[NLP 논문 리뷰] BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
19 Jul 2020
Paper Info
Submit Date: Oct 11, 2018
Introduction
NLP에서도 pre-trained된 model을 사용하는 기법은 있었지만, pre-train에서 단방향의 architecture만 사용할 수 있다는 한계점이 있었다. 이는 양방향에서의 문맥 정보가 모두 중요한 token-level task에서 좋은 성능을 보이지 못하는 원인이 되었다. 본 논문에서는 MLM(Masked Language Model)을 사용해 bidirectional한 context도 담을 수 있는 BERT Model을 제시한다. MLM이란 문장에서 random하게 단어를 선택해 masking을 하고, model이 bidirectional context를 통해 해당 단어를 predict하도록 하는 것이다. BERT는 pre-train을 통해 task에 대한 학습이 아닌 language 자체에 대한 학습을 한 뒤, task에 맞게 fine-tuning을 하고, pre-training 과정에서 bidirectional한 context를 학습한다. 그 결과, BERT는 11개의 NLP task에서 SOTA를 달성했다.
Related Work
language의 context를 학습하는 pre-training 방법은 크게 2가지로 구분된다.
Feature-based Approach
task-specific한 model이 pre-trained된 model을 feature로 사용한다. pre-trained된 feature를 concat해서 model의 input으로 사용하는 방식 등이 있다.
Fine-tuning Approach
pre-train에서 일반적인 task를 위한 model을 학습하는데, 이 때 task-specific한 parameter를 최대한 배제한다. 이후 downstream task에서 이전에 학습된 parameter들을 task specific하게 fine-tuning한다. 즉, language에 대해 학습된 값으로 initialized된 상태에서 task specific한 layer를 추가한 뒤 fine-tuning을 시작한다. 이 때 pre-train된 parameter들과 task specific layer의 parameter들이 모두 학습된다.
BERT
BERT는 Fine-tuning Approch를 채택했다. 따라서 Pre-training, Fine-tuning의 2가지 Step으로 구분된다.
Pre-Training에서는 Unsupervised Learning을 통해 Language 자체의 representation을 학습한다. 특정 task에 부합하는 학습이 아닌 language의 일반적 특성을 학습한다. 이후 Fine-tuning에서는 각각의 task에 맞는 labeled data를 사용해 Supervised Learning을 수행한다. 이 과정에서 Pre-trained 단계에서 학습을 통해 얻어진 parameters의 값들도 변경된다. 즉, Pre-training은 parameters의 초기값이 language의 일반적 특성을 담는 값으로 시작하도록 설정하는 역할이다.
Architecture
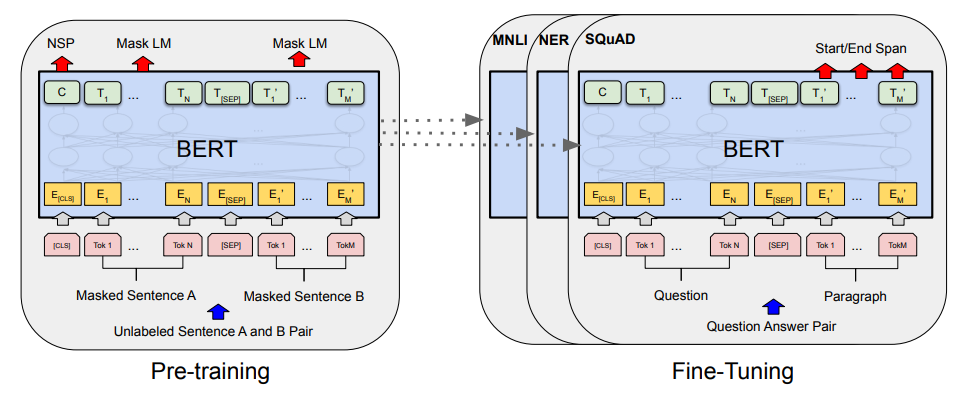
Input/Output Representation
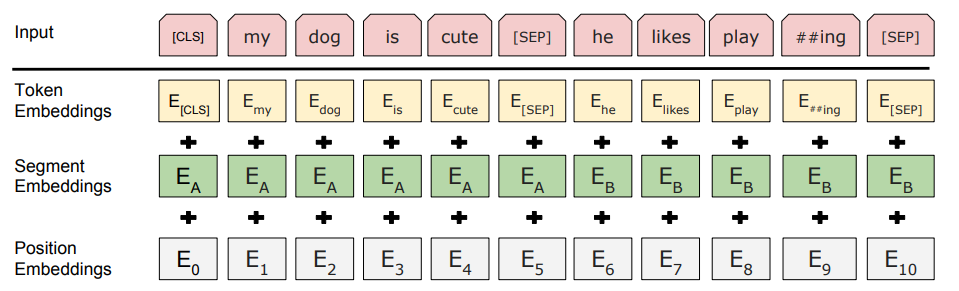
Input은 Token Embedding + Segment Embedding + Position Embedding이다. Token은 실제 word에 대한 embedding, Segment Embedding은 몇번째 Sentence에 포함되는지에 대한 Embedding, Position Embedding은 Input에서 몇번째 word인지에 대한 Embedding이다. Transformer에서도 언급했듯이 병렬 처리를 위해 RNN을 제거하고, Sequential한 정보를 보존하기 위해 Position Embedding을 추가한 것이다. BERT는 Input으로 최대 2개의 Sentence까지 입력받을 수 있는데, 이는 Q&A task와 같은 2개의 문장에 대한 task도 처리할 수 있게 하기 위함이다. 이를 처리하기 위해 Seperate Token SEP을 추가했다. 이와 별개로 Classification을 위한 CLS Token도 Input Sequence의 제일 앞에 항상 위치하는데, Transformer Encoder의 최종 Output에서 CLS Token과 대응되는 값은 Classification을 처리하기 위해 sequence representation을 종합해서 담게 된다.
