Paper Info
Submit Date: Jan 16, 2013
Introduction
one-hot encoding 방식은 word를 단순하게 표현하는 방법이다. word 자체가 갖는 정보를 담고 있지 않고 단순하게 index만을 담고 있는데, index 역시 word에 내재된 어떤 정보와도 관련이 없다. 본 논문에서는 word vector에 word 자체가 담고 있는 의미를 확실하게 담아내고자 했다. 구체적으로, 단순하게 유사한 단어들이 vector 공간에서 가까운 거리를 갖는 것에 그치지 않고 syntax, semantic 관점에서의 다양한 similarity를 반영하고자 했다. 동시에 one-hot encoding의 단점인 sparse vector problem을 해결해 dimension이 작으면서도 distribute한 word vector를 생성해냈다. 그 결과 sentence에서 단어가 등장하는 위치가 비슷한 word들의 vector가 가깝게 위치하는 것은 물론(syntax), “King” - “Man” + “Woman” = “Queen” 과 같은 vector 연산까지 정확하게 수행해낼 수 있었다(semantic).
Model Architectures
여러 model들을 비교하기 위해서 우선 computational complexity를 정의한다. model의 computational complexity는 #parameters로 정의한다. training complexity는 \(E \times T \times Q\)로 정의하는데, \(E\)는 #epochs이고, \(T\)는 len(training dataset), \(Q\)는 model specific하게 정의된 value이다.
Feedforward Neural Net Language Model (NNLM)
-
example: “what will the fat cat sit on”, \(N=4\)
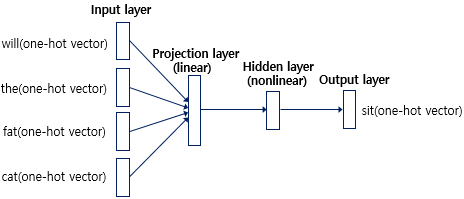
\(N\): input word 개수
\(V\): vocabulary size
\(D\): word representation dimenstion
\(H\): hidden layer size
일반적인 feed forward neural network를 사용한 language model이다.
이전의 단어들 중 \(N\)개의 word에 대한 one-hot encoding을 input으로 받는다. 이 때 \(N\)은 n-gram에서의 \(N\)과 유사한 의미이며, hyper-parameter이다.
각각의 input word에 대해 weight matrix \(W_P\)(\(V \times D\))를 곱한다. one-hot encoding과 \(W_P\)를 곱하는 것은 one-hot encoding에서 1인 index를 사용해 \(W_P\)에서 해당 row만 뽑아내는 것과 동일하다. 즉, \(W_P\)를 lookup table로 사용하는 것이다.
이렇게 \(D\) 차원의 word vector를 얻어내는데, input에 대한 word vector들을 모두 concatenate해 projection layer \(P\)(\(N \times D)\)를 만들어낸다. 이는 여러 word에 대한 input을 하나의 matrix로 표현한 \(X\)(N \times V\()와\)W_P$$를 곱하는 연산과 동일하다. 이러한 연산의 의미를 직관적으로 이해해보자면 one-hot word vector가 아닌 embedding word vector를 얻는 과정이라고 볼 수 있다.
이후 projection layer \(P\)에 새로운 weight matrix \(W_H\)(\(D \times H\))를 곱한 뒤 activation function에 넣어 hidden layer를 생성해낸다. 이는 여러 word embedding vector를 하나의 vector로 축약시키는 과정이다.
hidden layer에서는 softmax와 cross entropy loss를 사용해 output에 대한 one-hot vector를 만들어낸다.
전체 과정의 computational complexity는 다음과 같다.
\[Q = N \times D + N \times D \times H + H \times V\]위 수식에서 가장 부하가 큰 연산은 hidden layer에서 output을 만들어내는 연산인 \(H \times V\)이지만 hierarchical softmax를 사용하게 되면 \(H \times \log_2{V}\)로 연산량을 줄일 수 있다. 이 경우에는 가장 부하가 큰 연산은 projection layer에서 hidden layer를 만들어내는 연산인 \(N \times D \times H\)가 된다.
Recurrent Neural Net Language Model (RNNLM)
RNN을 사용한 language Model이다. RNN의 경우에는 projection layer를 제거한다. 또한 고정된 개수의 word만을 input으로 받는 NNLM과 달리 이전의 모든 word들에 대한 정보를 recurrent하게 hidden layer에 담게 된다.
전체 과정의 computational complexitiy는 다음과 같다.
\[Q=H \times H + H \times V\]\(D\)를 \(H\)와 동일하게 만들었기 떄문에 위와 같은 수식이 된다. 역시나 동일하게 hierarchical softmax를 사용하면 \(H \times V\)를 \(H \times \log_2{V}\)로 줄일 수 있다. 이 경우네는 가장 부하가 큰 연산은 \(H \times H\)가 된다.
