Paper Info
Submit Date: Mar 09, 2015
Abstract
Machine Learning이 발전하면서 model의 크기는 급격하게 커지는 경향을 보여왔다. 특히나 ensemble과 같은 기법을 사용할 경우에는 더욱 심하다. 그러나 이러한 대규모 model은 연산이 비용이 과도하게 크다는 문제점 때문에 실시간으로 수행되어야 하는 작업에 있어서는 적용되기 힘들다. 본 논문에서는 이러한 대규모 model을 하나의 작은 model로 압축해 동등한 수준의 성능을 내는 방법론을 제시했다.
Introduction
많은 사람에게 실시간으로 제공되어야 하는 service에는 대규모 model을 사용하기 곤란하다. latency도 높고, computing 자원을 많이 소모하기 때문이다. 이를 해결하기 위해 대규모 model을 작은 model로 축소시키는 연구가 과거부터 수행되어왔는데, 특히나 대규모 ensemble model의 결과를 하나의 small model로 transfer하는 연구가 주목할 만 하다. 많은 연구자들이 이러한 접근이 불가능하다고 생각했지만, 이는 model이 도출해내는 knowledge와 model의 parameter value를 완전히 동일시 여기는 관점이 가로막은 것이지, 실제로는 model의 form을 변형하더라도 같은 knowlege를 도출해낼 수 있다.
model을 학습하는 목적은 무엇일까? 결국 real data (unseen data)에 대해서 좋은 성능을 내기 위함이다. 이를 위해서는 training data에서 general한 특성을 뽑아내 학습해야 한다. 하지만 실제로는 model은 train data 내부의 special한 특성까지 학습을 하려 한다. 이를 차단하는 것이 좋은 학습이라고 할 수 있다. classification task를 생각해봤을 때, 마지막의 softmax logit의 값은 대개 정답 category의 값만이 높은 확률값을, 나머지 category 값들은 모두 낮은 확률값을 갖는다. 그러나 정답이 아닌 category 값들 역시 충분한 의미를 갖는데, 모두 다 동일하게 작은 값이 아닌, 그 중에서도 어떠한 category의 값은 다른 수치에 비해 높은 값을 가질 것이다. 그렇다면 그 data는 해당 category가 정답은 아닐지언정, 해당 category와 어느정도의 유사성을 갖는다고 이해할 수 있다. 이렇게 data 사이의 상관 관계를 찾아내는 것이 data의 general한 특성을 학습하는 것인데, 안타깝게도 실제로 model을 학습할 때에는 해당 값들은 0에 가까운 값이기에 여타 다른 값들과 함께 사실상 무시되고는 한다. 본 논문에서는 이를 해결하기 위해 temperature 개념을 도입한다. softmax 함수에 값을 그대로 넣지 않고 temperature \(T\)로 나눈 값을 넣는 것이다. \(T=1\)일 때에는 기존 softmax와 완전히 동일하지만, \(T\)가 점차 증가할수록 더 soft한 값이 나오게 된다.
구체적으로 large model의 knowledge를 small model로 distilling하는 방법은 large model의 최종 softmax output을 ‘soft target‘으로 지정해 small model의 학습 과정에서 사용하는 것이다. 결론적으로 small model은 2개의 target을 갖는데, large model의 output인 soft target과, 원래의 label 값인 hard target이다. 두 가지 target에 대해 loss를 계산하며 학습을 해나가게 된다. soft target과 hard target를 직관적으로 이해해보면 hard target은 ‘이상향‘이고, soft target은 ‘현실‘이다. classification task라고 가정했을 때 hard target은 대개 one-hot encoding 방식일 것이다. 가장 완벽한 이상적인 model은 모든 data에 대해 정답 category는 1, 그 외 category는 모두 0으로 예측해내겠지만 이는 현실에는 존재할 수 없다. 결국 hard target은 현실적이지 않은 objective인 것이다. 반면, soft target은 실제로 model이 학습을 통해 도출해낸 결과값이다. 즉, model이 충분히 도출해낼 수 있는 수준의 값이다. 그렇기에 새로운 model(본 논문에서는 small model)을 학습시킬 때 현실적인 objective로 채택할 수 있는 것이다.
Distillation
\[q_i=\frac{exp\left(z_i/T\right)}{\sum_j{exp\left(z_j/T\right)}}\]본 논문에서 사용하는 모든 softmax 함수는 temperature \(T\)가 도입된 위와 같은 형태로 변경한다. 학습 과정은 다음과 같이 이루어진다.
- training set (x, hard target)을 사용해 large model을 학습한다.
- large model이 충분히 학습된 뒤에, large model의 output을 soft target으로 하는 transfer set(x, soft target)을 생성해낸다. 이 때 soft target의 \(T\)는 1이 아닌 높은 값을 사용한다.
- transfer set을 사용해 small model을 학습한다. \(T\)는 soft target을 생성할 때와 같은 값을 사용한다.
- training set을 사용해 small model을 학습한다. \(T\)는 1로 고정한다.
각각의 loss function은 모두 Cross-Entropy-Loss를 사용한다. 결국, small model의 최종 loss function은 soft target과의 Cross-Entropy-Loss + hard target과의 Cross-Entropy-Loss가 된다.
