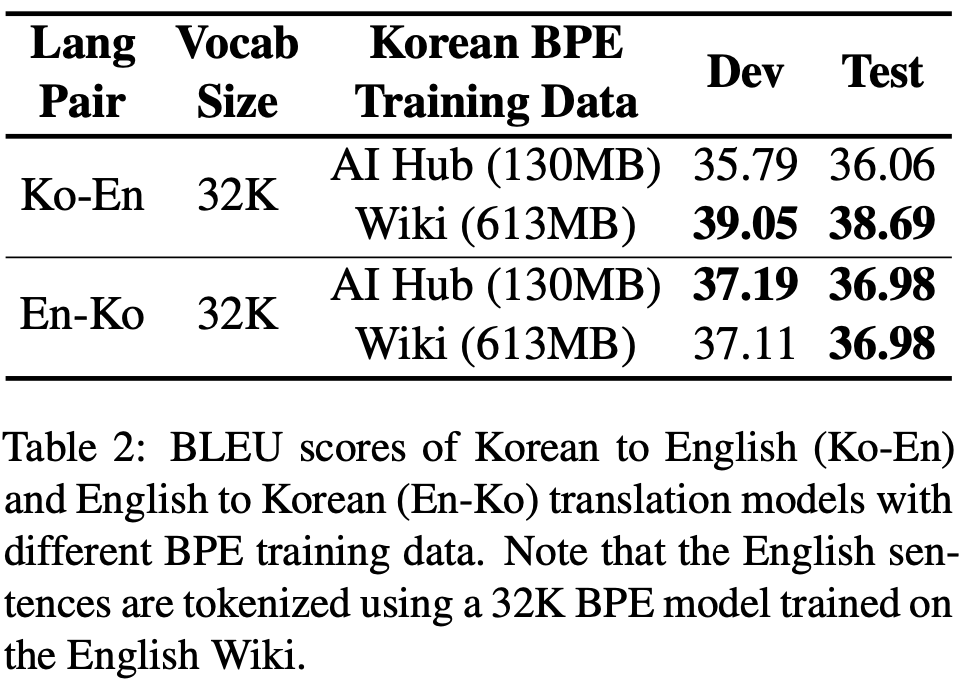
BPE training에서 AI Hub의 data를 사용할지, Wiki의 data를 사용할지 결정하기 위해 실험을 진행한다. AI Hub의 data는 실제 task에서의 dataset과 동일하기 때문에 corpus set이 동일하다는 장점이 있는 반면, dataset의 크기가 작다. Wiki는 dataset의 크기가 크지만, news에서 사용되는 corpus set과는 차이가 있다는 단점이 있다. Korean-English Translation, English-Korean Translation으로 성능을 비교해보는데, English BPE는 동일하게 Wiki의 English data를 사용한 32K BPE model을 사용했다. 그 결과, AI Hub의 data보다 Wiki의 data가 더 좋은 성능을 보였다. 따라서 본 논문의 이후에서는 Korean BPE training을 위해 Wiki dataset을 사용한다.
Training
다양한 vocabulary size의 BPE model로 AI Hub news dataset에 대해서 tokenization 기법을 테스트한다. 우선 NMT task에서 SOTA를 달성한 Transformer model을 사용한다. 가장 보편적으로 사용되는 hyperparameter 값을 채택했다. FAIRSEQ를 사용해 실험을 진행했다. 50 epochs마다 checkpoint를 저장했다.