New Log-linear Models
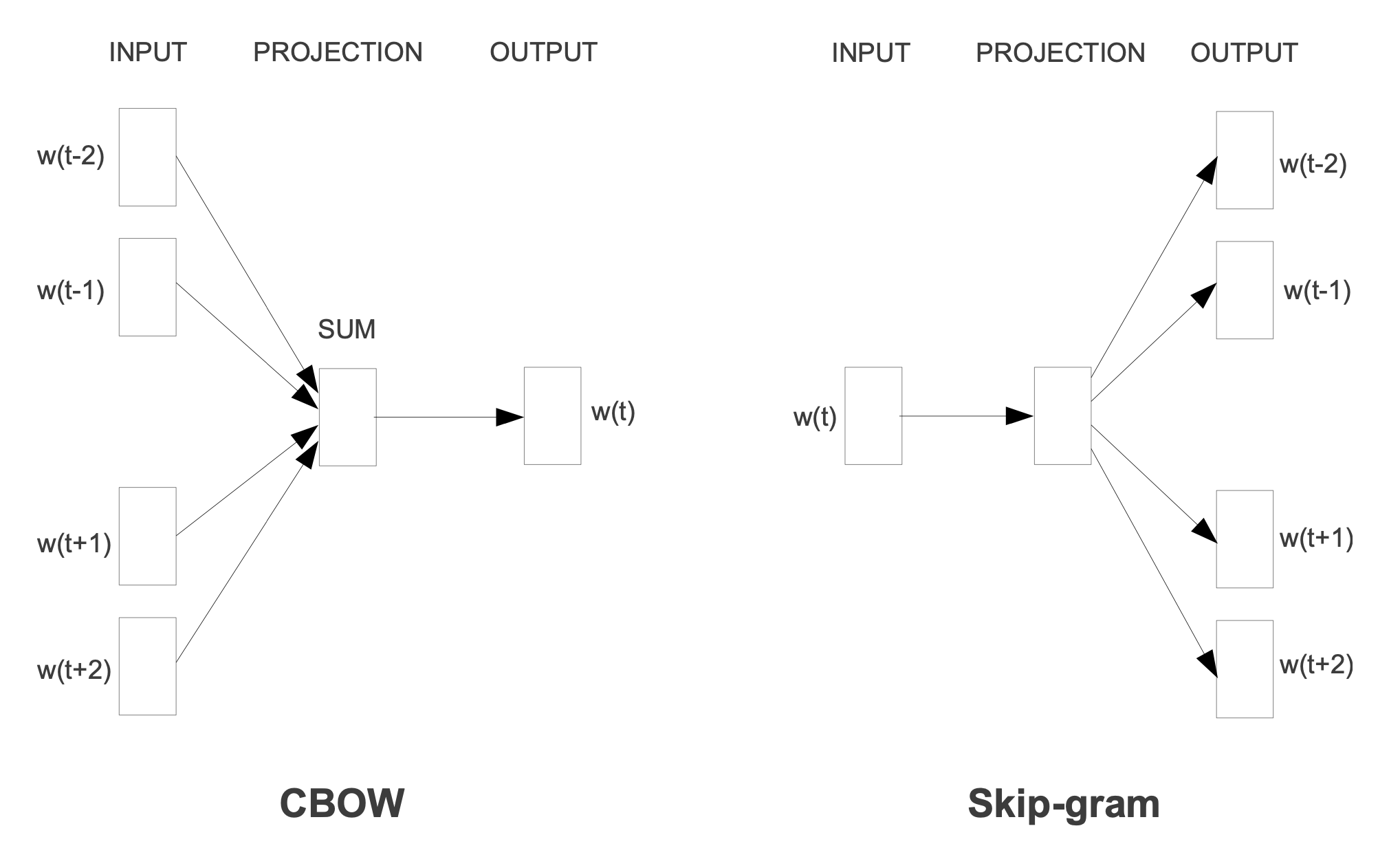
computational complexity를 줄이기 위해 2가지 단계를 제안한다. continuous bag-of-words model(CBOW)을 사용하는 단계와 continuous skip-gram model(Skip-gram)을 사용하는 단계이다.
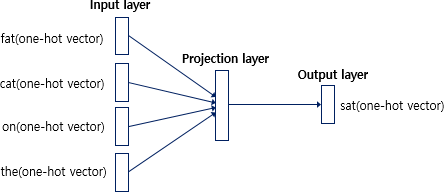
Continuous Bag-of-Words Model
출처: https://wikidocs.net/22660
NNLM에서 hidden layer를 제거한것이다. CBOW의 목표는 NNLM과 동일하게 word vector 1개를 예측하는 model이다. 다만 NNLM에서는 이전 word들만을 사용해 다음 word를 예측했다면, CBOW에서는 양방향(이전/이후)의 word 총 \(N\)개를 사용해 예측을 진행한다.