Pre-training
BERT는 MLM과 NSP라는 2가지의 Unsupervised task를 사용해 Pre-training을 수행한다.
MLM (Masked Language Model)
기존의 전통적인 Pre-train은 left to right model과 right to left model을 단순하게 concat한 뒤 사용했다는 점에서 제대로 된 Bidirectional context를 담지 못했다. BERT는 MLM을 사용해 진정한 의미의 Bidirectional context를 담게 된다. 기존의 Model들이 unidirectional model의 결과들을 concat해서 사용한 이유는, bidirectional model은 word 자기 자신을 masking하더라도 다층 Layer에서는 간접적으로 자기 자신에 대한 정보를 알 수 있기에 제대로 된 학습이 불가능했기 때문이다.
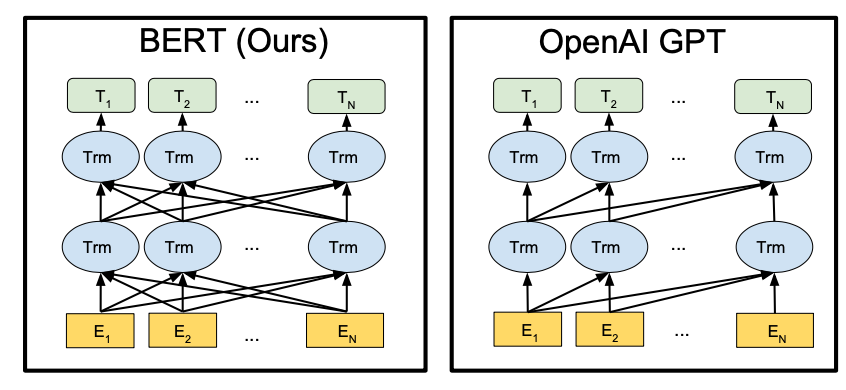
위의 왼쪽 Model은 BERT로, Bidirectional Model이다. 반면 오른쪽 Model은 OpenAI GPT로, left to right Unidirectional Model이다. Bidirectional Model에서 다층 Layer일 경우에는 이전 Layer의 모든 Output에서 모든 Token에 대한 정보를 담게 되기 때문에 특정 Token을 Masking했다고 하더라도 다음 Layer에서는 자기 자신에 대한 정보를 간접적으로 참조할 수 있게 된다. 반면 Unidirectional Model에서는 이런 일이 발생하지 않는다.

이를 해결하기 위해 BERT는 Masking을 하되, 그 중 80%에 대해서만 실제 MASK Token으로 변경하고, 10%에 대해서는 random한 다른 Token으로, 나머지 10%에 대해서는 변경을 하지 않았다. Masking을 하는 비율은 전체 Word 중에서 15%만 수행했으므로, 실제로 MASK Token으로 변경되는 비율은 12%밖에 되지 않는다. 이를 통해 얻을 수 있는 이점은 Model이 모든 Token에 대해서 실제로 맞는 Token인지 의심을 할 수 밖에 없게 되기에 제대로 된 학습을 이뤄낼 수 있다. 이는 Bidirectional Model의 한계인 간접 참조도 해결했다.
NSP (Next Sentence Prediction)

QA, NLI와 같은 task는 token단위보다 sentence 단위의 관계가 더 중요하다. 위의 MLM만으로 Pre-training을 하게 될 경우 token level의 정보만을 학습하기 때문에 NSP를 통해 sentence level의 정보도 담기로 한다. 두 문장이 서로 연결되는 문장인지를 isNext, NotNext의 Binary classification으로 해석하게 된다. 50%의 확률로 isNext, NotNext의 data를 생성한 뒤에 학습을 시킨다. 이 때 위에서 언급한 CLS Token이 주요하게 사용된다.
