Paper Info
Submit Date: Jun 12, 2017
Introduction
RNN과 LSTM을 사용한 Neural Network 접근 방식은 Sequencial Transduction Problem에서 매우 좋은 성능을 달성했다. 그 중 특히 Encoder-Decoder를 사용한 Attention Model이 state-of-art를 달성했다. 하지만 Recurrent Model은 본질적으로 한계가 존재하는데, 바로 Parallelization이 불가능하다는 문제점이다. 이는 Sequence의 길이가 긴 상황에서 매우 큰 단점이 된다. 최근의 연구들이 computation을 최소화하는 방향으로 Model의 성능 향상을 이뤄내기는 했지만, 결국 Recurrent Model의 본질적인 문제는 해결하지 못했다. 본 논문에서 소개하는 Transformer Model은 RNN을 제거해 Recurrent Model의 문제점에서 벗어났고, Parallelization을 가능하게 했다. 이에 따라 매우 좋은 성능을 달성했다.
Model Architecture
Transformer Model은 attention seq2seq model과 비슷한 구조를 지닌다. Encoder-Decoder가 존재하고, fixed length의 하나의 context vector를 사용하는 방식이 아닌, 하나의 output word마다 각기 다른 새로운 attention을 갖는 context vector를 생성해 활용한다. 차이점은 RNN을 제거했다는 점이다. NLP에서 RNN을 사용하는 가장 큰 이유는 sequential 정보를 유지하기 위함(각 단어들의 순서 및 위치 정보를 활용하기 위함)이다. Transformer에서는 RNN 대신 FC Layer를 사용하되, 각 word vector마다 positional Encoding 과정을 추가해 각 word의 position 정보를 word vector 안에 추가했다.
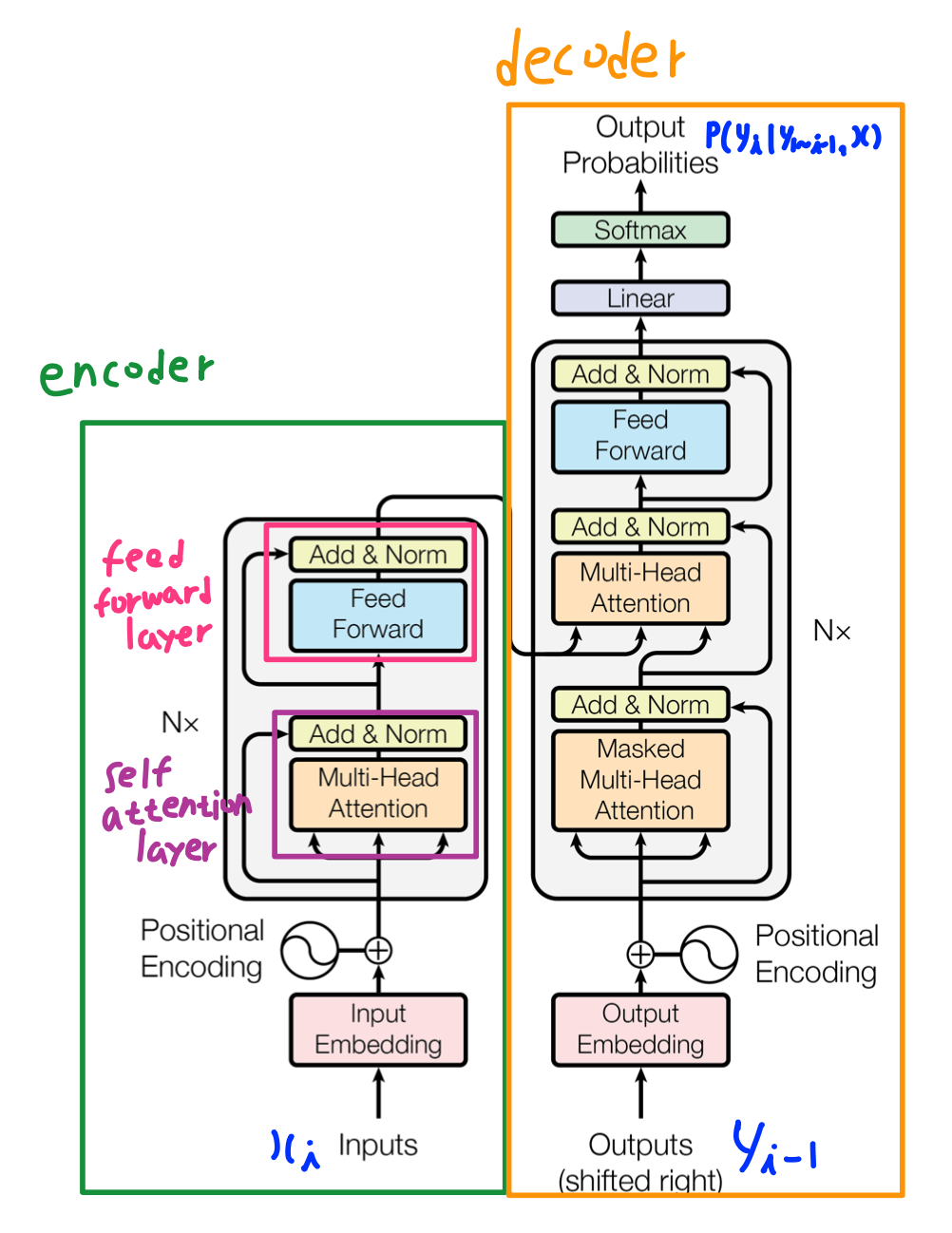
