[NLP 논문 리뷰] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
31 Jan 2021
Paper Info
Submit Date: Oct 02, 2019
Abstract
본 논문에서는 Distilling Knowledge기법을 기존의 BERT model에 적용해 훨씬 작은 크기, 빠른 속도를 가지면서 비슷한 성능을 보이는 DistilBERT model을 제안한다. 이전의 knowledge distillation은 task-specific한 model(대개 supervised learning)에 적용되었다면, 본 논문에서는 BERT model의 pre-train(unsupervised learning)에 이를 적용했다. 그 결과 기존의 BERT model보다 40% 작은 크기를 가지면서 97%의 capability를 보존하고, 60% 빠른 model을 개발했다. 이 과정에서 language modeling, distillation, cosine-distance loss의 3개의 loss를 결합해 사용했다.
Introduction
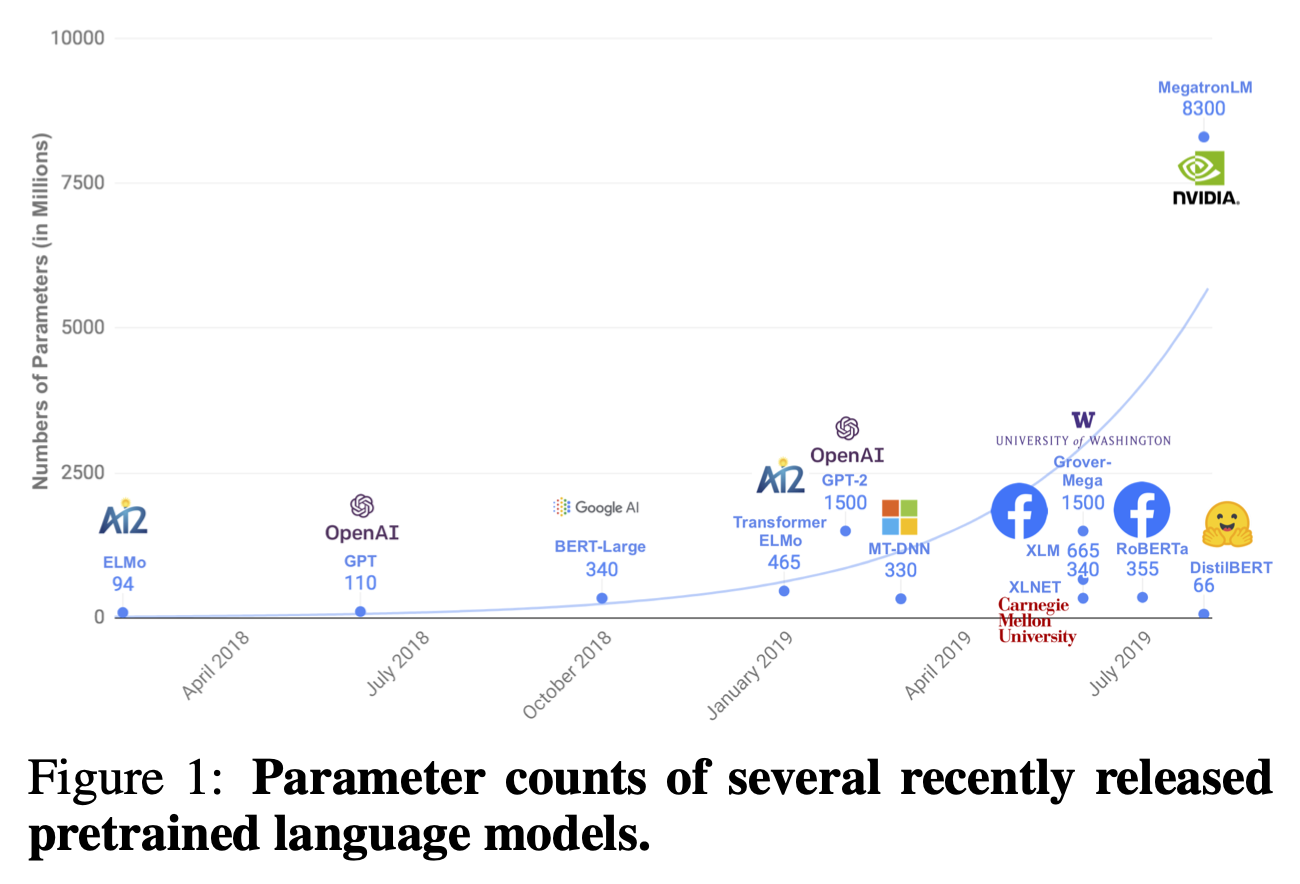
최근 NLP domain에서는 BERT를 기반으로 한 대규모 pre-train model이 기본이 되었다. 그 결과 비약적인 성능 향상이 있었지만, 동시에 model의 크기도 함께 급속도로 증가했다. 이러한 대규모 model은 on-device에서 real-time에 service되어야 하는 경우에는 사용하기 곤란하다는 치명적인 단점이 있다. 본 논문에서는 이를 해결하고자 BERT model에 knowledge distillation을 적용해 규모는 줄이고, 속도는 향상시키면서 성능은 보존하고자 한다.