Pre-training Detail
실제 Pre-training 단계는 다음과 같이 진행된다.
corpus에서 문장들을 뽑아내 두 문장의 sequence로 만들고, 각각 A, B를 Segment Embedding으로 부여한다. 50%의 확률로 B 문장은 실제로 A문장에 이어지는 문장이고(IsNext), 50%의 확률로 A문장에 이어지지 않는 문장이다(NotNext). 이후 Word Piece Tokenization을 한 뒤, Masking을 수행한다.
Hyperparameters는 다음과 같다.
batch size = 256 sequences
sequence size = 512 tokens
#epoch = 40
Optimizer: Adam (learning rate = 1e-4, B_1 = 0.9, B_2 = 0.999, L2 weight decay = 0.01)
dropout: 0.1 in all layers
activation function: gelu
loss function: sum of the mean MLM likelihood + mean NSP likelihood
Pre-training에 BERT_BASE는 16개의 TPU로 4일, BERT_LARGE는 64개의 TPU로 4일이 소요됐다.
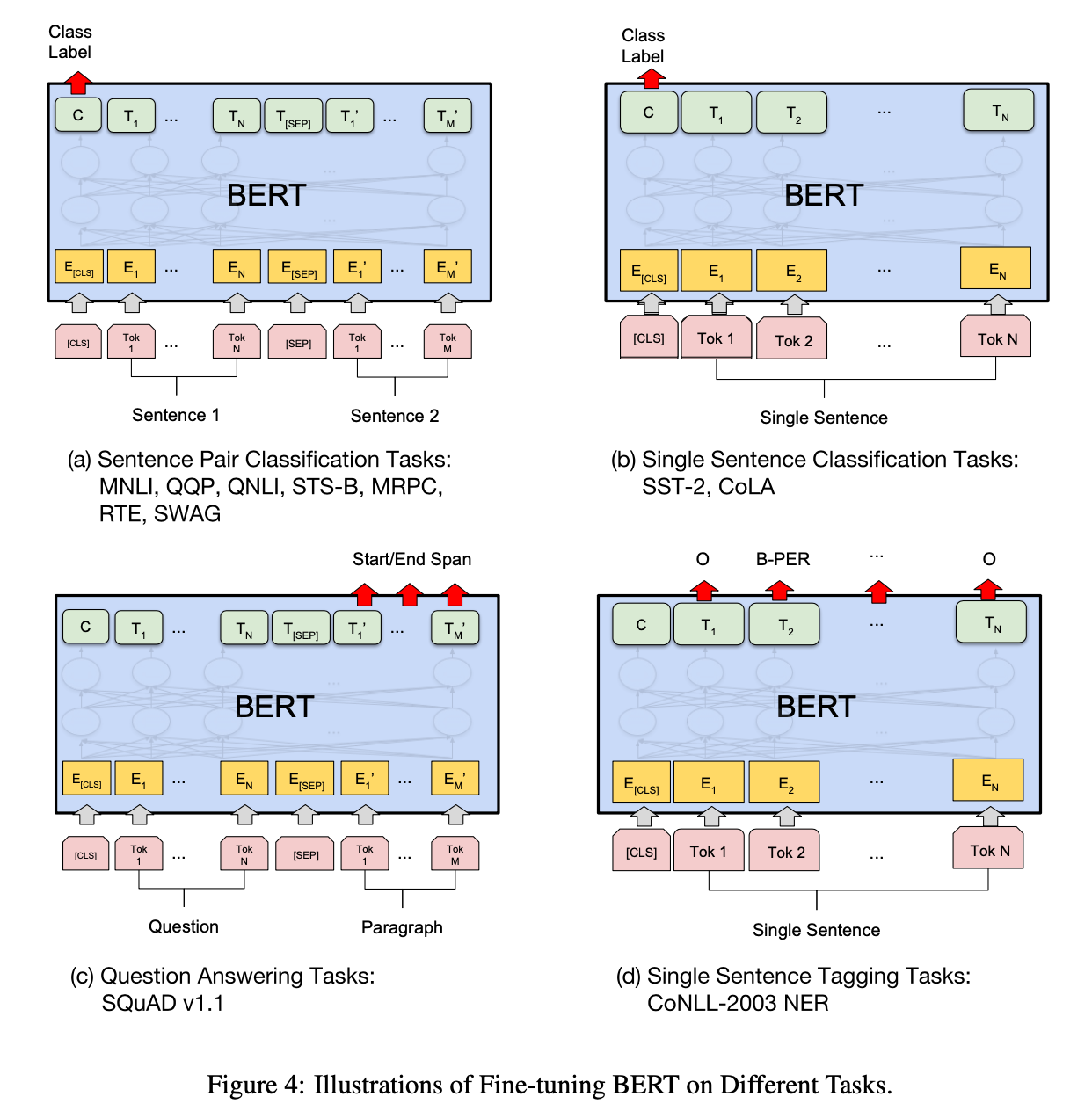
Fine-tuning
Fine-tuning은 Pre-training에 비해 매우 빠른 시간 내에 완료된다. Fine-tuning에서는 각각의 task에 specific하게 input size, output size 등을 조정해야 한다. 또한 token-level task일 경우에는 모든 token들을 사용하고, sentence-level task일 경우에는 CLS token을 사용한다.