Encoder
Transformer의 Encoder는 6개의 동일한 Encoder Layer를 Stack 구조로 쌓아올린 형태이다. 각각의 Encoder Layer는 2개의 SubLayer로 구분되는데, Self Attention Layer와 Feed Forward Layer이다. Self Attention Layer에서는 word vector에 attention을 담는다. 이 결과를 Feed Forward Layer를 거쳐 다음 Encoder Layer의 input으로 넣는다. 이러한 과정을 6회 반복해 최종 output을 Decoder로 넘겨준다. 각각의 Self Attention Layer는 Attention을 word vector에 담는 기능을 수행하는데, 이를 중첩해 반복하면 단어 단위가 아닌 점차 전체 문맥에서의 Attention을 담게 된다. Self Attention Layer의 동작은 아래에서 자세히 살펴보겠다. 각 SubLayer의 결과에는 항상 Normalization이 수행되는데, 이 때 SubLayer를 통과하기 전 input이 그대로 더해지게 된다. 이를 Residual Connection이라고 한다. Residual Connection은 BackProp시 gradient vanishing을 최소화시켜 Model 성능 향상을 돕는다.
Self Attention Layer
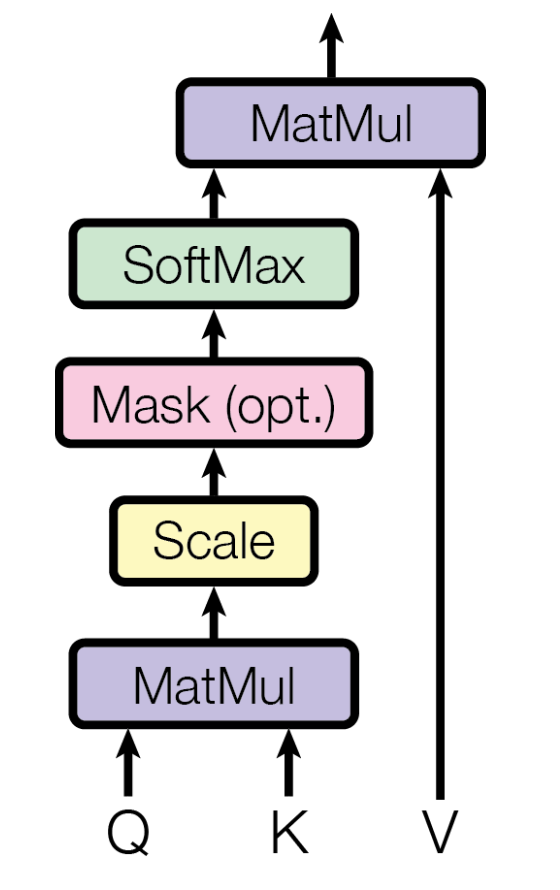
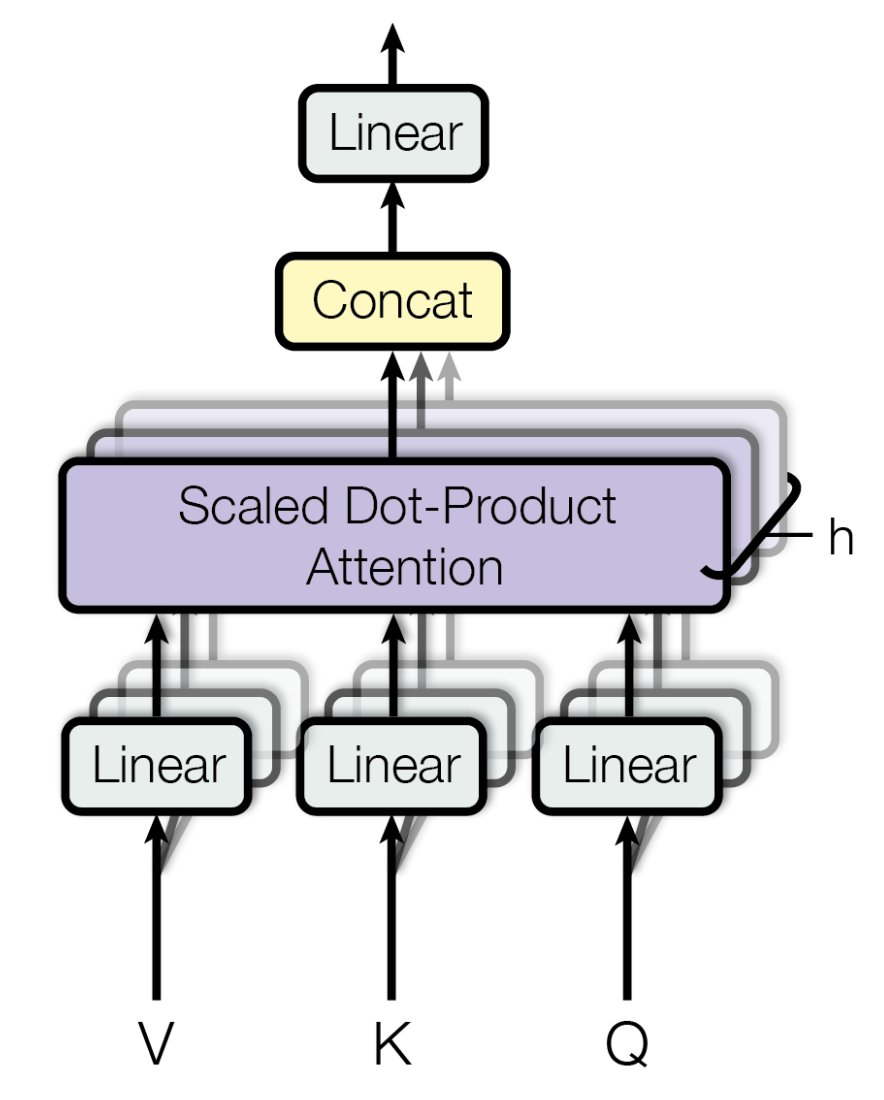
Self Attention Layer는 word vector에 attention을 추가하는 layer이다. Query, Key, Value가 사용된다. Query, Key, Value는 각각 input word에 대해 특정한 weight matrix를 곱한 결과값이다. 해당 weight matrix들은 학습되는 parameter들이다. 우선 각 단어들을 기준으로 나눠 살펴보자.