Results
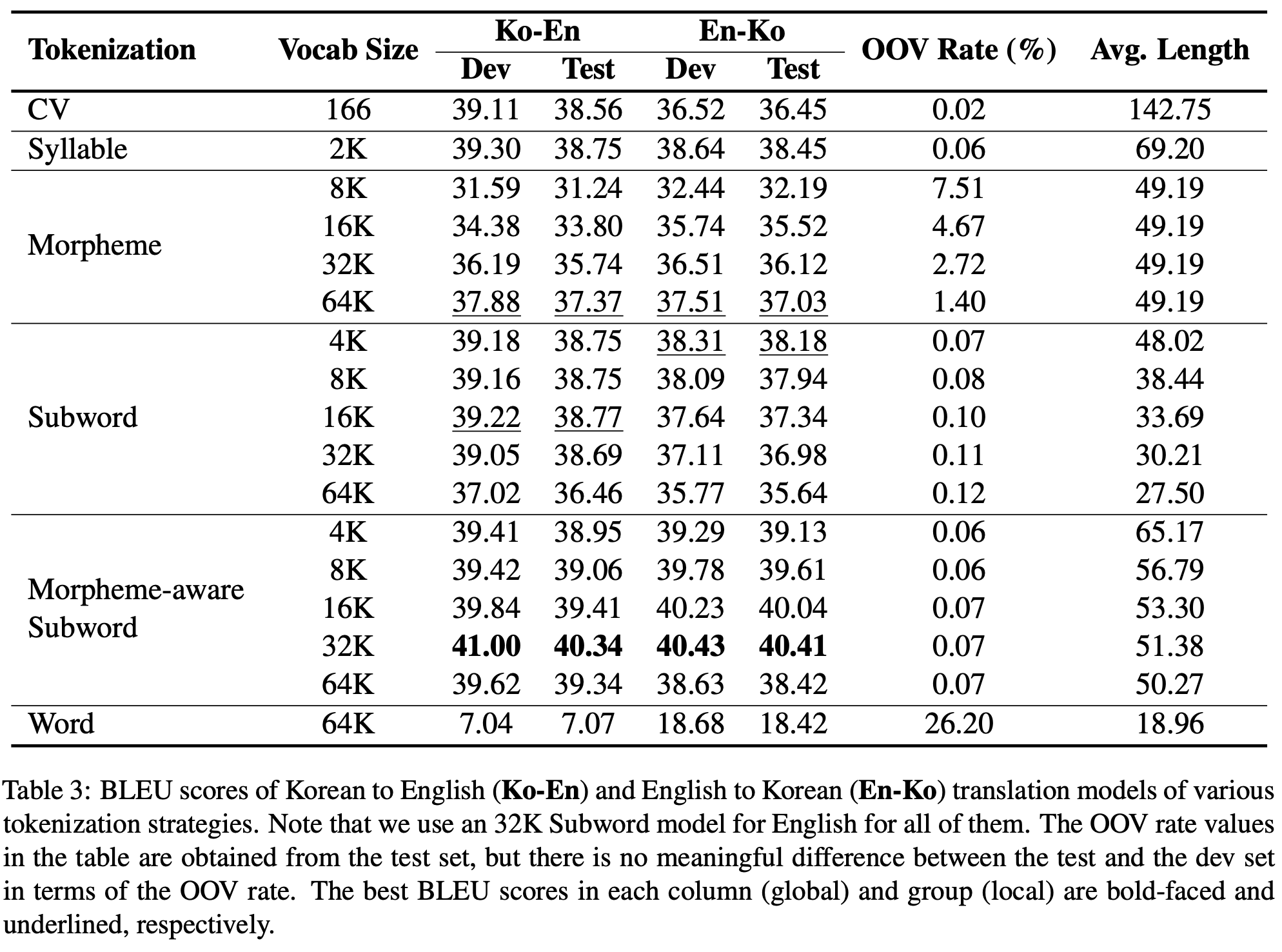
Ko-En, En-Ko task에서 모두 Subword와 Syllable가 Morpheme이나 Word보다 더 좋은 성능을 보였다. 이는 OOV Rate와 큰 관련이 있다. 한국어의 형태론은 너무 복잡한 규칙을 가져 수많은 형태소가 있기 때문에 64K 이하의 vocabulary size로는 OOV가 많이 발생할 수 밖에 없다. 하지만 Subword나 Syllable은 모두 음절 단위의 model이기 때문에 OOV가 훨씬 더 적게 발생하게 된다.