Hyperparameters는 대부분은 pre-training과 동일하게 진행하는 것이 좋지만, batch size, learning rate, #epochs는 task-specific하게 결정해야 한다. 하지만 다음의 값들에 대해서는 대체적으로 좋은 성능을 보였다.
batch size: 16, 32
learing rate: 5e-5, 3e-5, 2e-5
#epochs: 2, 3, 4
dataset의 크기가 클 수록 Hyperparameter의 영향이 줄어들었으며, 대부분의 경우 Fine-tuning은 매우 빠른 시간 내에 완료되기 때문에 많은 parameters에 대해 테스트를 진행할 수 있었다.
Experiments
GLUE (General Language Understanding Evaluation)
GLUE 에 맞춰 fine-tuning을 진행한다. CLS token에 대응하는 hidden layer의 state 값이 h차원의 vector C라고 한다면, Classification을 위해 k x h (k는 classification할 label의 수) 차원의 weight matrix W를 생성한다.
\[log(softmax(CW^T))\]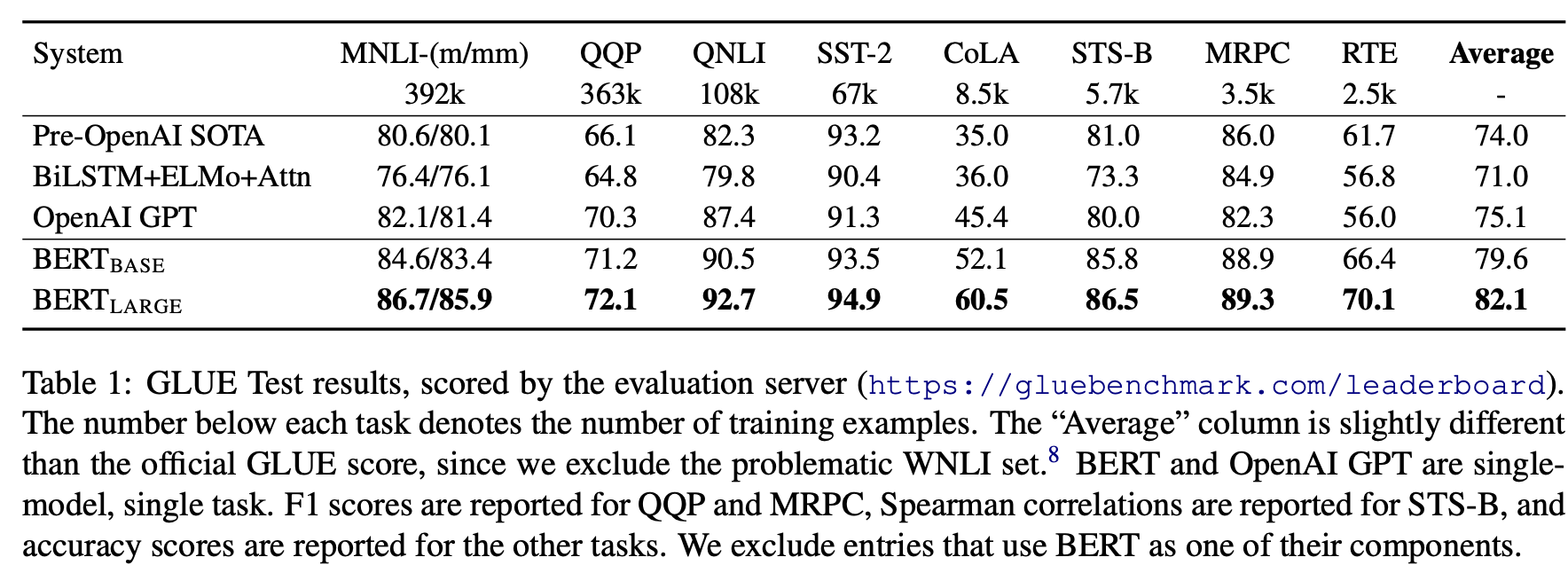
BERT_BASE는 L=12, H=768, A=12, #Parameters=110M이고, BERT_LARGE는 L=24, H=1024, A=16, #Parameters=340M이다. (L: Layer 개수, H: hidden size, A: self-attention head 개수)
batch size는 32, #epoch=3로 학습을 진행했다. learning rate는 5e-5, 4e-5, 3e-5, 2e-5 중 가장 잘 학습이 진행되는 것으로 선택했다. fine-tuning이 unstable한 경우가 있어서, random하게 restart하는 과정도 추가했다.
