Paper Info
Submit Date: Jun 21, 2019
Abstract
BERT에서 영감을 받아 Pre-training / fine-tuning, encoder/decoder를 채택한 MAsked Sequence to Sequence (MASS) model을 만들어냈다. random하게 input sentence에 연속적인 mask를 부여한 뒤 decoder가 predict하는 방식으로 encoder와 decoder를 Pre-training시켜 Language Generation Task에 적합한 Model을 개발했다. 특히 dataset이 적은 Language Generation task에서 비약적인 성능 향상이 있었다.
Introduction
Pre-training은 target task에 대한 labeled data(pair data)가 적으면서 해당 language에 대한 data(unpaired data)는 많을 때에 가장 적합하다고 할 수 있다. BERT는 language understanding을 목표로 하는 방식이기에 language generation task에는 적합하지 않다. MASS의 BERT와 Masking rule에서 다음과 같은 차이점을 둔다. 첫번째로, MASK token이 연속적으로 배치되고, 해당 MASK Token을 예측하면서 encoder는 unmasked token들의 context를 학습할 수 있도록 한다. 두번째로 decoder의 target token에도 MASK를 부여함으로써 predict 시에 encoder를 더 많이 활용할 수 있도록 한다.
MASS
Sequence to Sequence Learning
source sentence를 \(x\), target sentence를 \(y\)라고 한다. 각각 domain \(X\)와 \(Y\)에 속한다. sentence pair를 다음과 같이 정의할 수 있다.
\[\left(x,y\right) \in \left(X,Y\right), \\x= \left(x_1,x_2, ..., x_m\right)\\y = \left(y_1,y_2, ..., y_n\right)\]Objective Function은 다음과 같다. domain \(X\)와 \(Y\)에 대한 모든 sentence pair들에 대해 \(x\)가 주어졌을 때 \(y\)를 구하는 조건부 확률의 log liklihood를 더한 것이다.
\[L(\theta;(X,Y)) = \sum_{\left(x,y\right)\in\left(X,Y\right)} {log P\left(y|x;\theta\right)}\]조건부 확률을 구하는 수식은 다음과 같다. source sentence 전체와 target sentence에서 현재 token 이전의 모든 token들이 주어졌을 때 현재 token에 대한 조건부 확률이다.
\[P\left(y|x;\theta\right)=\prod_{t=1}^n{P\left(y_t|y_{<t},x;\theta\right)}\]\(y_{<t}\)는 \(y_1\sim y_{t-1}\)의 token들이다.
Masked Sequence to Sequence Pre-training
MASS는 BERT와 달리 MASK token이 discrete하게 분포되어 있지 않고 연속적으로 뭉쳐져 있다. 이에 따라 새로운 parameter \(k\)가 등장한다. \(k\)는 MASK token의 개수인데, \(k\)개의 MASK token은 연속되어 있다. MASK token이 \(u\)부터 \(v\)까지 분포되어 있다면 \(0<u<v<m\) (\(m\)은 전체 sentence 길이)이고, \(k = v - u + 1\)이다. Pre-training에서 사용하는 Objective Function은 다음과 같다. 조건부 확률의 조건으로 다음의 2가지 값이 주어지게 된다.
- MASK가 씌워진 input sentence 전체
- input sentence에서 MASK가 씌워진 token들 중 현재 token \(x_t\) 이전의 token들의 MASK 씌워지기 이전 원본 token
\(x^{u:v}\)는 sentence \(x\)에서 \(u\)부터 \(v\)까지의 tokens를 뜻하고, \(x^{\backslash u:v}\)는 \(u\)부터 \(v\)까지 MASK된 sentence \(x\) 전체를 뜻한다.