현재 단어의 word vector를 \(x_i\)라고 하면, query는 \(x_i\)에 대한 query \(q_i\)이다. input word \(x_i\)에 대한 연관성을 묻는 Query(질의)이다. Key와 Value는 \(x_i\)와 연관성을 검사하는 대상 \(x_j\)에 대한 값이다. 사실 Key와 Value는 동일한 값인데, 사용되는 위치만이 다르다. \(q_i\)와 \(k_j\)를 곱하면 \(x_i\)와 \(x_j\)가 연관된 수치를 의미하는 score가 생성된다. 이를 Dependency라고 한다. Dependency를 softmax에 넣으면 확률값이 생성된다. 이를 \(v_j\)와 곱하고, 해당 값을 모두 더하면 attention이 담기긴 vector가 완성된다.
query, key, value는 모두 위의 단어 예시에서 vector 단위였다. 이를 concatenate해 하나의 matrix로 만들 수 있다. 그렇다면 dot product 연산으로 모든 sentence 전체에 대한 attention matrix를 구할 수 있다. 이렇게 병렬 처리를 함으로써 model의 학습 속도를 증가시켰다. 위의 좌측 이미지는 이러한 과정을 표현한 것이다. Scale은 \(d_k\)의 제곱근으로 Q와 K의 dot product 결과값을 나누는 것인데, 절댓값이 너무 커져 softmax에서 gradient가 줄어드는 것을 방지하기 위함이다.
사실 이런 dot product를 통해 attention을 구하는 하나의 과정 자체도 병렬적으로 동시에 여러 번 수행된다. 위의 우측 이미지를 보면 dot product 연산을 병렬적으로 h번 수행해 모두 concatuation을 해 하나의 matrix를 생성한다는 것을 알 수 있다. 해당 matrix를 기존의 input matrix size로 변경하기 위해 다른 weight matrix \(W\)와 dot product를 수행한 뒤 그 결과를 다음 Feed Forward Layer에 넘기게 된다.