BERT model은 GLUE의 모든 task에서 SOTA를 달성했다. base, large 모두 다른 model들을 4.5~7%정도 능가했다. 또한 BERT_LARGE model이 BERT_BASE를 모든 경우에서 능가했다. Model의 크기가 클 수록 성능이 좋다는 의미이다.
BERT_BASE와 OpenAI GPT는 attention masking에서의 차이를 제외하고 모두 동일한 조건이었음에도 불구하고 4.5%의 성능 차이를 보였다. 이를 통해 unidirectional attention이 아닌 bidirectional attention을 적용한 것이 성능 향상에 매우 큰 기여를 했다는 것을 알 수 있다.
SQuAD v1.1
SQuAD에 맞춰 Fine-tuning을 진행한다. SQuAD는 Q&A dataset이다. fine-tuning 학습 과정에서 Answer 문장의 시작 token S와 끝 token E를 구해내게 된다. transformer layer의 마지막 state들을 이용해 해당 값이 S나 E일 확률을 구하게 되는데, S와 T_i를 dot product한 후 softmax로 확률값으로 변환한다.
\[P_i = \frac{e^{(S or E) \cdot T_i}}{\sum _j{e^{(S or E) \cdot T_j}}}\]위의 score를 이용해서 \(S \cdot T_i\)와 \(E \cdot T_j\)를 더한 값이 가장 큰 <i, j>쌍 (단, j ≥ i)을 최종 Answer 영역으로 정한다.
\[\hat s_{i,j} = max_{j \geq i}\left( S \cdot T_i + E \cdot T_j\right)\]SQuAD v2.0
SQuAD v1.1에서 대답이 불가능한 질문을 포함한 dataset이다. fine-tuning 학습 과정에서 CLS token을 이용해 대답 가능 여부를 Binary Classification하면서 token C를 구한다.
대답이 불가능할 경우의 Score는 다음으로 계산한다.
\[s_{null} = S \cdot C + E \cdot C\]대답이 가능한 경우의 Score는 SQuAD v1.1과 동일하다. 대답 가능 여부는 두 Score를 비교해 판단하게 된다. 이 때 threshhold값 r이 사용된다.
\[\hat s_{i,j} > s_{null} + r\]SWAG (Situations With Adversarial Generations)
일반적인 추론을 하는 dataset이다. sentence 1개에 추가적으로 4개의 sentence가 주어지고, 4개의 sentence 중 가장 적합한 것을 선택하는 task이다. 각각의 보기들에 대해 앞의 sentence와 묶어 segment embedding A, B를 부여한 data쌍을 만들어낸다. Score는 CLS token에 대응하는 token C와 task specific parameter 1개를 dot product한 뒤 softmax를 수행해서 구한다.
Ablation Studies
동일한 환경(pre-training data, fine-tuning scheme, hyperparameters)에서 특정 조건만을 변경해 어느 정도의 영향을 끼치는지 분석했다.