Preliminary experiments on MNIST
간단한 MNIST 대규모 model을 만들고, 이를 통해 transfer set을 생성해 small model을 학습시켜 실험을 진행했다. large model은 각각 #unit=1200인 2개의 hidden layer를 포함한 간단한 FC model으로, drop out을 포함한다. 60,000개의 training set을 사용해 학습을 진행했다. small model은 #unit=800인 hidden layer 2개로 구성되고, drop-out을 수행하지 않는 model이다. large model은 test set에서 67개의 error가 발생한 반면, small model은 146개의 error가 발생했다. 하지만 여기서 small model에 transfer set을 사용해 추가적인 학습을 진행하면 74개의 error로 대폭 감소했다. 이 때 \(T=20\)을 채택했다.
model의 크기를 줄여가며 추가적인 실험을 진행했는데, #unit=300일 때에는 \(T\geq8\)일 때에, #unit=30일 때에는 \(2.5\le T \le 4\)일 때에 가장 좋은 성능을 보였다. 이를 통해 model의 크기가 작아질수록 \(T\) 역시 함께 작아져야 좋은 성능을 보장한다는 것을 알 수 있다. 직관적으로 생각해보면, model의 크기가 크다는 것은 #parameters가 많다는 것이고, 이는 결국 smooth하지 않은 function이라는 것이다. 따라서 generalize가 아닌 overfitting될 가능성이 더 높다는 것인데, \(T\)는 output을 더 soft하게 만들어주는 것이므로 overfitting을 방지하는 효과라고 이해할 수 있다. 따라서 model의 크기가 클 수록 overfitting이 발생할 가능성이 높은 것이므로 높은 \(T\)를 줘 강하게 soft 효과를 주는 것이 좋은 성능을 낼 것이라는 것을 유추할 수 있다.
Soft Targets as Regularizers
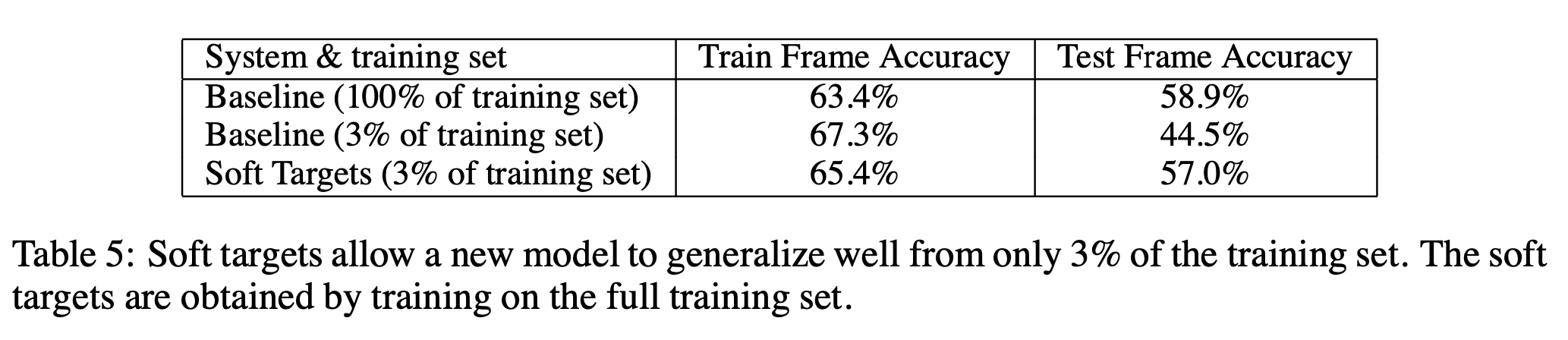
soft target은 regularization 효과를 낼 수 있다. soft target에는 hard target에는 담을 수 없는 유용한 정보들이 포함되어 있는데, 이 정보들이 overfitting을 방지하는 효과를 가져다준다. 위 table은 660M example을 포함하는 dataset에 대해 학습을 할 때, hard target과 soft target으로 성능을 측정한 것이다. 기본적으로 hard target으로 모든 data에 대해 학습을 수행했을 때에 최종 test accuracy는 58.9%가 도출됐다. 이후 방대한 양의 dataset 중 임의로 일부분만을 추출해 학습을 진행했는데, 3%(20M)개로 학습을 진행한 결과 최종 test accuracy는 44.5%가 도출됐다. 학습 도중 early stopping을 사용했음에도 overfitting이 발생한 것이다. 하지만 100%의 training set에서 soft target을 추출해내 그 중 3%만을 갖고 학습을 진행했을 때에는 test accuracy가 57.0%에 달했다. 심지어 이 경우에는 early stopping을 사용하지 않았음에도 자연스럽게 accuracy가 수렴했다. soft target을 사용해 overfitting이 아닌 generalize한 특성을 제대로 학습한 것이다. 이는 전체 dataset에 대해 hard target으로 학습을 진행한 성능과 비슷한 수치를 보여줬다는 사실을 통해 유추 가능하다.