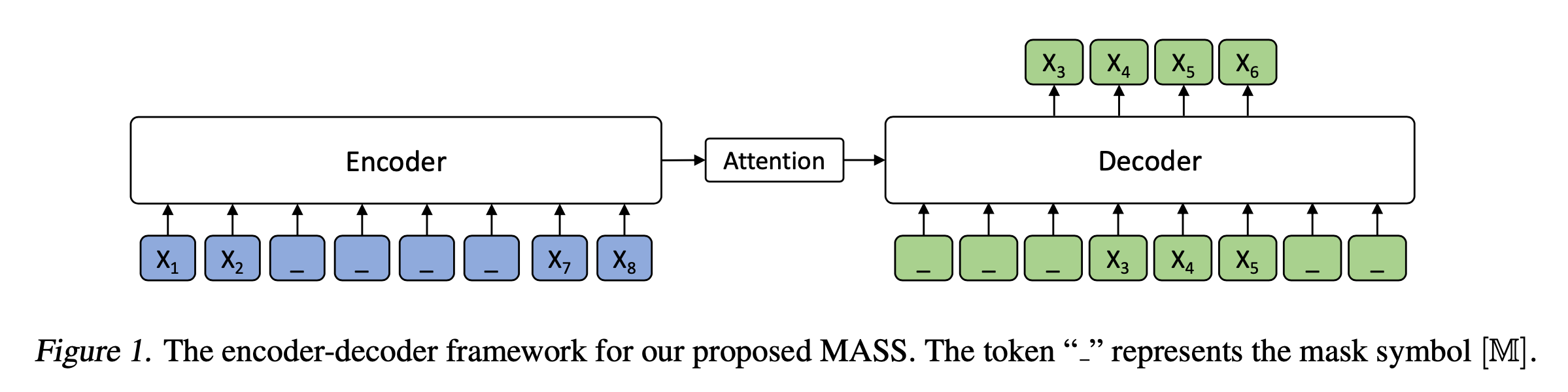
구체적인 예시를 살펴보자. 위의 figure는 \(x_3, x_4, x_5, x_6\)이 masking된 상황이다. \(k=4\)이고, \(u=3, v=6\)이다. Encoder의 input 으로는 masking된 input sentence \(x^{\backslash u:v}\)가 들어오게 되는데, 이 경우에는 \(x^{\backslash 3:6}\)이다. Attention 기법을 적용해 Decoder로 값이 넘어오고, Decoder에서는 새로운 input으로 \(x^{u:v}\), 이 경우에는 \(x^{3:6}\)을 입력으로 받는다. 이 때 input sentence에서 masking이 되지 않은 token들 (\(x_1, x_2, x_7,x_8)\)의 경우에는 Decoder에 input으로 들어오지 않는다. Decoder의 input으로 들어온 token들 \(x_3, x_4, x_5, x_6\) 중 실제로는 \(x^{u:v}_{<t}\)로 사용되기 때문에 마지막 token \(x_6\)은 사용되지 않는다.
Discussions
Special Case ( k=1, k=m)
MASS에서 hyperparameter \(k\)는 매우 중요한 parameter이다. \(k\)가 특수한 값일 때에 대해서 살펴보자.
\(k=1\)인 경우는 사실 BERT에서의 MLM(Masked Langage Model)이다. BERT의 MLM에 대한 자세한 설명은 아래를 참조하자.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
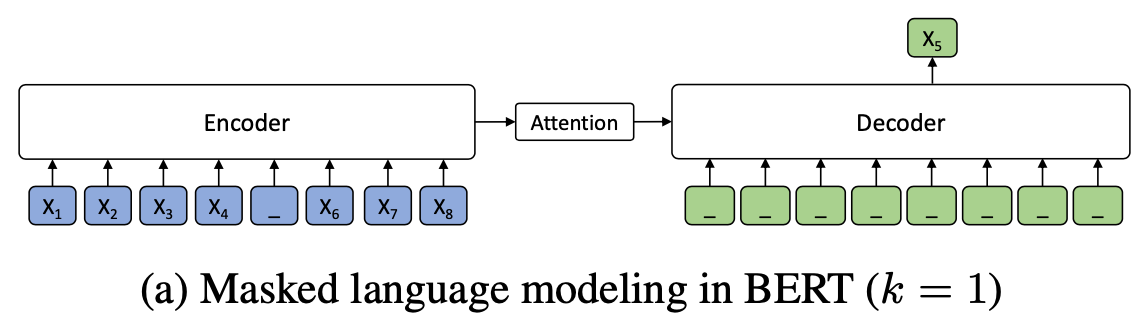
BERT의 MLM은 MASK token에 대해서 predict만 하는 방식으로 Pre-training을 수행했다. 즉 Decoder에 어떠한 input도 추가적으로 주어지지 않고, Encoder에서 넘어온 Context Vector만을 사용해 MASK token을 predict하는 training이다. 이는 MASS에서 \(k=1\)일 때의 경우이다.