한편 CV의 OOV Rate는 당연히 가장 적은 수치를 보여주는데, Syllable나 Subword에 비해서는 더 낮은 성능을 보여준다. 이를 통해 자모 단위는 문맥 정보를 담기에는 너무 작은 단위라는 것을 알 수 있다.
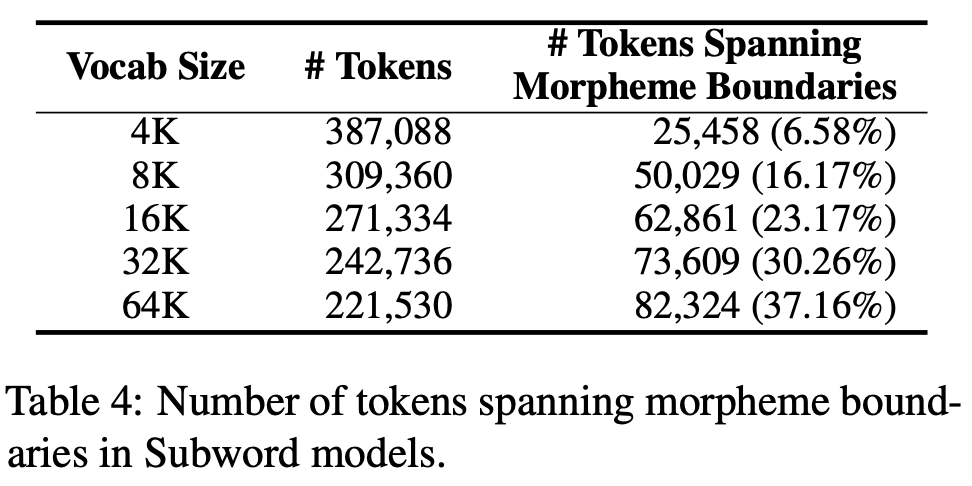
Morpheme-aware Subword가 가장 높은 BLEU Scores를 보여준다. Subword와 Morpheme-aware Subword의 차이점은 BPE 이전에 Morpheme의 수행 여부인데, 이는 결국 형태소 경계를 넘어서는 BPE가 발생하는가(Token Spanning Morpheme Boundaries)에서 차이를 보인다. 위의 Table은 Subword에서 각 vocabulary size마다 발생하는 Tokens Spanning Morpheme Boundaries의 횟수를 보여준다. 6~37%의 수치를 보여준다. 이를 통해 형태소 단위의 구분은 tokenization에서 성능에 큰 영향을 미치며, 따라서 형태소 구분을 무시한 단순 BPE는 Korean Tokenizing에 적합하지 않다는 것을 알 수 있다.
Korean Natural Language Understanding Tasks
BERT model을 사용했다. KorQuAD, KorNLI, KorSTS, NSMC, PAWS의 5개 NLU downstream task에 대해서 테스트를 진행했다.
Downstream Tasks
-
Machine Reading Comprehension: KorQuAD 1.0 Dataset
SQuAD를 Korean에 맞게 적용한 dataset이다. 10,645개의 지문과 66,181개의 질문이 포함되고, 각 지문에 대해 주어진 여러 질문 중 가장 적합한 질문을 선택하는 task이다.
-
Natural Language Inference: KorNLI Dataset
950,354개의 sentence pair(전제, 추론)이 있고 각 pair에 대해 두 sentence 사이의 관계가 entailment, contradiction, neutral인지 classification을 수행하는 task이다.
-
Semantic Textual Similarity: KorSTS Dataset
8628개의 sentence pair가 있고, 각 pair에 대해 0~5 사이의 semantic similarity를 도출해내는 task이다.