Knowledge distillation
Distilling the Knowledge in a Neural Network를 참고하자.
DistilBERT: a distilled version of BERT
Student architecture
Student BERT model은 BERT에서 NSP를 완전히 제거한 것이다. 따라서 token type embedding(segment embedding)을 제거하고, 마지막 pooler 역시 제거한다. 그리고 layer의 수 역시 절반으로 줄인다. Transformer architecture에서 사용하는 layer normalisation이나 linear layer는 modern linear algebra framework에 의해 최적화되어 있기 때문에 dimension을 줄이는 것은 생각보다 성능에 큰 영향을 미치지 않는다. 따라서 layer의 수를 줄이는 것이 직접적으로 연산량을 줄일 수 있기에 이 방법을 사용했다.
Distillation
training에서 3가지의 loss를 사용해 학습한다.
- soft target loss (\(L_{ce}\))
-
수식
\[L_{ce}=\sum_i{t_i *\log{(s_i)}}\]- \(t_i\): teacher model의 output(soft target), \(s_i\): student model의 output
- temperature \(T\) 사용
-
- hard target loss (\(L_{mlm}\))
- BERT에서 사용하는 일반적인 MLM(Masked Language Model) loss
- dynamic masking 사용
- cosine embedding loss (\(L_{cos}\))
- teacher model과 student model의 hidden vector들의 direction을 align하는 효과
Data and compute power
original BERT와 동일한 corpus를 사용해 학습했다. 16GB V100 GPU 8개를 사용해 90시간동안 학습을 수행했다.
Experiments
GLUE
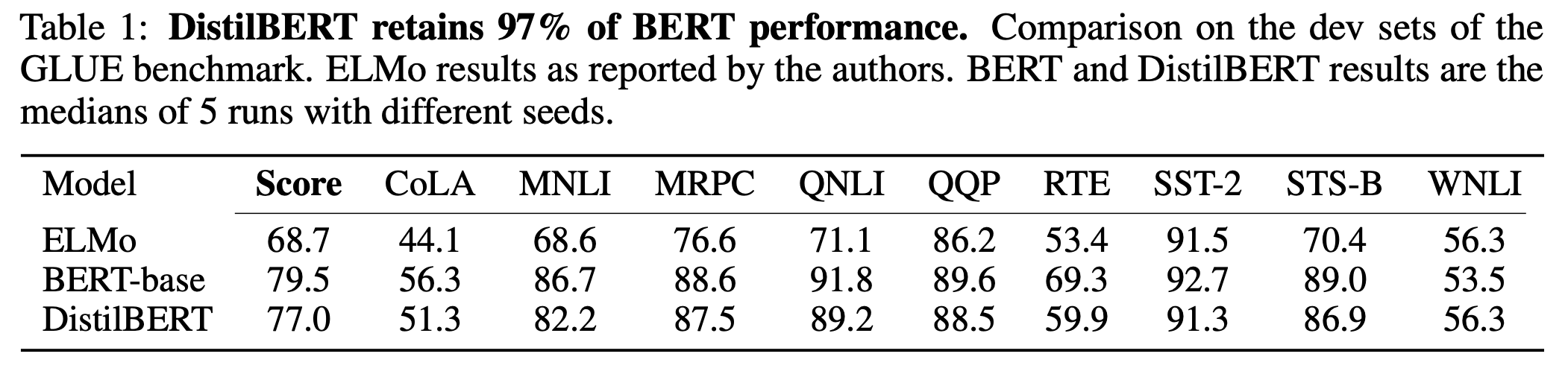
2개의 BiLSTM을 사용한 ELMo model과 original BERT와 GLUE로 성능을 비교했다. 9가지 task의 평균 성능은 BERT-base와 DistilBERT가 모두 ELMo보다 훨씬 좋은 수치를 보여줬고, DistilBERT는 BERT-base에 비해 2.5% 낮은 성능을 달성했다.