한편, \(k=m\) (\(m\)은 sentence의 token 개수)인 경우는 일반적인 Language Generation Model이다.
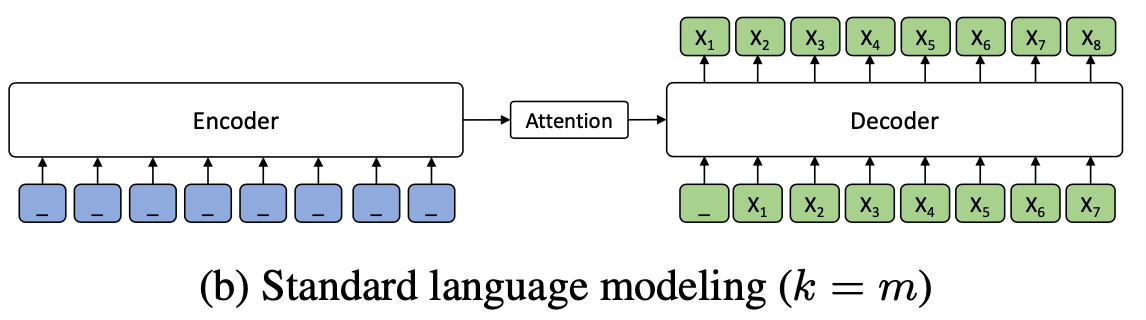
\(k=m\)인 경우는 사실 일반적인 Language Model의 경우이다. \(k=m\)라는 것은 다시 말해 input sentence의 모든 token이 masking되었다는 의미이고, 이는 Encoder의 input으로 아무 값도 들어오지 않는 경우와 같다. 한편 Decoder의 입장에서는 input으로 original sentence의 masked token들이 들어오게 되는데, original sentence는 모두 masking되었으므로 모든 token이 Decoder로 들어오는 경우이다. 이는 결국 Encoder가 없이 Decoder만 작동하는 상황이라고 볼 수 있다. 일반적인 GPT model와 같다.
위의 두 가지 special case와 일반적인 case를 Table로 정리하면 아래와 같다.

Comparison with existing model
- MASK token만 predict하게 함으로써 Encoder는 unmasked token들에 대한 context를 학습하게 되고, decoder가 encoder로부터 더 좋은 정보를 가져갈 수 있도록 한다. (encoder가 context vector를 제대로 생성해내도록 한다.)
- MASK token을 연속적으로 배치함으로써 Decoder가 단순 word들이 아닌 subsentence를 만들어낼 수 있도록 한다. (better language modeling capability)
- Decoder의 input으로 source sentence의 unmasked token들이 들어오지 못하게 함으로써 Decoder의 input token들에서 정보를 활용하기보다 Encoder에서 넘어온 Context Vector의 정보를 활용할 수 있도록 했다.
Experiments and Results
MASS Pre-training
Model Configuration
6개의 encoder, decoder layer를 가진 Transformer를 Base Model로 선택했다. NMT를 위해 source language와 target language에 대해 각각 monolingual data로 pre-train을 진행했다. English-French, English-German, English-Romanian의 3가지 pair를 사용했다. 각 pair에 대해서 별개로 학습을 진행했으며, 이 때 source language와 target language를 구분하기 위해 새로운 language embedding을 encoder input과 decoder input에 추가했다. Text Summarization과 Conversational Response Generation task에 대해서는 모두 English에 대해서만 pre-train을 진행했다.
Datasets
WMT News Crawl Dataset을 사용했다. English, French, German, Romanian에 대해서 Pre-train을 진행했다. 이 중 Romanian의 경우에는 data가 적은 language이다. low-resource language에 대한 MASS의 pre-training 성능을 측정하기 위해 채택했다. 모든 language에 대해 BPE를 적용했다.
Pre-Training Details
BERT와 동일한 masking rule을 채택했다.MASK token으로 변경되는 token 중 실제로 변경되는 token은 80%이고, 다른 random한 token으로 변경되는 것이 10%, 변경되지 않는 것이 10%이다. hyperparameter \(k\)는 전체 sentence 길이 \(m\)의 50%와 비슷한 수치가 되도록 설정했다. decoder의 input으로 들어오는 sentence에 대해서는 기존의 original sentence에서의 positional encoding은 수정되지 않는다. Adam Optimizer를 사용했고, lr은 0.0001이며, batch_size는 3000이다.
fine-tuning을 수행할 dataset이 적은 경우(paired sentence가 적은 경우)에 대해서도 성능을 측정한다. 특히 아예 fine-tuning data가 없는 상태에서도 NMT를 잘 수행할 수 있는지에 대해서 살펴본다.