-
Sentiment Analysis: NSMC Dataset
네이버 영화 review에서 추출한 400K의 sentence에 대해 0(negative)~1(positive) 사이의 sentiment Analysis를 도출해내는 task이다.
-
Paraphrase Identification: PAWS-X Dataset
paraphrase identification dataset인 PAWS-X에서 Korean dataset만 추출해낸 53,338 sentence pairs에 대해 0(negative)~1(positive)의 paraphrase identification을 도출해내는 task이다.
Training
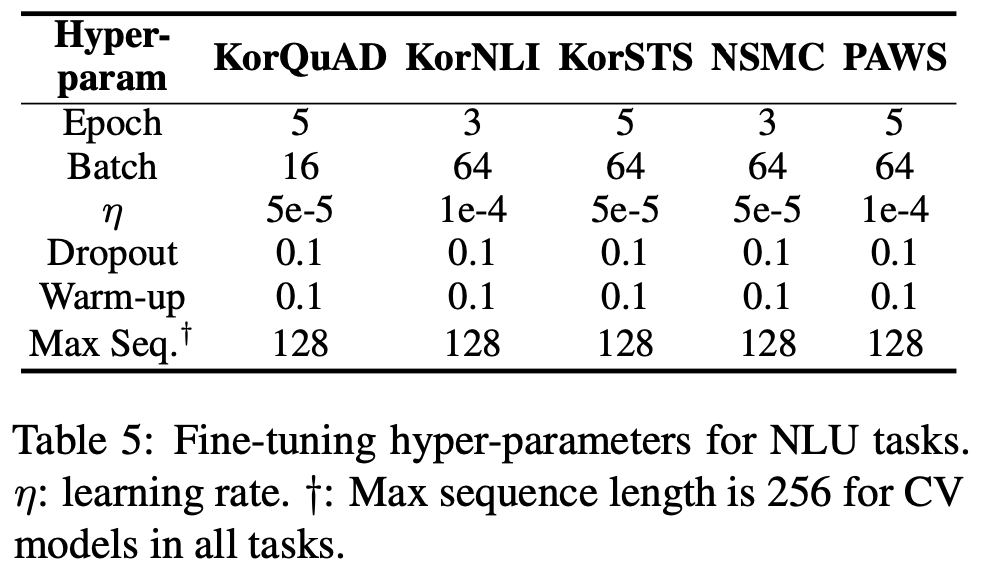
large corpus로 pre-train된 BERT-Base model을 각 5개의 NLU task에 대해 별개로 fine-tuning시켜 실험을 진행했다. Korean Wiki Corpus(640MB)는 pre-train을 진행할 만큼 충분한 크기가 되지 못해 Namu-wiki에서 5.5GB의 corpus를 추출해내 Wiki Corpus와 함께 사용했다. hyperparameter는 batch size=1024, max sequence length=128, optimizer=AdamW, lr=5e-5, warm up steps=10K를 사용했다. pre-trained된 BERT Model을 Tensorflow에서 Pytorch로 convert한 뒤, HuggingFace Transformers를 사용해 fine-tuning을 진행했다. fine-tuning에서의 hyperparameter는 위 Table의 값을 사용했다.