Effect of Pre-training Tasks
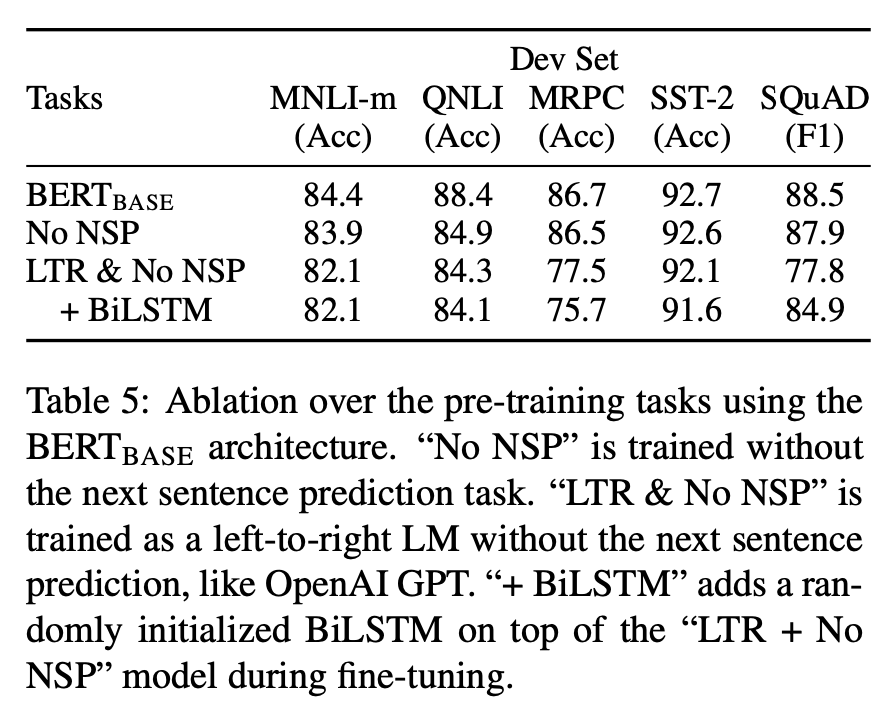
No NSP는 pre-training 단계에서 MLM만 수행하고, NSP는 수행하지 않은 model이다. LTR & No NSP는 NSP 는 수행하지 않고, MLM 대신 Left to Right의 Unidirectional attention을 적용한 model이다.
BERT와 No NSP를 비교함으로써 NSP Pre-training이 성능 향상에 영향을 끼친다는 것을 알 수 있다. 한편, No NSP와 LTR & No NSP를 비교함으로써 Bidirectional Attention(MLM)이 성능 향상에 매우 큰 영향을 준다는 것을 알 수 있다. Token Level에서 Right to Left Context 정보를 얻기 위해 MLM이 아닌 BiLSTM을 추가했다. 해당 Model은 LTR & No NSP에 비해 SQuAD와 같은 task에서 매우 큰 성능 향상을 보였지만, 여타 task에서는 오히려 성능 하락을 보였다.
물론 Bidirectional Context를 담기 위해 LTR과 RTL을 각각 학습시킨 뒤 두 token을 concatenation하는 방법도 있지만, 이는 비용이 2배나 높고, QA와 같은 RTL 학습이 불가능한 task에서는 적용이 불가능하다는 점, 결론적으로 MLM과 같은 Deep Bidirectional Model에 비해 성능이 낮다는 점에서 비효율적이다.
Effect of Model Size
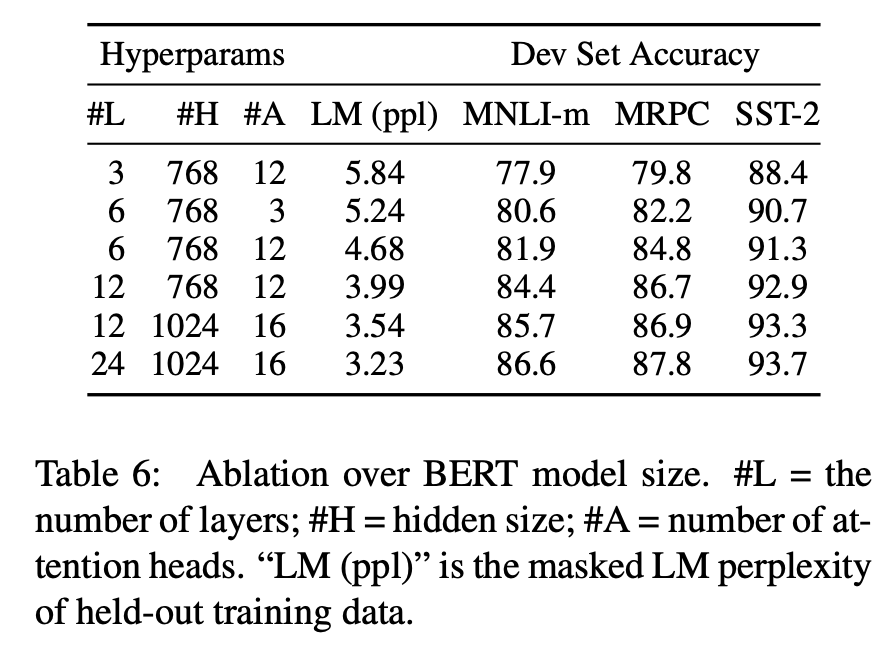
GLUE task 중 3개를 뽑아 Model Size에 따라 성능을 측정했다. Model Size가 증가할수록 성능이 높아지는 경향을 확인할 수 있다. 특히 MRPC task는 pre-training task와 차이가 큰 task이면서 3600개의 적은 labeled training data를 사용했음에도 불구하고 Model Size가 증가함에 따라 성능도 향상됐다. 이를 통해 Model Size의 증가는 번역과 Langauge Modeling과 같은 큰 scale의 task에서도 성능 향상에 기여함은 물론, 충분한 pre-training이 있었다는 전제 하에 작은 scale의 task에서도 성능 향상에 기여함을 알 수 있다.