Fine-Tuning on NMT
Experimental Setting
Unsupervised NMT를 수행하기 위해서 back-translation을 사용한다. bilingual data가 없기 때문에 soruce language data로 가상의 bilingual data를 생성해내는 것이다. Pre-Training과 동일하게 Adam Optimizer, lr=0.0001을 채택했으며, batck_size는 2000이다. evaluation을 위해 BLEU Score를 사용했다.
Results on Unsupervised NMT
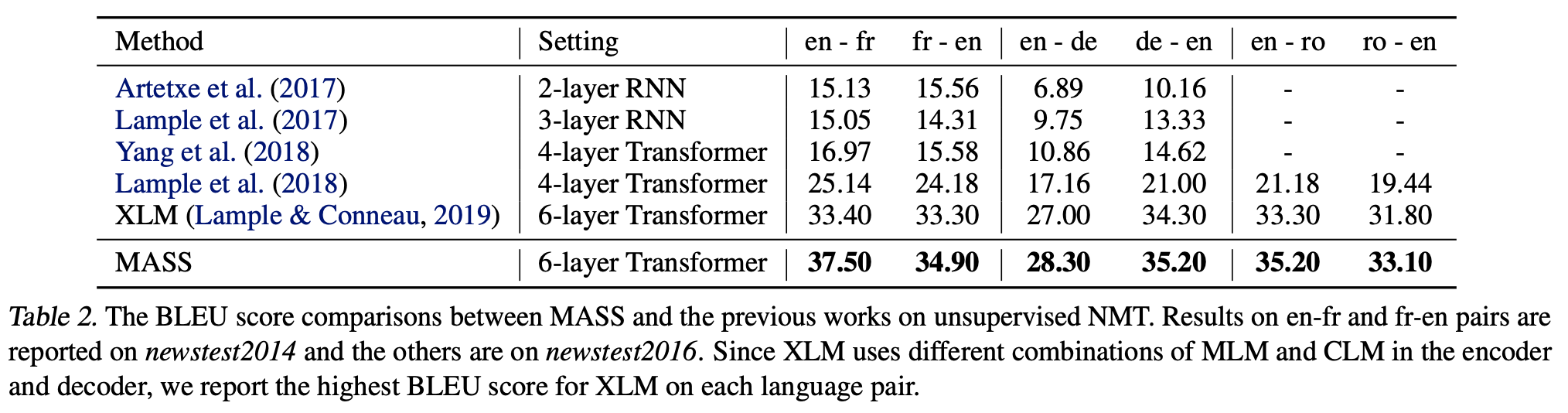
RNN 계열의 Model들(1,2행)과 Pre-train 방식이 아닌 Transformer Model(3,4행), Pre-train Transfor Model(5행)들을 모두 능가했다. Unsupervised NMT는 난제이기에 절대적인 Score는 낮지만, 기존의 SOTA Model인 XLM을 능가했다는 점에서 의미가 있다.
