Paper Info
Submit Date: Aug 10, 2020
Introduction
기존의 BERT model은 104개의 language의 Wikipedia dataset으로 학습된 model이다. 범용적으로 사용될 수 있다는 장점에도 불구하고, model의 크기가 과도하게 크다는 단점이 존재한다. 또한 non-English downstream task에서 좋은 성능을 보여주지 못하는 경우가 많다는 한계도 명확하다. 특히나 Korean과 같은 언어에서는 한계가 두드러진다.
Korean NLP task를 해결하기 위한 BERT model은 다음과 같은 이유들로 인해 많은 어려움이 있다.
- Korean이 교착어라는 특성으로 인해 과도하게 많은 형태소
- Hangul의 과도하게 많은 character (10,000개 이상)
본 논문에서는 위와 같은 Korean의 한계점에도 불구하고 Korean-specific한 BERT model을 고안해냈다. 우선 Multilingual BERT model에 비해 model의 size를 과감히 줄이고, sub-characters BPE를 사용했다. 또한 Bidirectional WordPiece Tokenizer를 사용해 Korean의 linguistic한 특성을 반영하고자 했다. KR-BERT model은 다른 Multilingual BERT Model의 성능을 모든 task에서 능가했고, 이에 더해 KorBERT나 KoBERT와 같은 기존의 Korean-specific model과도 동등하거나 더 좋은 성능을 보였다. 이는 KR-BERT의 작은 model 크기를 고려하면 매우 유의미한 결과이다.
Related Work
Models after BERT
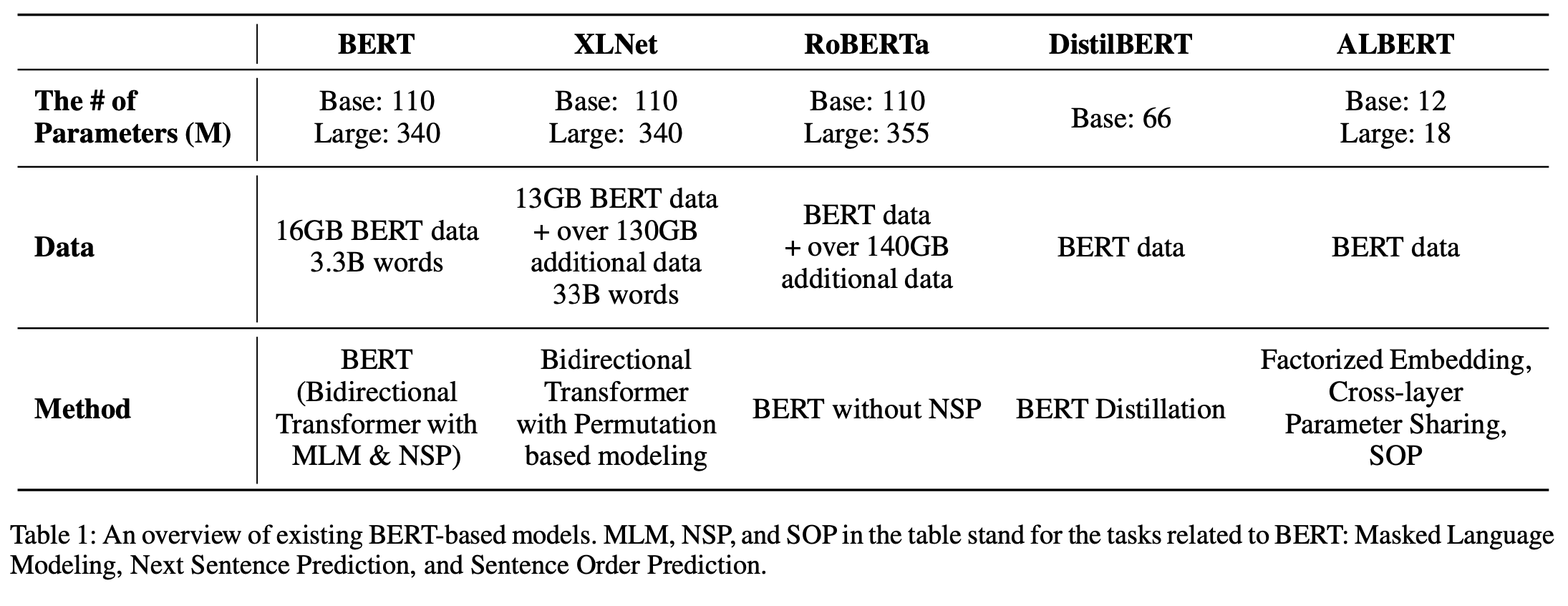
BERT 이후로 XLNet과 RoBERTa와 같은 대규모 dataset을 사용한 model들이 많이 등장했다. 그에 비해 DistilBERT나 ALBERT와 같이 #parameters를 줄이고, dataset도 늘리지 않은 small model들도 등장했다.