CBOW는 NNLM에 비해 computational complexity를 감소시켰는데, NNLM에서의 projection layer는 activation function을 사용하지 않는 linear layer였다. 반면 hidden layer는 activation function을 사용하는 non-linear layer였다. hierarichial softmax를 사용한다는 가정 하에 가장 연산량이 많이 소요되는 layer가 hidden layer였으므로 이를 제거해 전체 연산량을 줄인 것이다. NNLM에서 hidden layer의 존재 의미는 여러 word embedding vector를 하나의 vector로 압축하는 것이었다면, CBOW에서는 이를 non-linear layer를 거치지 않고 단순하게 평균을 내게 된다. 따라서 CBOW의 projection layer는 word embedding vector(\(W_p\)에서의 row)들의 평균이다.
computational complexity는 다음과 같다.
\[Q = N \times D + D \times \log_2{V}\]Continuous Skip-gram Model
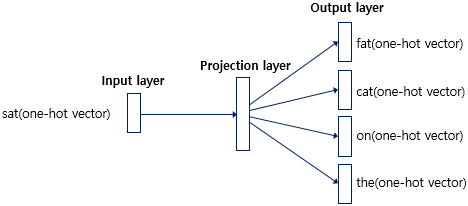
출처: https://wikidocs.net/22660
CBOW와 유사하지만 input/output이 서로 뒤바뀐경우이다. 현재 word를 통해 이전, 이후의 word를 예측하는 model이다. 여러 word에 대해 prediction을 수행하기 때문에 당연하게도 연산량은 CBOW에 비해 많다. 하지만 skip-gram은 input word vector를 평균내지 않고 온전히 사용하기 때문에 등장 빈도가 낮은 word들에 대해 CBOW 대비 train 효과가 크다는 장점이 있다. CBOW에서는 각 word vector들을 평균내서 사용하기 때문에 등장 빈도가 낮은 word들은 제대로 된 학습을 기대하기 힘들다.
computational complexity는 다음과 같다.
\[Q = C \times ( D + D \times \log_2{V})\]새로운 variable \(C\)가 등장하는데 \(C\)는 predict할 word의 개수와 관련된 값이다. 구체적으로, \(C\)는 predict할 word와 현재 word의 maximum distance이다. \([1,C)\)의 범위에서 random하게 value \(R\)을 뽑고, 현재 word 이전 \(R\)개, 이후 \(R\)개의 word에 대해서 predict를 수행한다. \(R\)의 기댓값은 \(\frac{1+(C-1)}{2}=\frac{C}{2}\)이고, predict 수행 횟수는 \(2R=2\times\frac{C}{2}=C\)이므로 전체 computational complexity는 1회 수행할 때의 값에 \(C\)를 곱한 것이다.
Results
word embedding의 성능을 측정하던 기존의 방식들은 유사한 word를 찾아내는 것이 대부분이었다. 예를 들면 “France”와 “Italy”가 유사한지를 측정하는 것 등이다. 본 논문에서는 이러한 방식에서 한 발 더 나아가 word 사이의 상관 관계를 뽑아내 다른 word에 적용시키는 방식을 도입했다. 예를 들면 “big”-“biggest”와 유사한 상관 관계를 갖는 word를 “small”에 대해 찾아 “smallest”를 맞추는 것이다. 본 논문에서 제시한 model로 학습한 word vector는 단순한 algebraic operation으로 이러한 task를 해결할 수 있다. X = vector(“biggest”) - vector(“big”) + vector(“small”)을 수행하면 X=vector(“smallest”)가 나올 것이다.
이와 같은 semantic한 의미까지 제대로 담은 word vector를 활용할 경우 수많은 NLP task에서 뛰어난 성능 향상을 보이게 된다.