Compared with Other Pre-training Methods
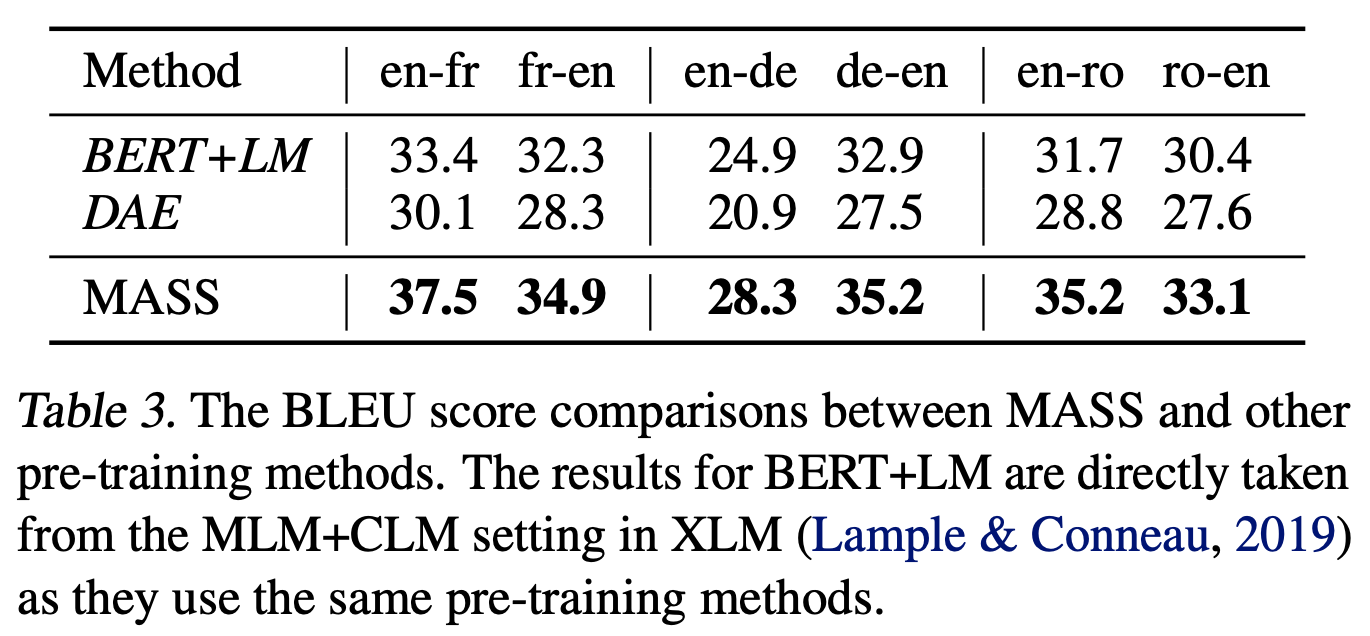
다양한 Pre-train Methods를 적용한 Model들과 Unsupervised NMT에서의 BLEU Score를 비교해본다. BERT와 동일한 방식으로 Pre-train을 진행한 BERT+LM Model, denoising auto-encoder Pre-train 방식을 적용한 DAE를 모두 능가했다.
Experiments on Low-Resource NMT
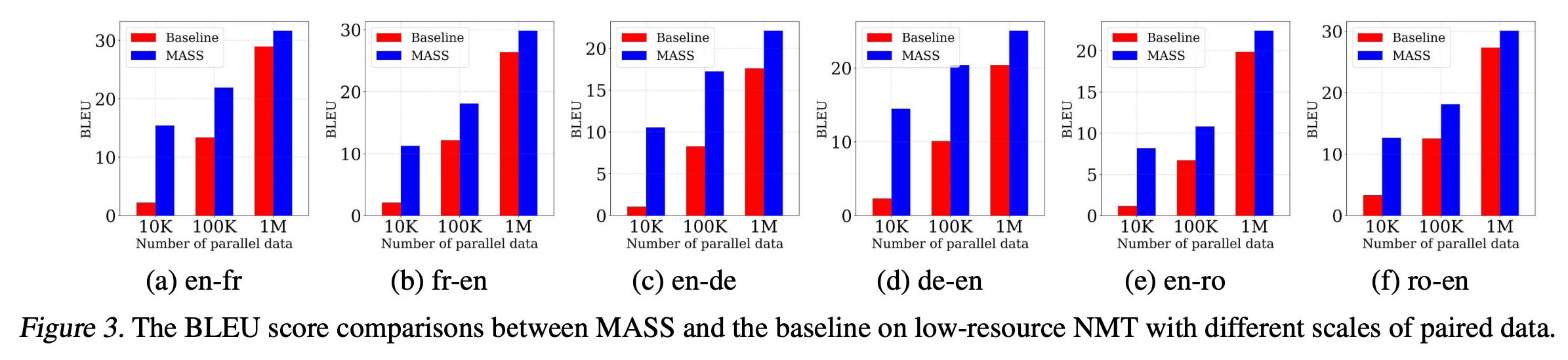
Pre-train은 20000 step 진행했으며, bilingual dataset의 sample 크기가 10K, 100K, 1M인 경우에 대해서 각각의 언어에 대해 별개로 성능을 측정했다. baseline model은 pre-train 과정이 없는 model이다. 모든 경우에 있어서 MASS가 baseline model을 압도했으며, 특히나 Sample의 크기가 작을 수록(fine-tuning을 적게 수행할수록) 성능의 차이가 컸다.