Feature-based Approach with BERT
지금까지의 BERT는 모두 fine-tuning model이었다. Feature-based Approach가 갖는 장점은 크게 두 가지로 정리할 수 있다.
- Transformer Encoder의 Output에 몇몇 Layer를 추가하는 간단한 작업만으로는 해결할 수 없는 task들이 존재한다.
- 매우 큰 pre-training model의 경우 pre-trained된 features를 계속 update하지 않고 고정된 값으로 사용함으로써 연산량을 획기적으로 줄일 수 있다.
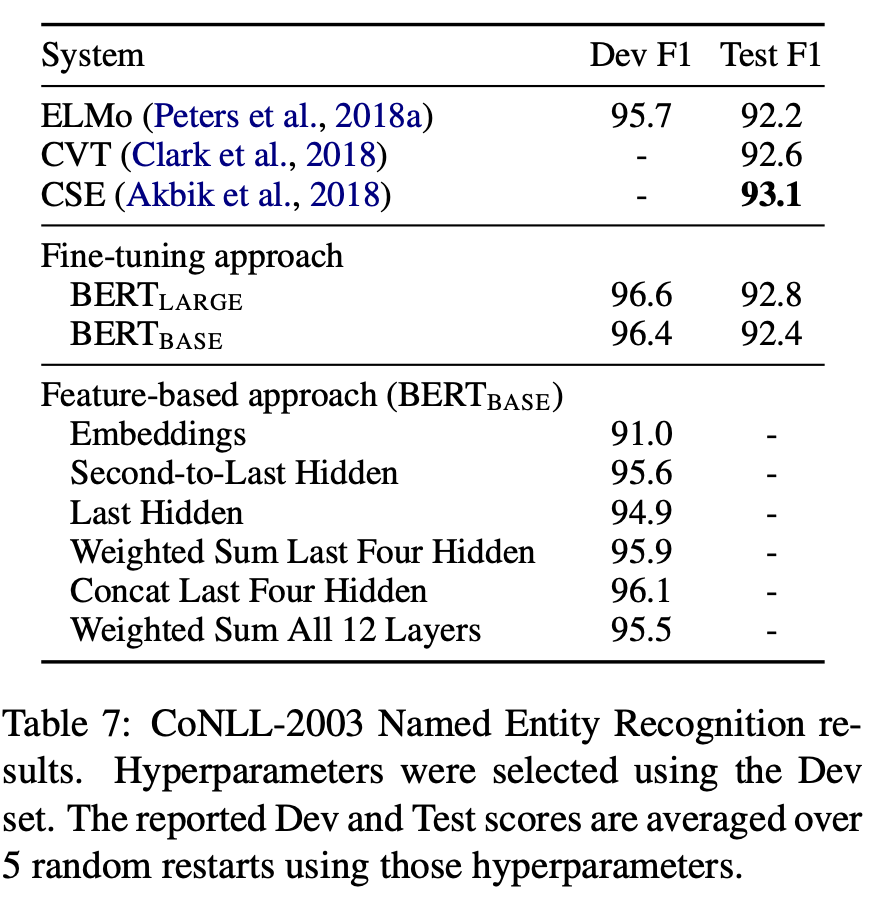
NER(Named Entity Recognition) task에 대해 Feature-based Approach를 적용해본다. Fine-tuning Step을 제거하고, Transformer Layer의 output을 그대로 768-dimensional BiLSTM의 input으로 사용한다. 그 뒤 classification layer를 통과시켜 결과를 도출해낸다. Fine-tuning Approach를 적용한 BERT_LARGE Model이 SOTA를 달성했지만, Fine-tunning을 적용한 BERT_BASE model과 Feature-based를 적용한 BERT_BASE Model의 F1 Score는 0.3밖에 차이가 나지 않는다. 연산량을 고려한다면 충분히 가치있는 결과이다. 결론적으로, BERT Model은 Fine-tunning Approach와 Feature-based Approach에서 모두 기존 Model들을 뛰어넘는다.