Task Description
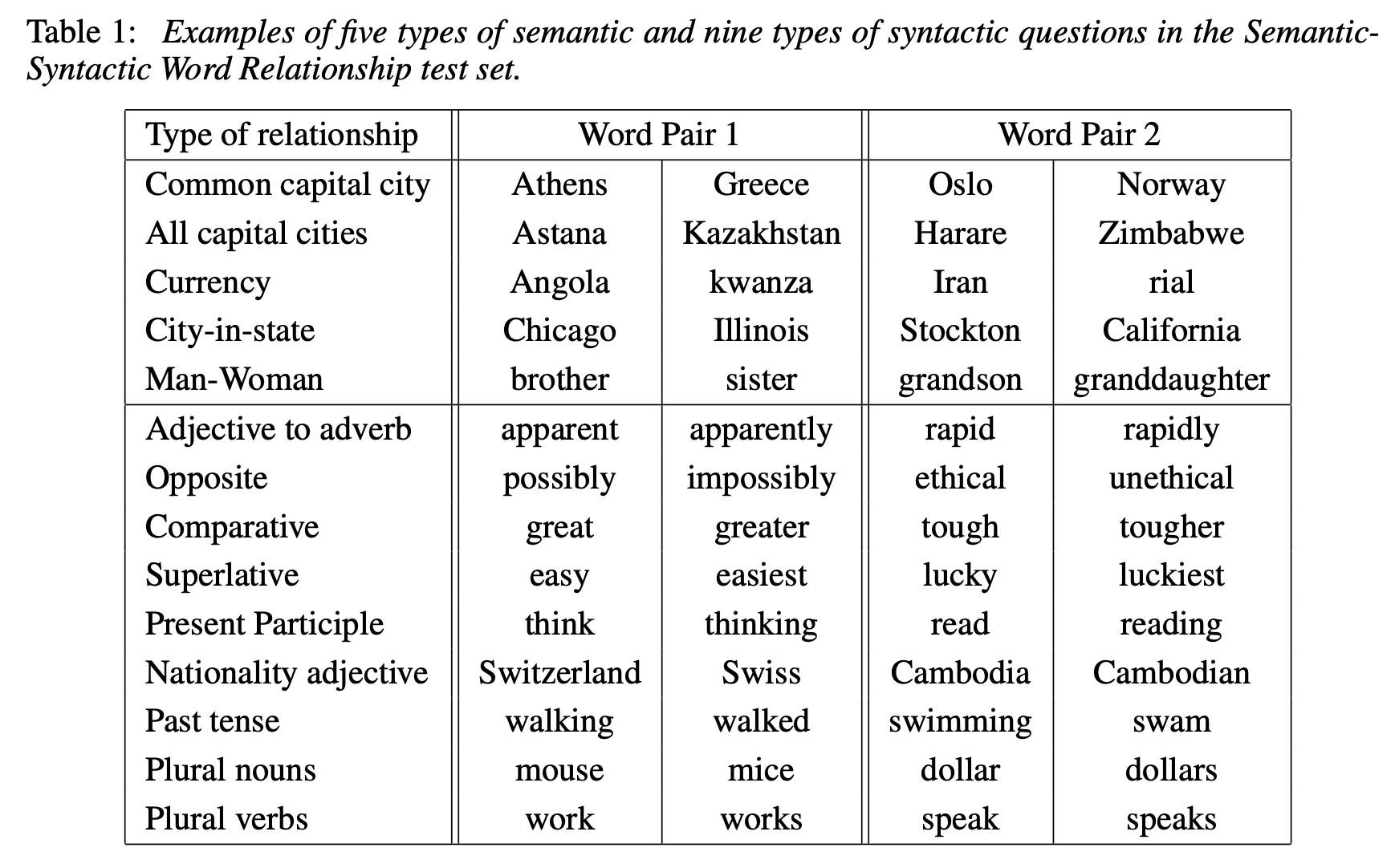
위와 같은 semantic, syntax 관계들을 목록화시켰다. 각 관계들에 대해 직접 word pair들을 수집하고, 각 word pair를 모두 섞어 random한 pair들을 만들어낸다. 이렇게 생성해낸 dataset으로 test를 수행하는 것이다. 이 때 정답과 완전히 동일한 word를 예측한 경우에만 정답으로 간주한다. 동의어나 유사어에 대해서도 오답 처리를 하기 때문에 사실상 100% accuracy는 불가능한 task이다.
Maximization of Accuracy
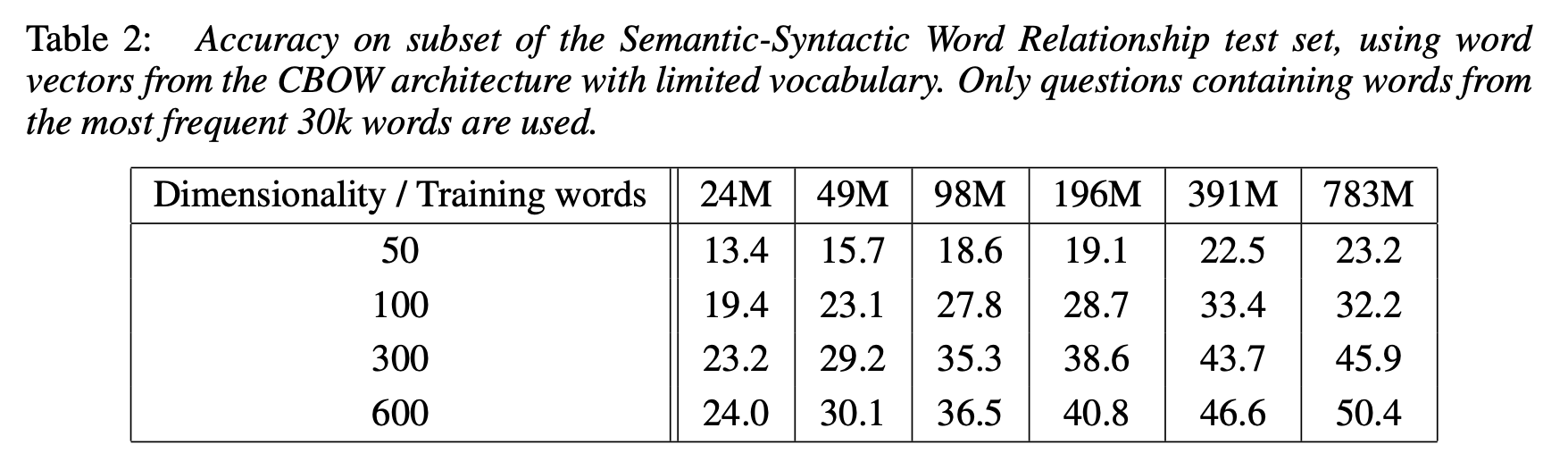
word vector의 dimension과 #training words를 통해 실험을 진행했다. dimensionality나 #training words 중 하나를 고정시킨 뒤 다른 하나만을 증가시킬 경우 일정한 수준 이상으로 accuracy가 증가하지 않는 현상을 보였다. 기존의 많은 연구에서 단순히 training dataset의 크기만을 늘려가며 성능을 높이려 했지만, 많은 word가 train된다면 이에 대한 정보들을 담을 수 있는 충분한 dimension이 확보되어야 한다는 사실을 알 수 있다.