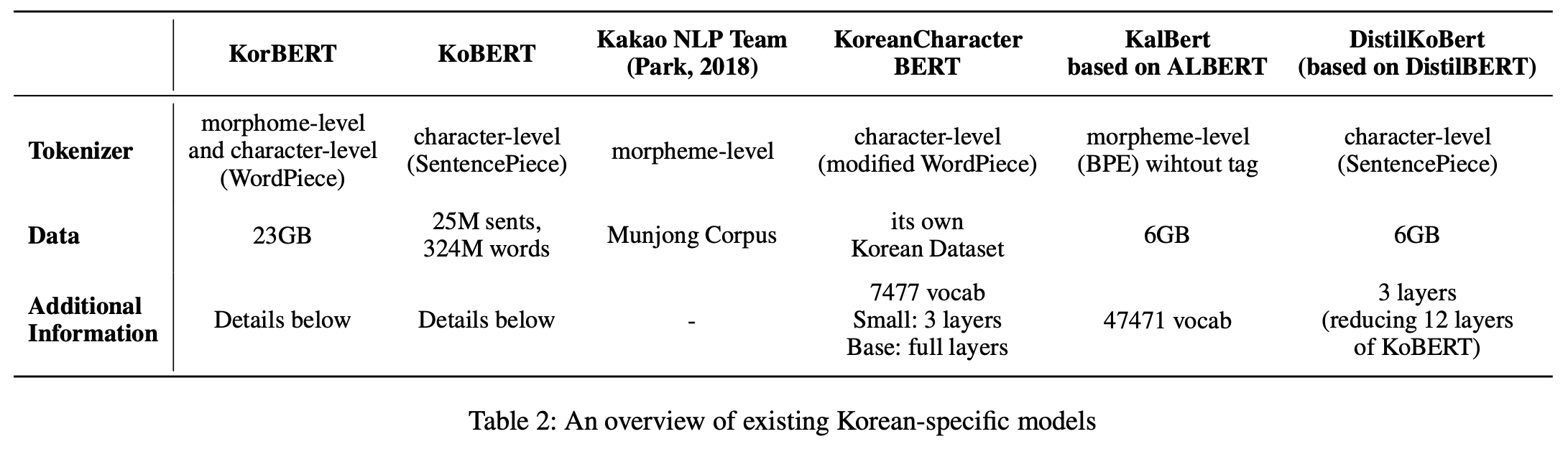
Recent Korean BERT models
The Need for a Small-scale Language-specific Model
Korean NLP task에서 multilingual BERT model은 아래와 같은 한계를 지닌다.
Limit of Corpus Domain
multilingual BERT는 104개의 language로 구성된 Wikipedia data로 pretrain된 model이다. German이나 French와 같은 data가 풍부한 language에 대해서는 Wikipedia에 더해 추가적인 dataset을 활용해 pretrain을 수행했다. 그러나 그 외 대부분의 language는 Wikipedia dataset만으로 pretrain되었다. Wikipedia dataset은 다양한 corpus를 포함하고 있지 않기에 제대로 된 학습을 기대하기 어렵다.