Results
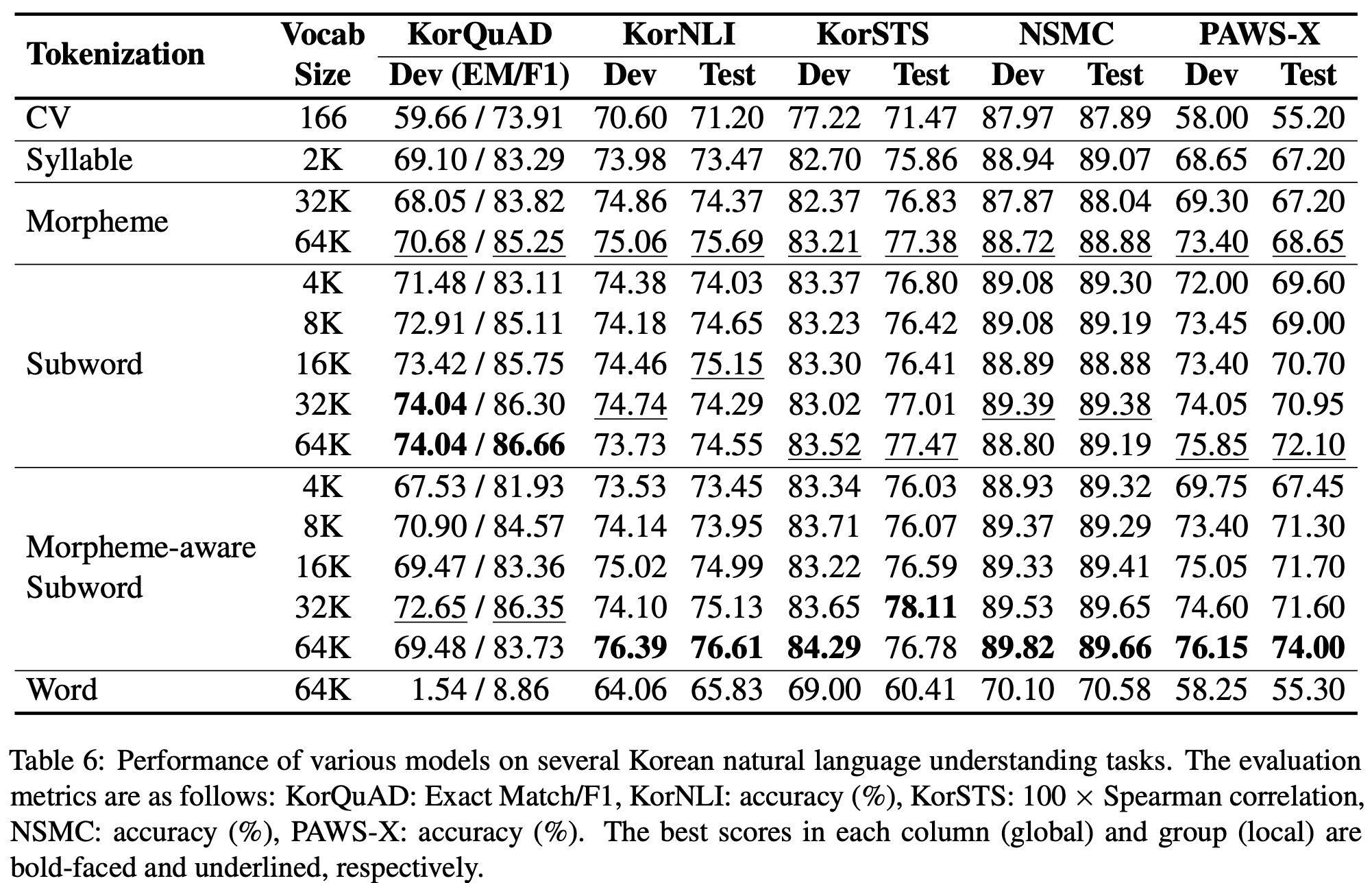
위의 5개의 NLU task에 대해 6개의 tokenizing 기법을 사용해 각각 dev set, test set에서의 성능을 측정했다. 예외적으로 KorQuAD의 경우에는 test set이 부족해 dev set만 사용했다.
KorQuAD task에서는 Subword 64K model이 가장 좋은 성능을 보였다. Morpheme와 Subword에서는 vocabulary size와 Score가 비례 관계이다. 하지만 Morpheme-aware Subword에서는 32K model이 제일 높은 수치를 달성했다. 결론적으로, Morpheme-aware Subword model에서는 성능과 vocabulary size 사이의 유의미한 상관관계를 찾을 수 없었다.