Comparison of Model Architectures
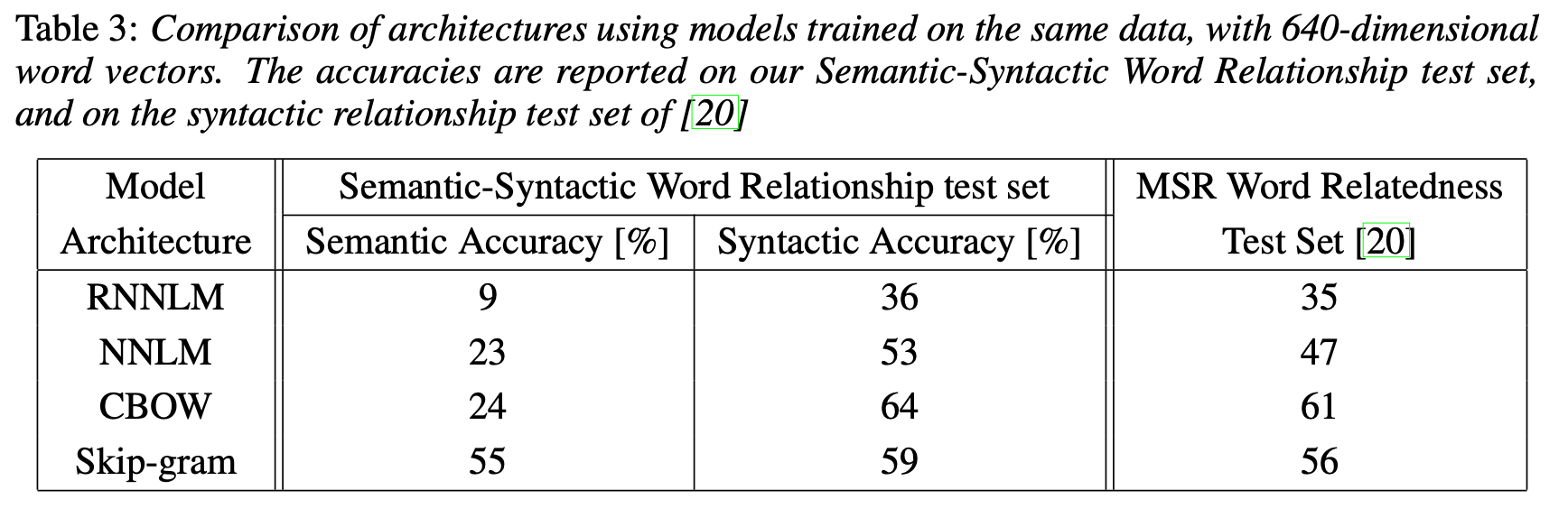
RNNLM이 가장 낮은 성능을 보였다. CBOW와 Skip-gram은 semantic, syntactic, relatedness에서 모두 NNLM을 능가했다. 특히나 Skip-gram은 Semantic Accuracy에서 다른 model들을 압도했다.