Fine-Tuning on Text Summarization
Experiment Setting
Gigaword corpus를 fine-tuning data로 사용했다. sample size가 10K, 100K, 1M, 3.8M인 경우에 대해서 별개로 성능을 측정했으며, encoder의 input은 article로, decoder의 output은 title로 설정했다.성능 측정은 ROUGE-1, ROUGE-2, ROUGE-L에 대한 F1 score로 측정했다. beam size=5인 beam search를 사용했다.
Results
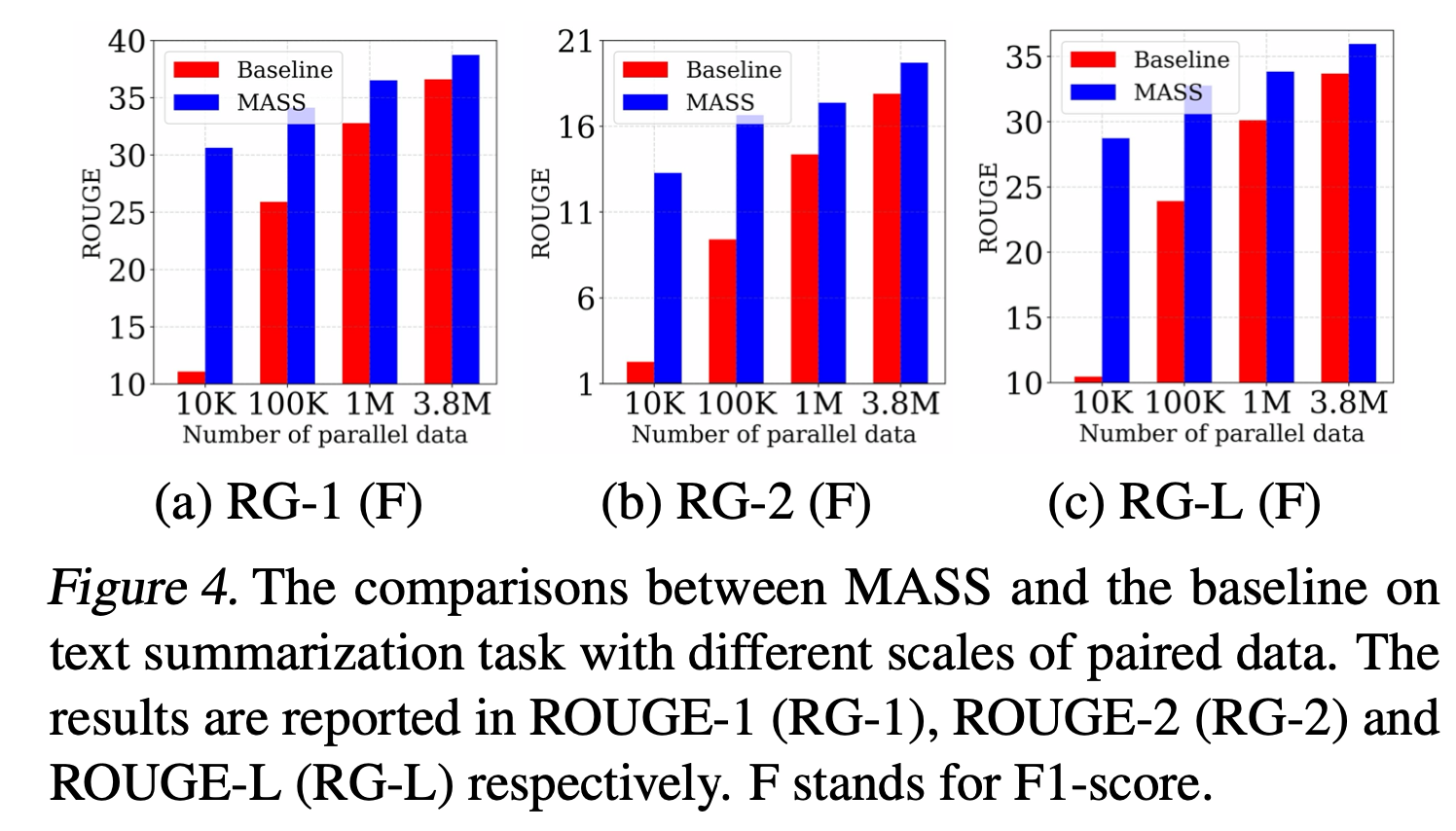
pre-training을 수행하지 않은 basemodel과 비교를 수행했으며, dataset이 적은 경우에 대해서 압도적인 성능 격차를 보였다는 것을 확인할 수 있다.