Considering Language-specific Properties
Rare “Character” Problem
English와 같은 Alphabet을 사용하는 language는 OOV가 적을 수 밖에 없다. 전체 character가 26개에 불과하기 때문이다. 반면 Korean은 syllable 기반이기 때문에 무려 11,172개의 character가 존재한다. 그러나 multilingual BERT에서는 이 중 오직 1,187개의 character만이 포함되었다. 나머지 character에 대해서는 제대로 학습이 되었다고 볼 수 없는 것이다.
Inadequacy for Morphologically Rich Languages
Korean은 교착어이다. 때문에 English와 같은 language보다 훨씬 많은 형태소를 가짐은 물론 French나 German과 같은 굴절어 보다도 더 많은 형태소를 갖는다. 대표적인 교착어인 Japanese나 Korean은 동사의 활용형만 하더라도 수많은 다른 형태를 갖는다.
Lack of Meaningful Tokens
character-level의 Korean은 음절 단위인데, 각 음절의 구분은 발음에서의 가치만 있을 뿐 의미론적으로 큰 가치가 없는 구분이다. 오히려 자음/모음 (문자소) 단위가 의미를 갖는 경우가 더 많다. multilingual BERT는 모든 language에 universal하게 적용되는 model을 위해 character-level로 설계가 되었기 때문에 Korean NLP task에 적합하지 않다.
Large Scale of the Model
XLNet이나 RoBERTa와 같은 대규모 model은 매우 많은 parameters와 큰 dataset, 큰 vocabulary를 사용했다. 그러나 이러한 대규모 model은 자원의 제약이 너무 많이 가해지기 때문에 작은 vocabulary, 적은 parameters, 적은 training dataset으로도 좋은 성능을 보이는 것을 목표로 했다.
Models
총 4가지 version의 KR-BERT에 대해 제시하고 비교한다. 우선 가장 작은 의미의 단위를 character-level(음절 단위)과 sub-character-level(자음/모음 단위)로 구분한다. 각각의 경우에 대해 BERT의 Original Tokenizer(WordPiece)를 사용한 것과 Bidirectional WordPiece Tokenizer를 사용한 것을 비교한다.
Subcharacter Text Representation

자음/모음 단위 구분을 통해 얻을 수 있는 이점은 동사나 형용사에 붙는 활용형을 정확하게 잡아낼 수 있다는 것이다. Table 3의 “갔”, “감”, “간”, “갈”은 모두 “가다”의 “가”에 여러 활용형이 붙은 경우이다. 하지만 이를 character-level로 분석하게 되면 모두 별개의 token이 된다. sub-character level로 분석을 함으로써 실제 “가다”의 의미를 파악해 낼 수 있는 것이다.
Subword Vocabulary
BPE의 성능은 vocabulary size에 따라 결정된다. 이는 heuristic하게 결정해야 하는데, 8000~20000 사이의 vocabulary size에 대해 test를 진행한 뒤 100,000 step에서의 Masked LM Accuracy를 비교한 결과 vocabulary size가 10,000일 때에 가장 성능이 좋다는 결론을 도출해냈다.
이후 Korean text에서 빈번하게 사용되는 외국어(Alphabet, 한자, 일본어 등)에 대해 heuristic하게 token을 추가했다.