Dowmstream task benchmark
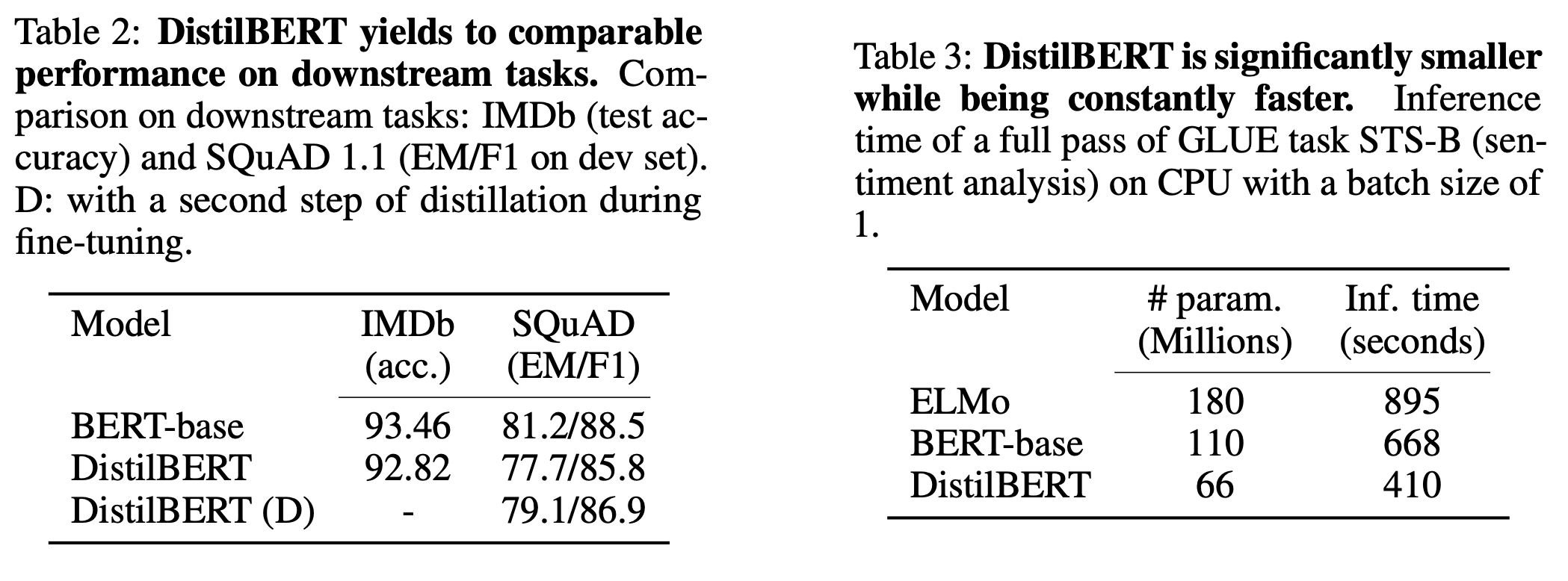
IMDb와 SQuAD를 사용해 downstream task에서의 성능을 비교했다. DistilBERT는 두 task 모두에서 BERT-base에 거의 근접한 accuracy와 F1 Score를 달성했다. 특히 SQuAD에 대해서는 fine-tuning 단계에서도 fine-tuning된 BERT-base model을 teacher model로 해 추가적으로 knowledge distillation을 수행했는데 추가적인 성능 향상이 발생했다.
실제로 inference time을 비교했는데 batch size=1인 상황에서 DistilBERT는 BERT-base보다 60% 빠른 성능을 보였다. on-device에서의 성능도 비교했는데, iPhone 7 Plus에서 실험을 진행한 결과 tokenization을 제외한 시간이 DistilBERT가 71% 더 빨랐다. 전체 model의 size는 총 207MB로 mobile device의 memory에 올리기 충분했다.
Ablation study

triple loss의 세 요소를 제거하며 실험을 진행했다. \(L_{mlm}\)(hard target loss)가 제일 영향이 적었고, \(L_{cos}\), \(L_{ce}\) 순서로 영향력이 작었다. 또한 weight initialization을 random하게 수행할 경우에는 성능 하락이 제일 크게 발생했다.
Conclusion
DistilBERT는 original BERT model보다 40% 작고, 60% 빠르면서도 97%의 capability를 보존했다. 기존의 knowledgd distillation에 cosine loss를 추가한 triple loss를 사용해 추가적인 성능 향상도 달성했다.