나머지 다른 4개의 task에 대해서는 모두 Morpheme-aware Subword의 64K model이 가장 좋은 성능을 달성했다. tokenization 방식에 관계 없이 모두 다 vocabulary size와 score가 대체로 비례 관계를 보였다. 그러나 위에서 진행했던 NMT task에 있어서는 Morpheme-aware Subword에서의 높은 vocabulary size가 좋은 성능을 보장하지는 않았는데, 다소 배치되는 결과이다.
Discussion
Token Length
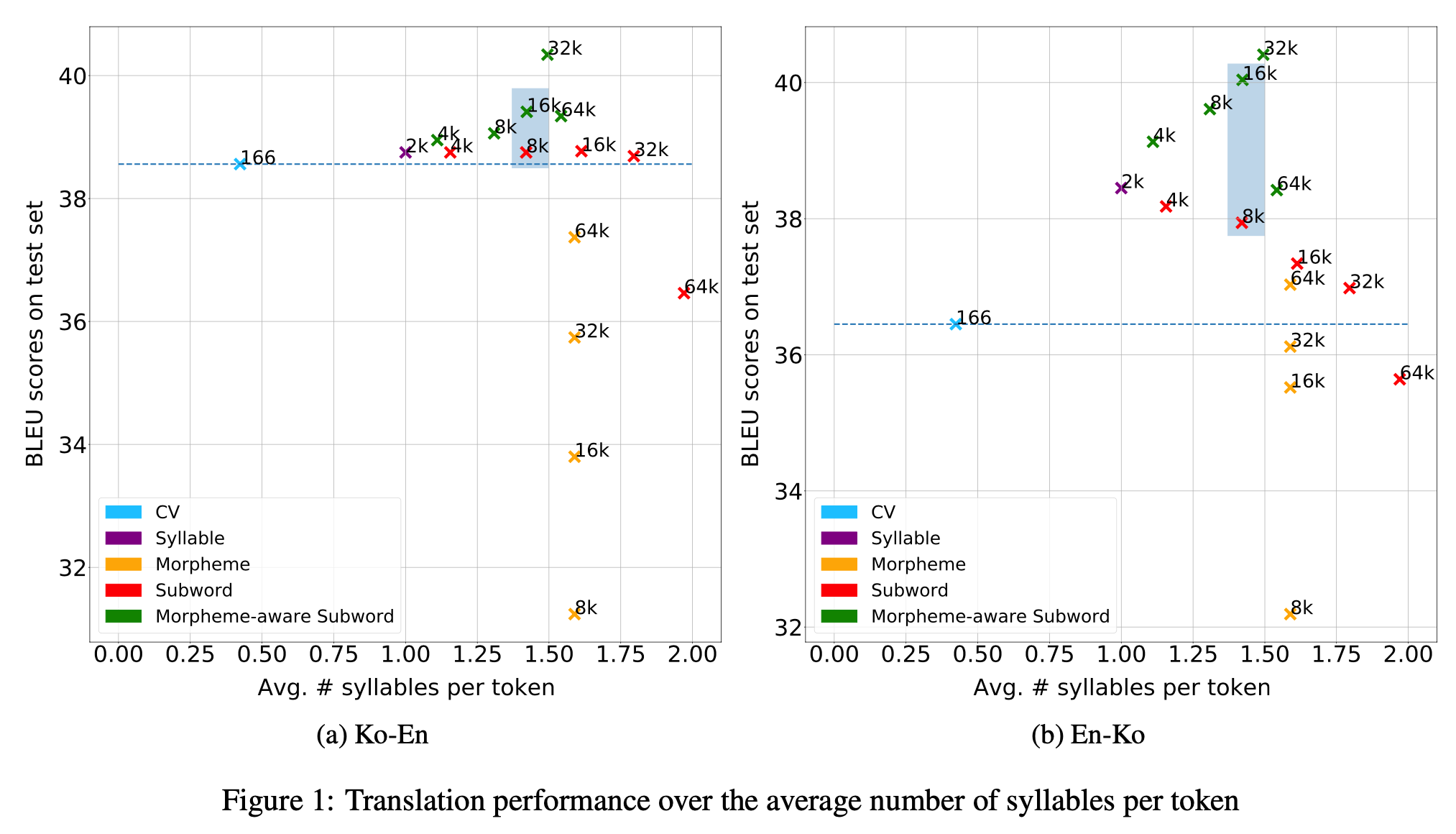
token의 길이가 성능에 얼마나 영향을 미치는지 알아본다. token length는 한 token에 포함된 음절 개수의 평균으로 정의한다. CV의 경우에는 자모 단위이기 때문에 평균 token length는 0.33~0.5 사이의 값이다. 한 음절은 2~3개의 자모로 구성되어 있기 때문이다. Syllable은 음절 단위로 tokenizing을 한 것이기 때문에 평균 token length는 1의 고정 값을 갖는다. Morpheme는 형태소 단위로 tokenizing을 수행한 것이기 때문에 평균 token length가 vocabulary size에 따라 변하지 않고 일정하다. Subword나 Morpheme-aware-Subword는 모두 BPE를 사용하는 방식이기 때문에 vocabulary size가 증가할수록 token length도 증가하게 된다. 