Effect of Number of Training Steps
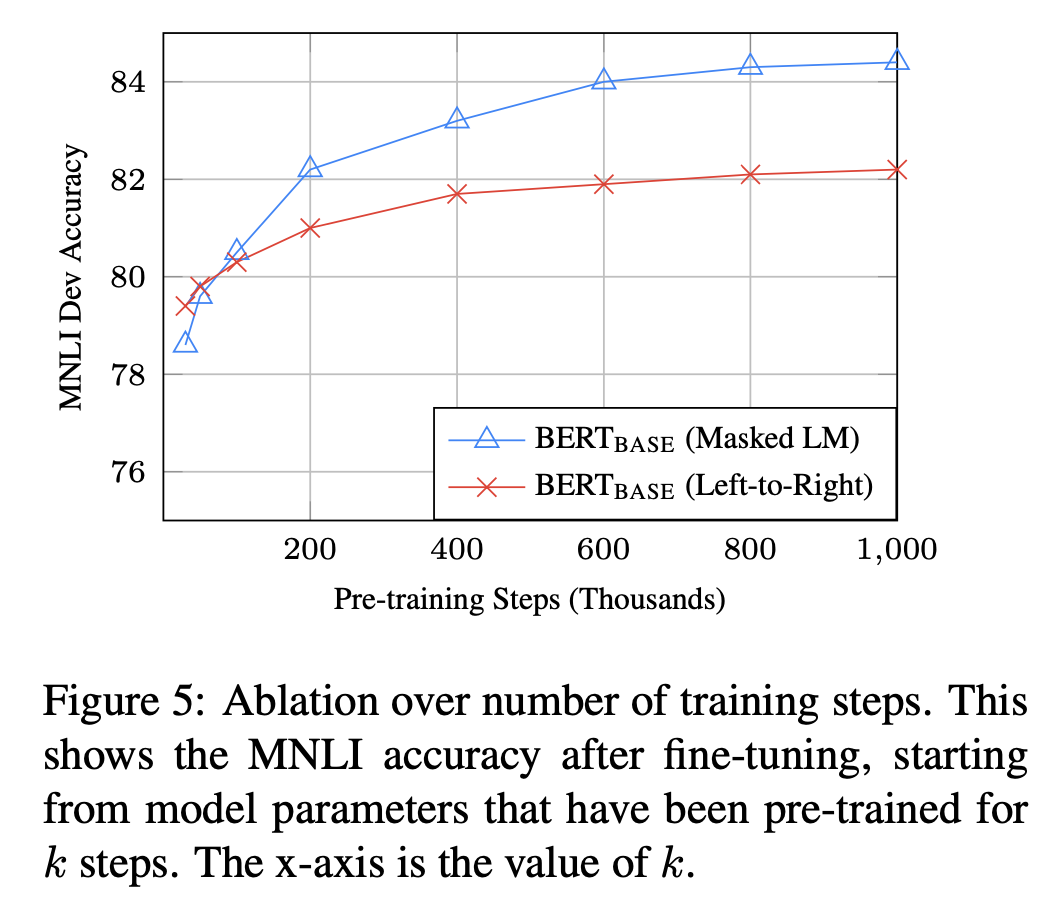
Training을 많이 수행할 수록 성능은 향상되지만, 일정 수준 이상을 지나면 점차 converge하게 된다. MLM과 LTR을 비교했을 때 MLM이 수렴이 더 늦게 일어나기 때문에 Training에 더 많은 시간이 소요된다고 볼 수 있다. 하지만 절대적인 성능 수치는 시작과 거의 동시에 LTR을 뛰어넘는다.
Different Masking Procedure
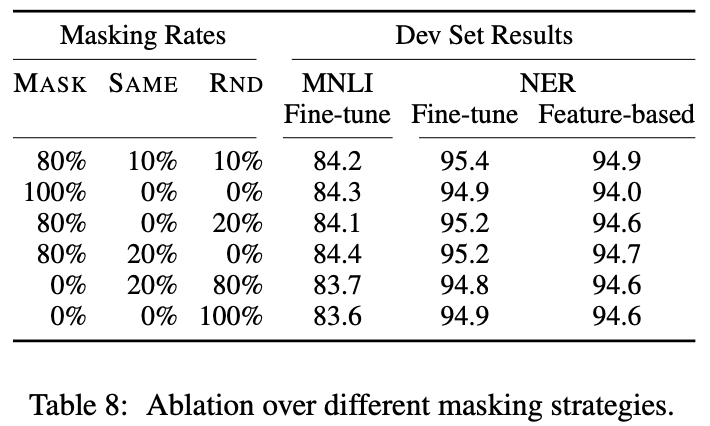
Masking Rate를 다르게 하며 성능을 비교해보자. MASK는 실제로 [MASK] token으로 변경된 비율을, SAME은 동일한 word로 남아있는 비율을, RND는 random한 다른 word로 변경된 비율을 뜻한다. BERT는 각각 80%, 10%, 10%를 채택했다. MASK가 100%나 RND가 100%인 경우에 성능이 최악이라는 것을 알 수 있다.