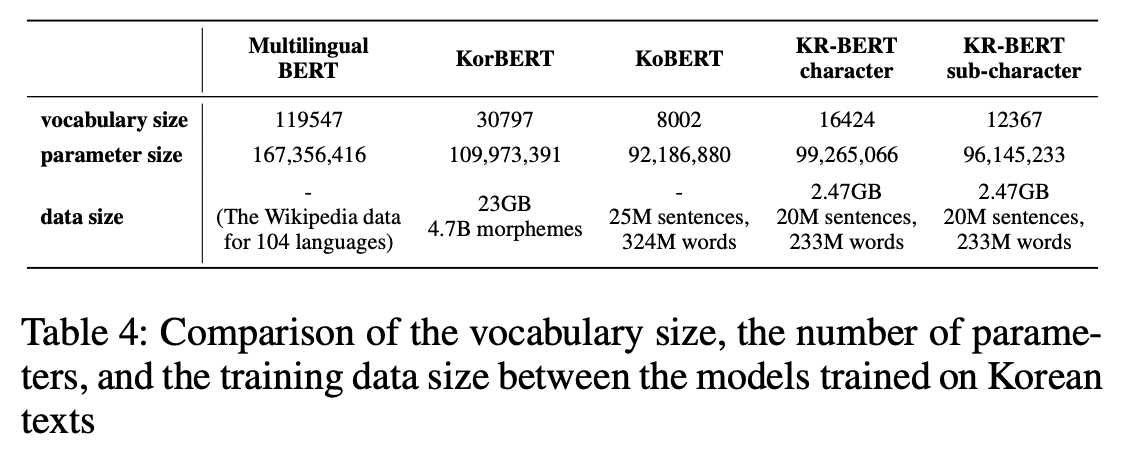
[Table 4]에서 볼 수 있듯이 KR-BERT는 character-level과 sub-character-level 모두에 있어서 Multilingual BERT나 KorBERT보다 훨씬 작은 크기의 vocabulary를 사용했다.
Subword Tokenization
기존의 WordPiece Tokenization과 본 논문에서 새로 제안한 Bidirectional WordPiece Tokenization을 모두 사용해 둘을 비교한다.
Baselines
Multilingual BERT나 KorBERT는 BPE를 사용한 WordPiece Tokenization를 채택했다. 반면 KoBERT는 Unigram LM을 사용한 SentencePiece Tokenization을 채택했다.
Bidirectional WordPiece Tokenizer
BPE를 forward로만 진행하지 않고, backward로도 동시에 진행하는 것이다. forward와 backward 각각의 pair를 생성한 뒤, 두 후보 중 더 등장 빈도가 높은 쪽을 선택하게 된다. 이는 한국어의 문법적 특성에 따라 고안된 방식이다. 