통계적인 빈도를 기반으로 vocabulary size에 따라 상위 N개를 pair로 묶기 때문이다. 위의 figure에는 word model이 누락됐는데, word model은 Ko-En과 En-Ko에서 각각 7.07, 18.42로 매우 낮은 Score를 보여줘 공간상의 제약으로 figure에서 제외했다.
Figure 1을 분석해보자. 자모 단위로 tokenizing을 수행한 CV의 성능이 기준점이다. 대부분의 model은 평균 token length가 1.0~1.5인 구간에서 가장 좋은 성능을 보여준다. 평균 token length가 1.5를 넘어가기 시작하면서 점차 감소하는 경향을 보인다. 특히 평균 token length가 2.5에 달하는 word model의 경우에는 최악의 성능을 보여줬다.
Linguistic Awareness
Figure 1에서 8K Subword model과 16K Morpheme-aware Subword model을 비교해보자. figure에서 파란 색 배경으로 강조 표시가 된 부분이다. 두 model은 평균 token length가 동일한 값이다. 두 model의 차이는 언어론적 지식을 사용했는가(형태소 경계를 넘어서는 pair를 생성했는가)에 있다. Ko-En과 En-Ko 두 task에서 모두 Morpheme-aware Subword model이 더 좋은 성능을 보여줬다는 것은 token length뿐만 아니라 linguistic awareness도 tokenization 전략 수립에 매우 중요한 factor라는 것을 보여준다.