Decoder
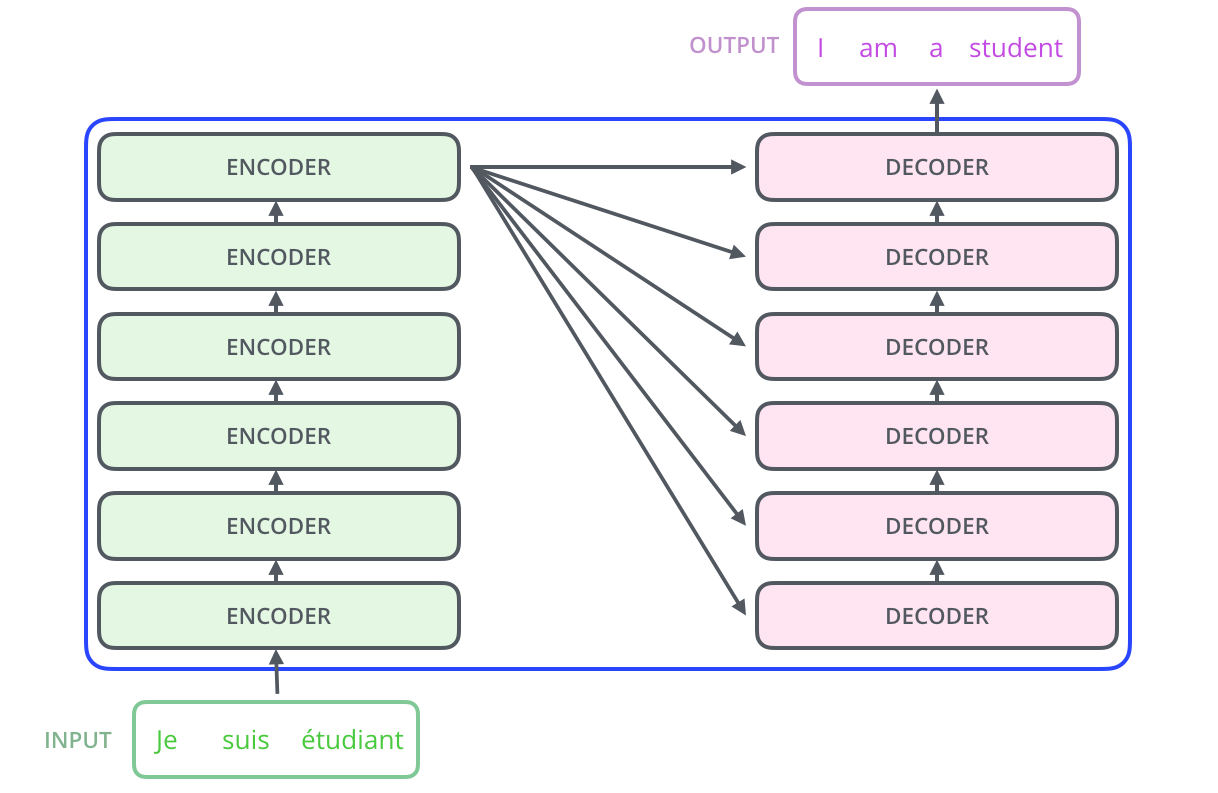
출처: https://jalammar.github.io/illustrated-transformer/
Decoder는 Encoder와 매우 비슷한 구조를 갖는다. 동일한 6개의 Decoder Layer를 Stack 구조로 쌓아올린 형태이고, 각각의 Decoder Layer에는 Encoder Layer와 같은 Self Attention Layer와 Feed Forward Layer가 존재한다. Encoder와의 차이점은 Self Attention Layer 이전에 Masked Layer가 있다는 점이다. 6개의 Decoder Layer를 거친 최종 output 값을 softmax를 사용해 확률값으로 구하는데, 이는 i번째 output word에 대한 조건부 확률값이다. 6개의 Decoder Layer는 모두 마지막 Encoder Layer의 output인 context vector를 input으로 받고, 동시에 이전 단계의 Decoder Layer에서 생성된 attention vector도 input으로 받는다. Masked Attention Layer에서는 현재 word의 기준으로 이후 word에 mask를 씌운 vector값이다. 현재 시점의 attention을 생성할 때 이후 word들의 영향을 없애기 위함이다.