한국어의 명사는 상대적으로 긴 어근을 갖고 주로 짧은 접두사들이 앞에 붙게 된다. 반면 동사의 경우에는 짧은 어근을 갖고 주로 짧은 접미사들이 뒤에 붙게 된다. Bidirectional BPE는 이러한 경우들에 대해 적절한 tokenizing을 수행할 수 있도록 돕는다.
Comparison with Other Korean Models
[Table 4]를 보면 KR-BERT는 Multilingual BERT, KorBERT에 비해 더 적은 vocabulary, 더 적은 parameter, 더 적은 data size를 갖는다는 것을 확인할 수 있다. 반면 KoBERT에 비해서는 더 많은 vocabulary, 더 많은 parameter를 갖지만 dataset은 더 적다.
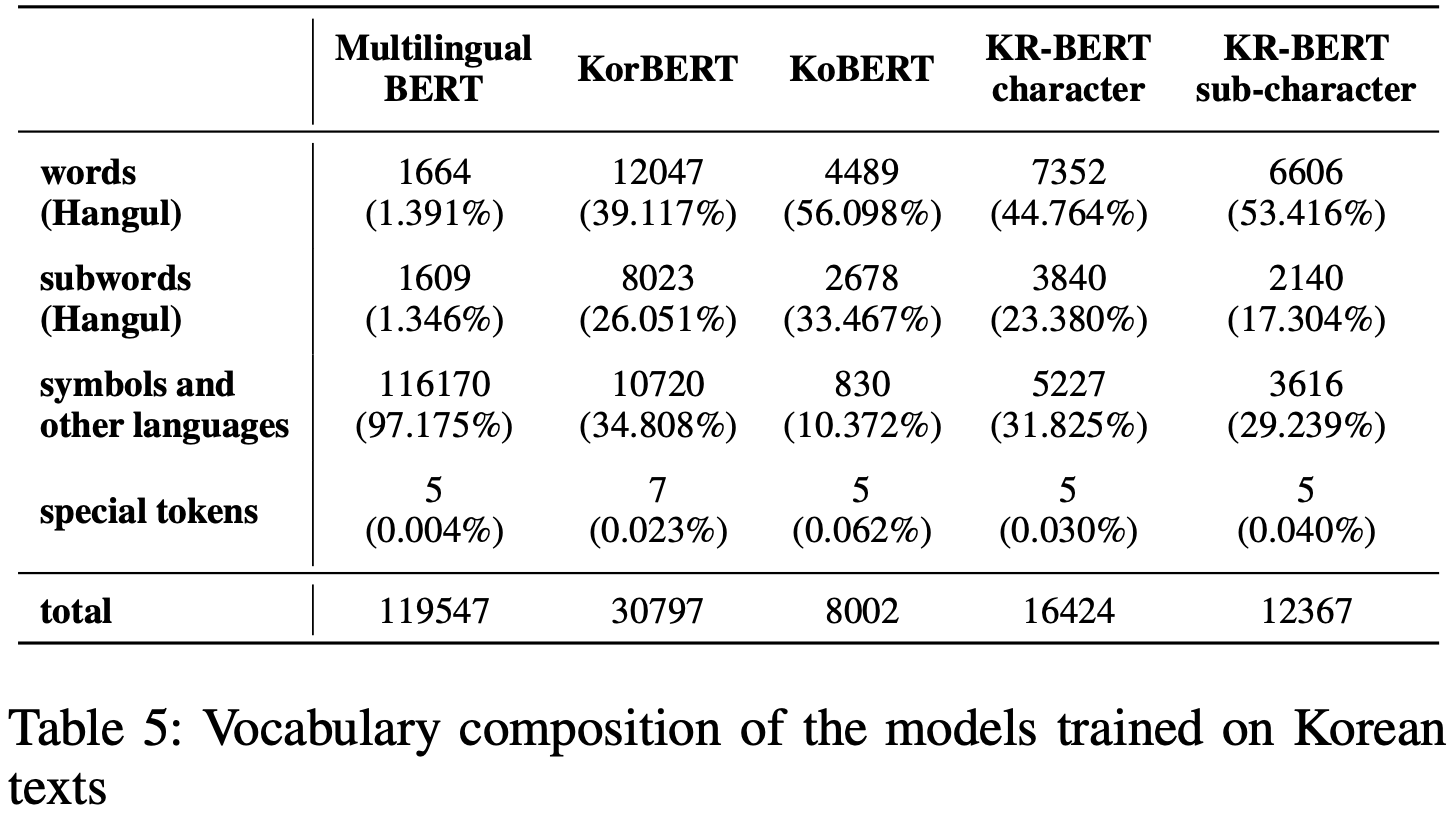
[Table 5]는 각 model들의 vocabulary이 어떤 비율로 구성되어 있는지를 보여준다. Korean Specific한 model들이 Multilingual BERT보다 Korean words와 Korean subwords의 비율이 압도적으로 높다는 것을 확인할 수 있다.