Under-trained Tokens
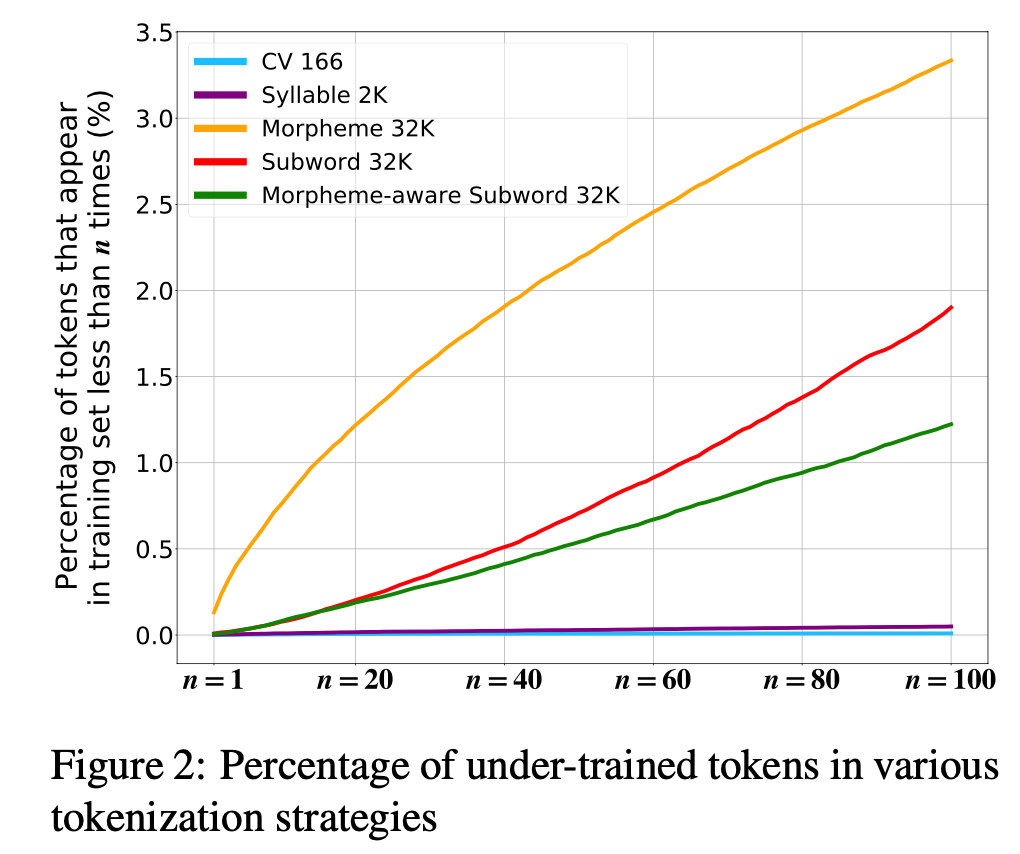
Figure 1에서 Morpheme model의 경우에만 예외적으로 CV보다 훨씬 못한 성능을 보여준다. 이러한 결과는 Morpheme model의 높은 OOV rate에서 비롯된다. 위의 Experiments에서 살펴본 NMT task에서의 result table을 확인해보면 Morpheme model의 OOV rate가 압도적으로 높다는 것을 확인할 수 있다(본 논의에서는 모든 task에서 최악의 성능을 보여줬던 Word model은 배제한다). OOV는 정의하자면 test set에서만 등장하고, train set에서는 등장하지 않았던 token을 의미한다. 즉, OOV rate가 높다는 것은 model 입장에서는 처음 보는 token이 test set에서 등장하는 비율을 의미한다. 완전히 처음 마주하는 token이 아닌 적게 마주한 token들의 비율에 대해서도 확인을 해보자. OOV가 아니라 하더라도 등장 빈도가 확연히 적은 token들에 대해서는 model이 under-train했을 가능성이 농후하기 때문이다. Figure 2에서는 실제로 등장 빈도가 낮은 token의 비중이 얼마나 되는지를 시각화 한 graph이다. 예상했던 바와 같이 OOV rate가 높은 Morpheme model이 훨씬 더 높은 수치를 보여준다는 것을 확인할 수 있다. 이는 결국 Morpheme model이 under-trained된 token의 비중이 높다는 것을 의미한다. 이러한 이유로 Morpheme model이 타 model 대비 확연히 낮은 성능을 보이는 것이다.
Conclusion
여러 Korean NLP task에 대해서 다양한 tokenization 전략을 사용한 model들의 성능을 비교했다. Korean-English NMT task에서는 BPE에 언어론적 특성(형태소)를 더한 Morpheme-aware Subword Model이 가장 높은 성능을 보여줬다. NLU task의 KorQuAD를 제외한 모든 task에서 역시 Morpheme-aware Subword Model이 가장 좋은 수치를 달성했다. 이를 통해 각 language의 unique한 linguistic awareness가 model 성능 향상에 매우 큰 영향을 미친다는 사실을 도출해냈다.