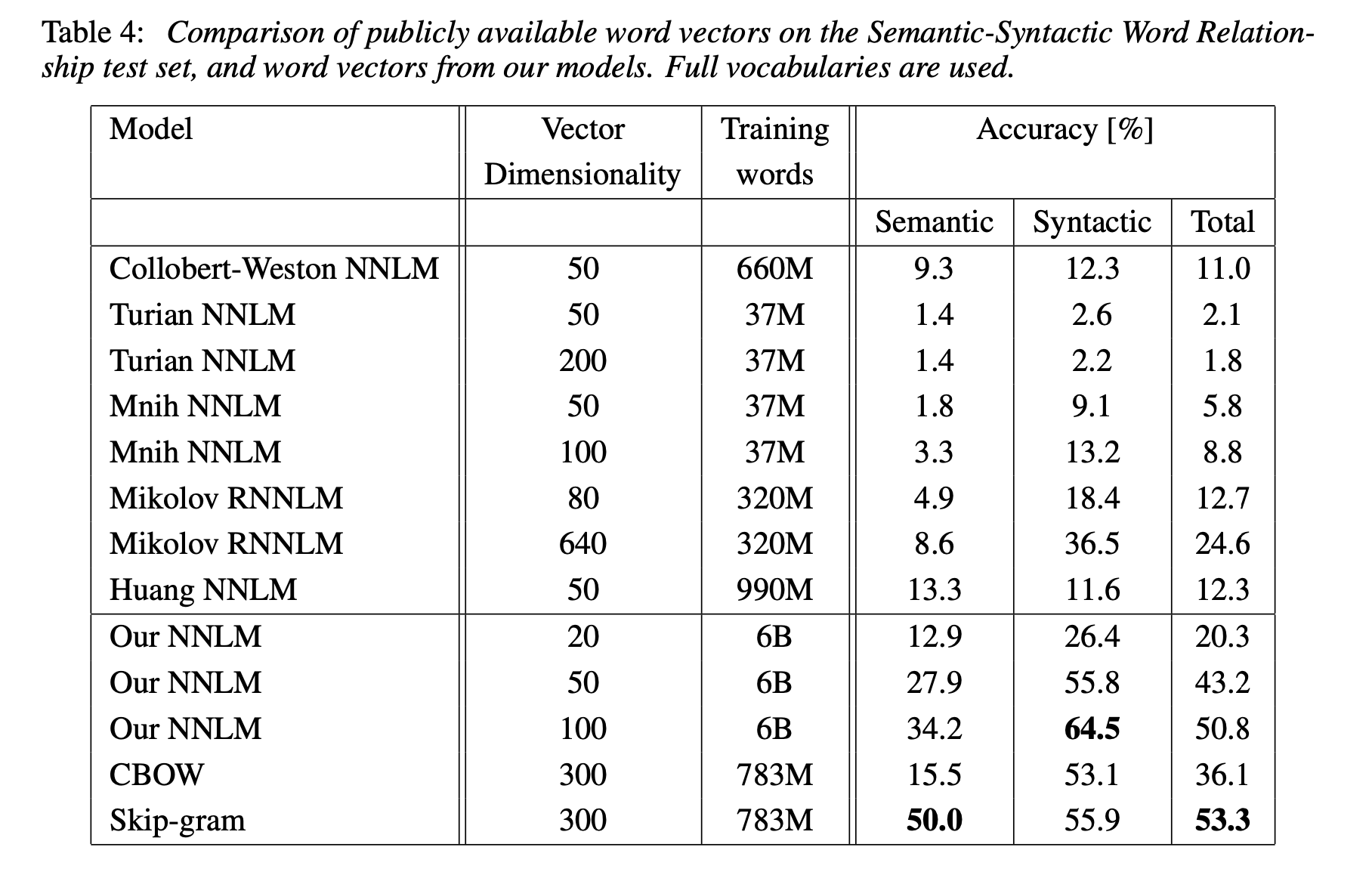
다른 여러 NNLM과 비교했을 때에도 CBOW와 skip-gram은 훨씬 더 좋은 성능을 보여준다.
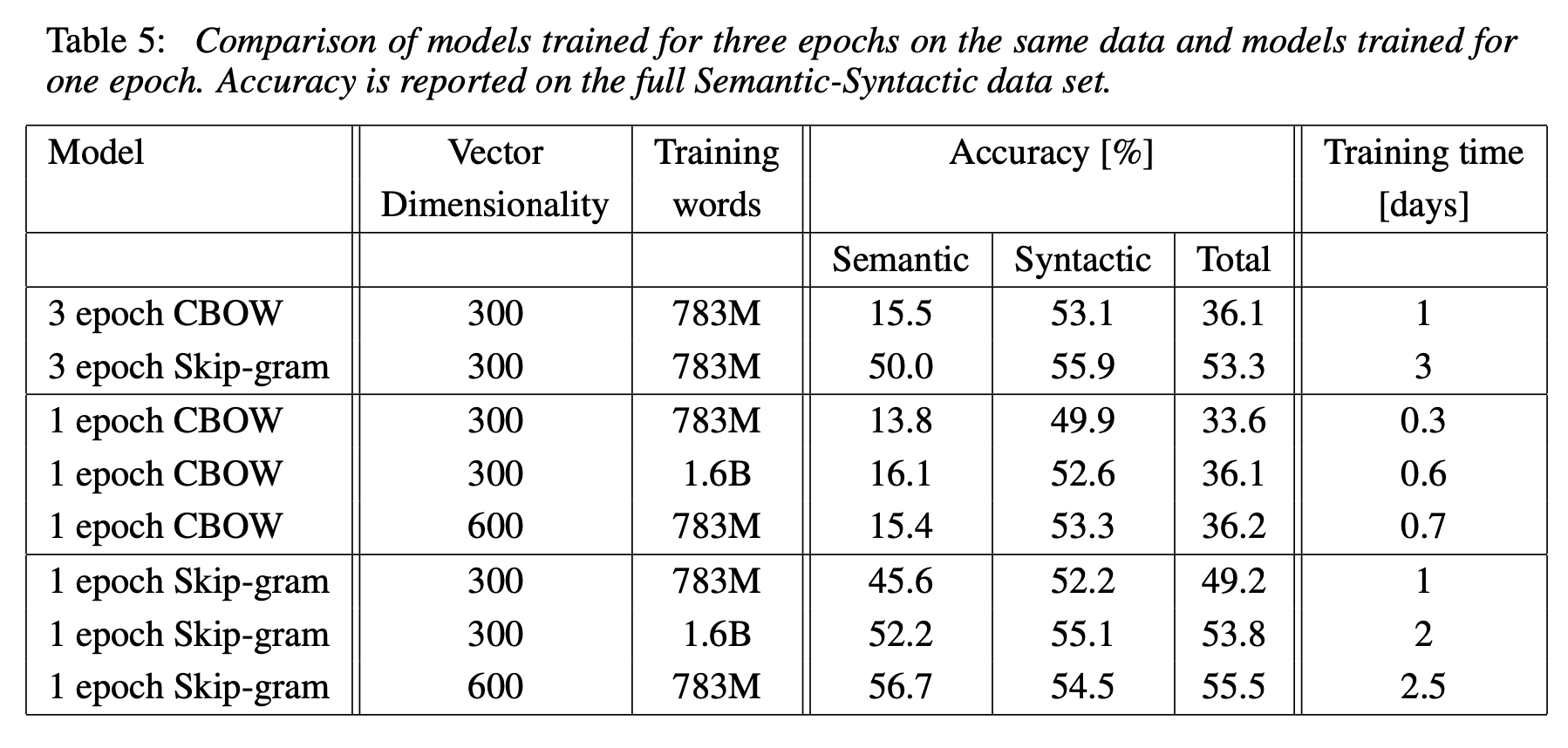
Microsoft Research Sentence Completion Challenge
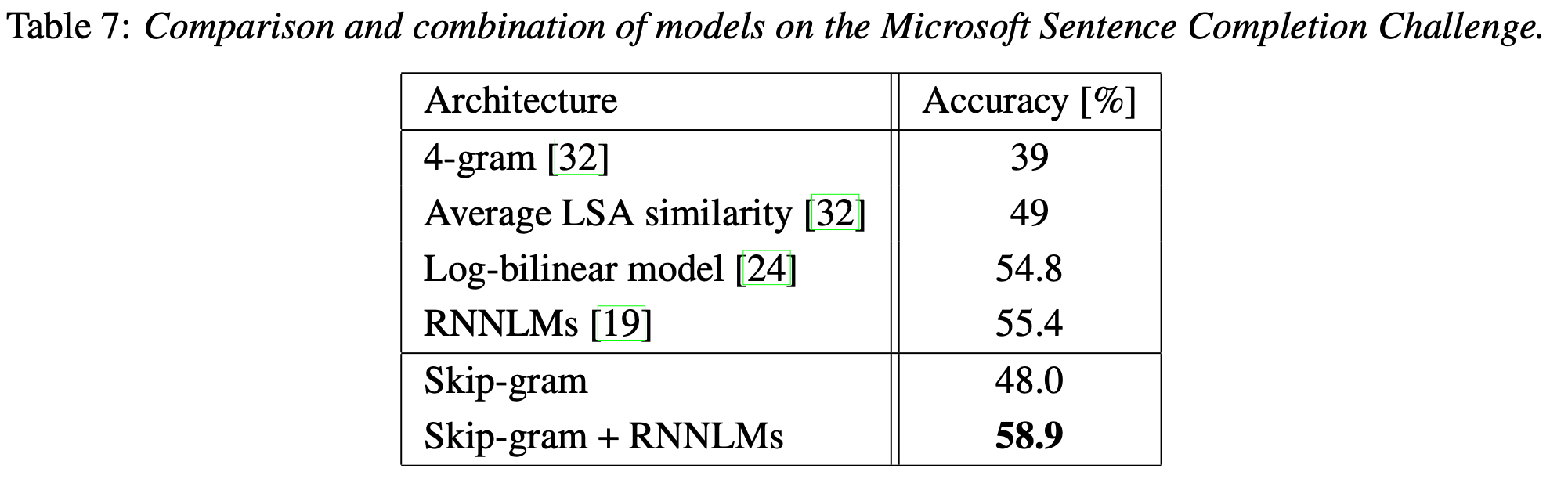
Microsoft Research Sentence Completion Challenge는 1040개의 sentence가 주어지는게, 각 sentence는 1개의 word가 빠져 있다. 각 sentence에서 빠진 word를 predict하는 task이다. 이 task에서 skip-gram 단독으로는 기존의 model들에 비해 다소 낮은 수치를 보였지만, RNNLM과 결합한 뒤에는 SOTA를 달성했다.