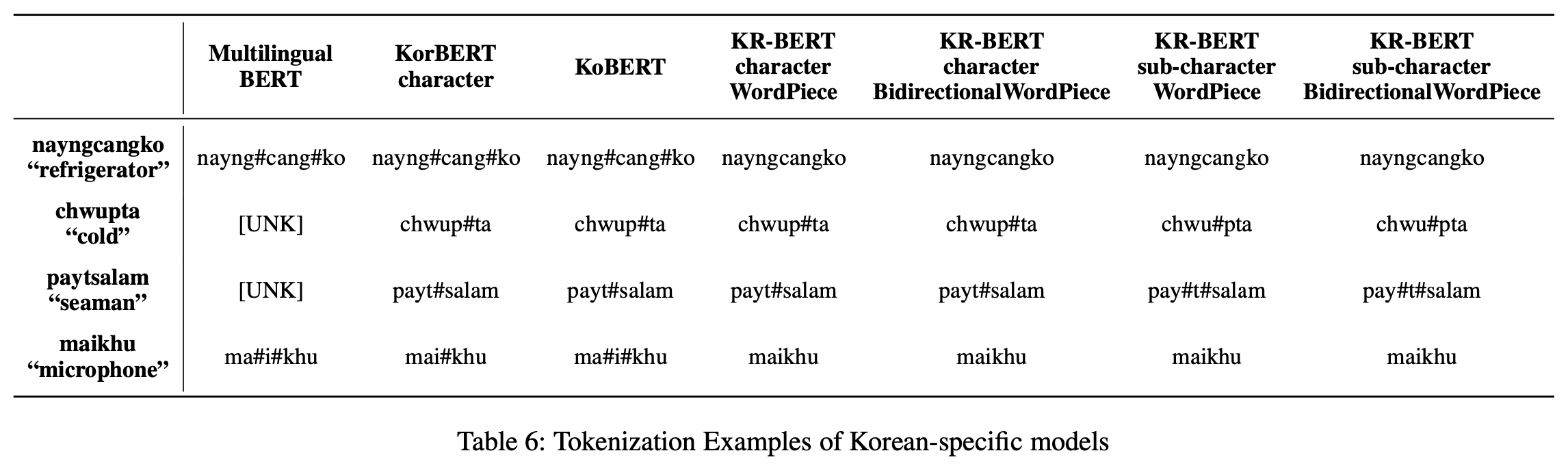
[Table 6]은 실제로 Tokenization이 어떻게 이루어지는지 구체적인 단어 예시를 통해 보여준다. “냉장고”는 Multilingual BERT와 KorBERT, KoBERT에서 모두 “냉”, “장”, “고”로 tokenizing된다. 반면 KR-BERT에서는 token level과 tokenizer에 관계없이 모든 model에 있어서 “냉장고”라는 하나의 token으로 분류한다. “냉장고”를 각 character 별로 단순하게 tokenizing한 것에 비해 의미론적으로 더 알맞게 tokenization이 된 것이다.
“춥다”는 Multilingual BERT에서는 아예 OOV로 판별이 된다. KorBERT와 KoBERT에서는 모두 “춥”, “다”로 tokenizing하게 된다. 그러나 KR-BERT에서는 character level은 “춥”, “다”로 다른 Korean Specific Model과 동일하게 tokenizing을 하지만, sub-character level에서는 “추”, “ㅂ다”로 tokenizing을 한다. sub-character level의 tokenizing이 더 적절한 결과를 도출해낸다는 것을 확인할 수 있다.
“뱃사람”은 Multilingual BERT에서는 OOV이고, KorBERT와 KoBERT에서는 “뱃”, “사람”으로 tokenizing된다. character level의 KR-BERT에서도 마찬가지의 결과를 보여준다. 반면 sub-character level KR-BERT는 “배”, “ㅅ”, “사람”으로 tokenizing을 한다. Korean의 문법적 특성인 ‘사이시옷’까지 잡아낸 것이다.
“마이크”는 Multilingual BERT와 KoBERT에서는 “마”, “이”, “크”로, KorBERT에서는 “마이”, “크”로 tokenizing된다. 반면 KR-BERT에서는 모든 model에서 동일하게 “마이크”로 tokenizing한다. 외래어 표기에 있어서 기존 model에 비해 더 강력한 성능을 보여주는 것이다.
Experiments and Results
여러 Korean NLP downstream task에 대해서 Multilingual BERT와 기존의 Korean Specific Model, KR-BERT를 비교한다. sentiment classification, question answering, named entity recognition, paraphrase detection에 대해서 실험을 진행했다.
Results
Masked LM Accuracy

KR-BERT의 모든 model이 KoBERT보다 더 좋은 MLM Accuracy를 보여준다. 또한 KR-BERT 내에서 Bidirectional WordPiece를 사용한 model이 조금 더 나은 결과를 보여준다.
Downstream tasks
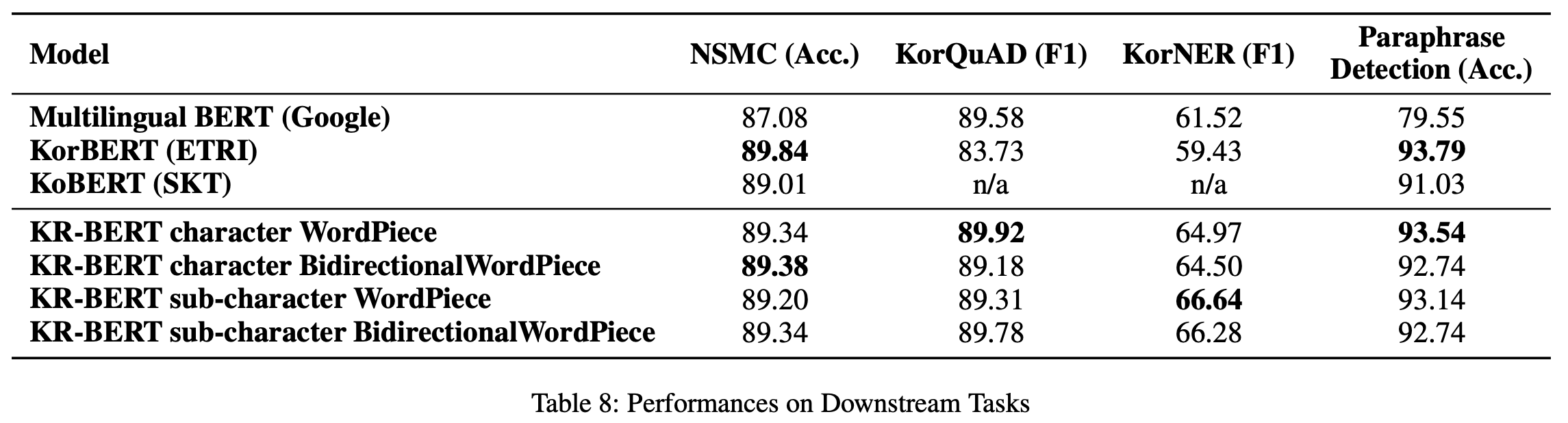
sentiment classification은 Naver Sentiment Movie Corpus Dataset을, question answering은 KorQuAd Dataset을, named entity recognition는 KorNER Dataset을, paraphrase detection은 Korean Paired Question Dataset을 사용했다.
모든 경우에 있어서 Multilingual BERT는 Korean Specific Model의 최고 성능을 능가하지 못했다. KR-BERT는 KorQuAD와 KorNER에서 가장 좋은 성능을 보여준다. 반면 NSMC와 Paraphrase Detection에 있어서는 KorBERT가 근소하게 더 높은 수치를 보여준다. 하지만 그럼에도 불구하고 KorQuAD와 KorNER에서의 KorBERT와 KR-BERT의 차이는 7%로 매우 높다는 점, KorBERT의 model size와 풍부한 dataset을 고려한다면 매우 유의미한 결과이다.
Analysis of Downstream Tasks

사실 KR-BERT model 중에서 sub-character Bidirectional WordPiece model이 일관되게 최고의 성능을 보여주지는 못한다. 하지만 그럼에도 다른 model들에 비해 일관되게 좋은 성능을 유지한다는 점에서 긍정적이다.
NSMC의 경우에는 웹사이트 사용자들의 data라는 점에서 noise나 문법적 오류가 상대적으로 많고, unformal한 data이다. NER은 task의 특성 상 당연하게도 고유 명사가 많으므로 OOV의 비율이 높을 것이다. 또한 KorQuAD와 Paraphrase Detection은 상대적으로 formal한 data일 것이다.
[Table 9]를 보면 bidirectional 방식과 sub-character level이 문법적 오류를 더 정확하게 잡아낸다는 점을 확인할 수 있다. “이영화”는 사실 “이”, “영화”의 두 단어로 구분되어야 하지만 중간의 공백이 삽입되지 않은 경우이다. 이에 대해 Bidirectional WordPiece KR-BERT만이 “이”, “영화”로 정확하게 tokenizing을 수행한다. Bidirectional이 아닌 KR-BERT는 “이영”, “화”로 잘못된 tokenizing을 수행했다.