Examples of the Learned Relationships
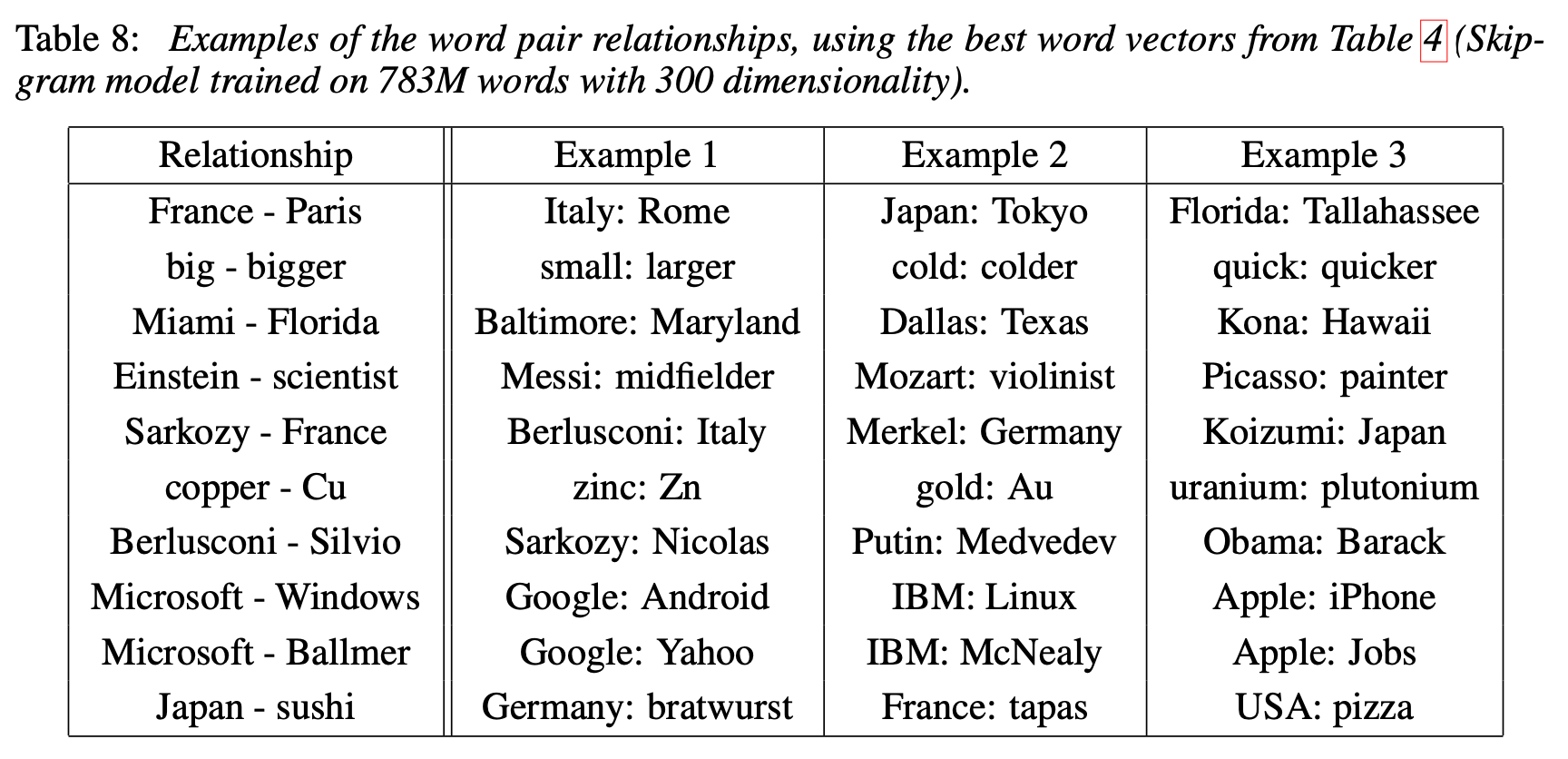
단어 사이의 상관관계를 분석해 다른 단어에 대해 유사한 관계를 갖는 단어를 예측하는 task에서 본 논문의 model은 60%의 정확도를 달성했다. 더 높은 정확도를 달성하기 위해서는 더 많은 dataset을 사용하고, 또 각 단어 사이의 상관관계 vector를 여러 단어쌍 사이의 subtract vector의 평균으로 만들어내면 될 것이다.
Conclusion
CBOW와 skip-gram이라는 새로운 word embedding 학습 방법을 제안했다. 기존의 여러 model들에 비해 연산량이 현저히 적고, 간단한 model임에도 매우 높은 성능을 보였다. 또한 word embedding vector의 syntax, semantic 성능을 측정할 수 있는 새로운 dataset을 제시했다.