“재밌는뎅”의 경우에는 “재밌는데”에 “ㅇ”라는 nosie가 추가된 경우이다. 이는 sub-character level KR-BERT가 정확하게 잡아내는데, “재미”, “ㅆ”, “는데”, “ㅇ”로 tokenizing을 수행한다. 반면 character-level KR-BERT는 “재”, “밌”, “는”, “뎅”으로 잘못된 tokenizing을 수행한다.
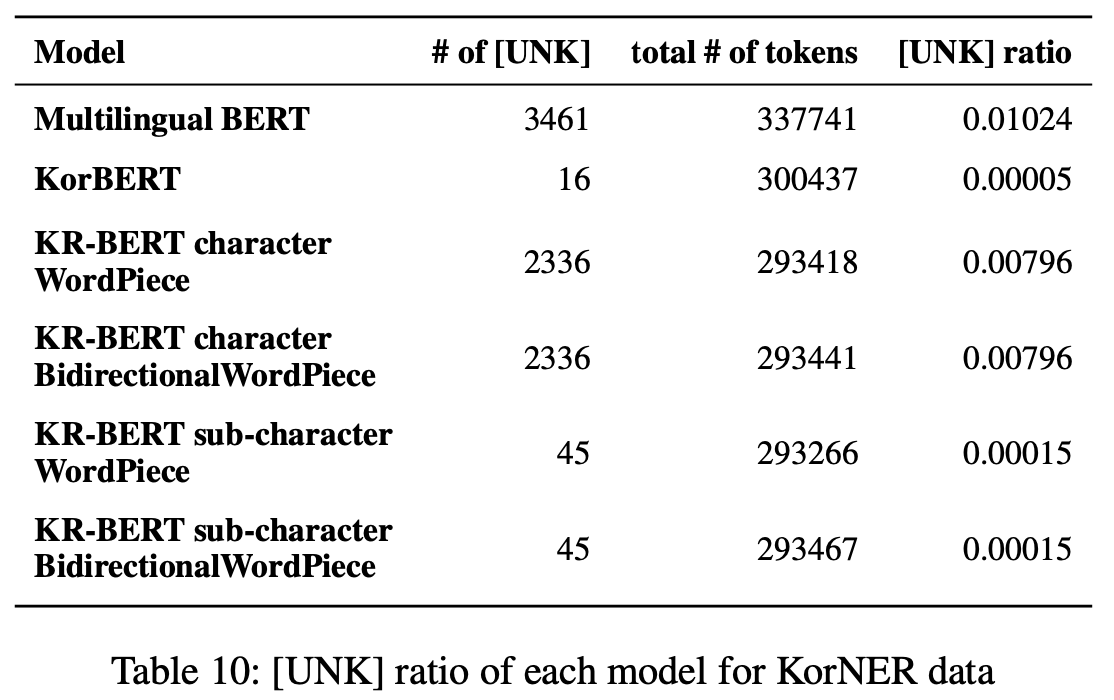
NER과 같은 OOV 비율이 높은 task에 대해서는 sub-character level이 더 좋은 성능을 보여준다. 이는 [Table 10]에서 OOV rate를 확인했을 때 sub-character level이 character level 대비 OOV가 훨씬 낮다는 점을 보면 당연한 결과이다.
KorQuAD나 Paraphrase Detection과 같은 formal data의 경우에는 WordPiece가 Bidirectional WordPiece보다 더 좋은 성능을 보여준다.
Conclusion
Korean-specific BERT model인 KR-BERT model을 제안했다. 기존의 Korean-specific model에 비해 더 작은 규모에서 더 적은 dataset으로 동등하거나 더 좋은 성능을 보여줬다. 이 과정에서 sub-character level tokenizing, Bidirectional BPE를 사용해 Korean의 문법적 특성을 잡아냈다.