Compared with Other Pre-Training Methods
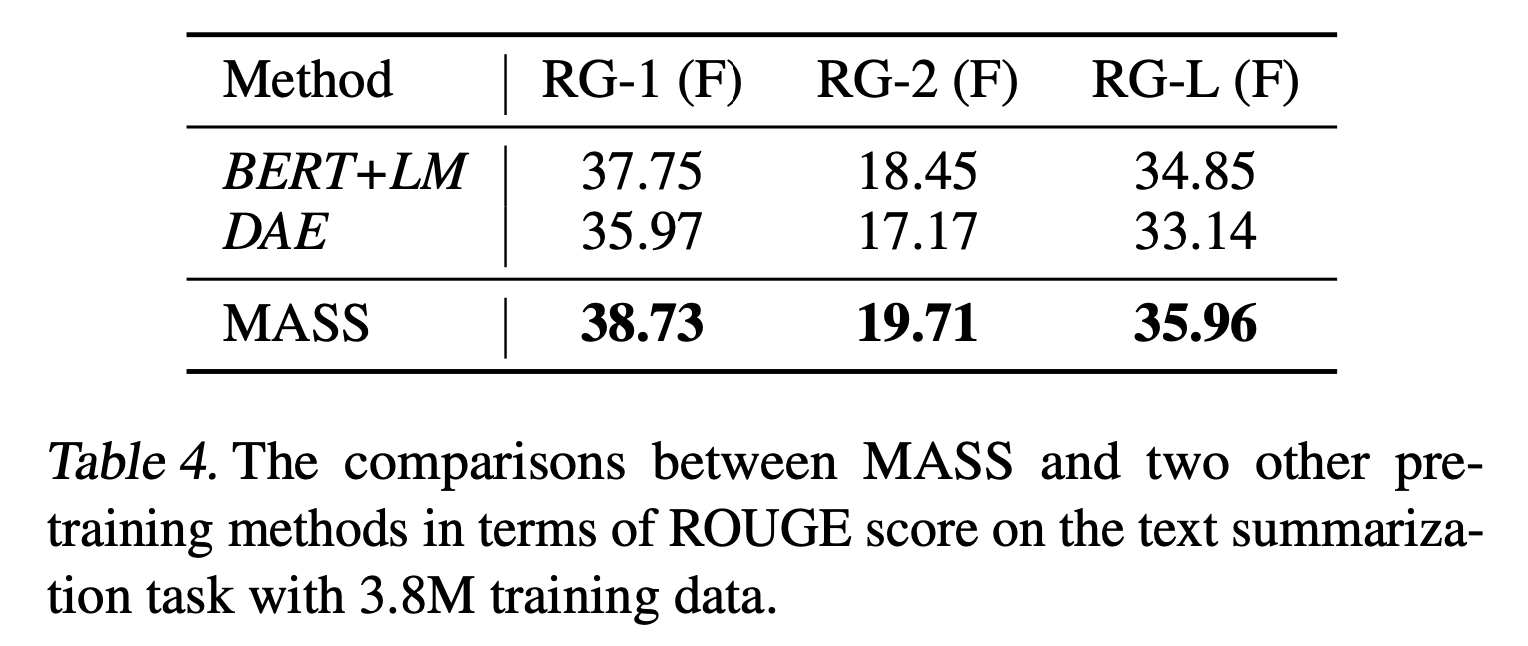
다른 Pre-training model에 대해서도 더 좋은 성능을 보였다.
FIne-Tuning on Conversational Response Generation
Experimental Setting
Cornell movie dialog corpus를 Dataset으로 사용했다. 총 140K의 pair 중에서 10K는 validation set, 20K는 test set, 나머지는 모두 training set으로 사용했다. Perplexity(PPL)을 성능 측정 단위로 사용했다.
Results
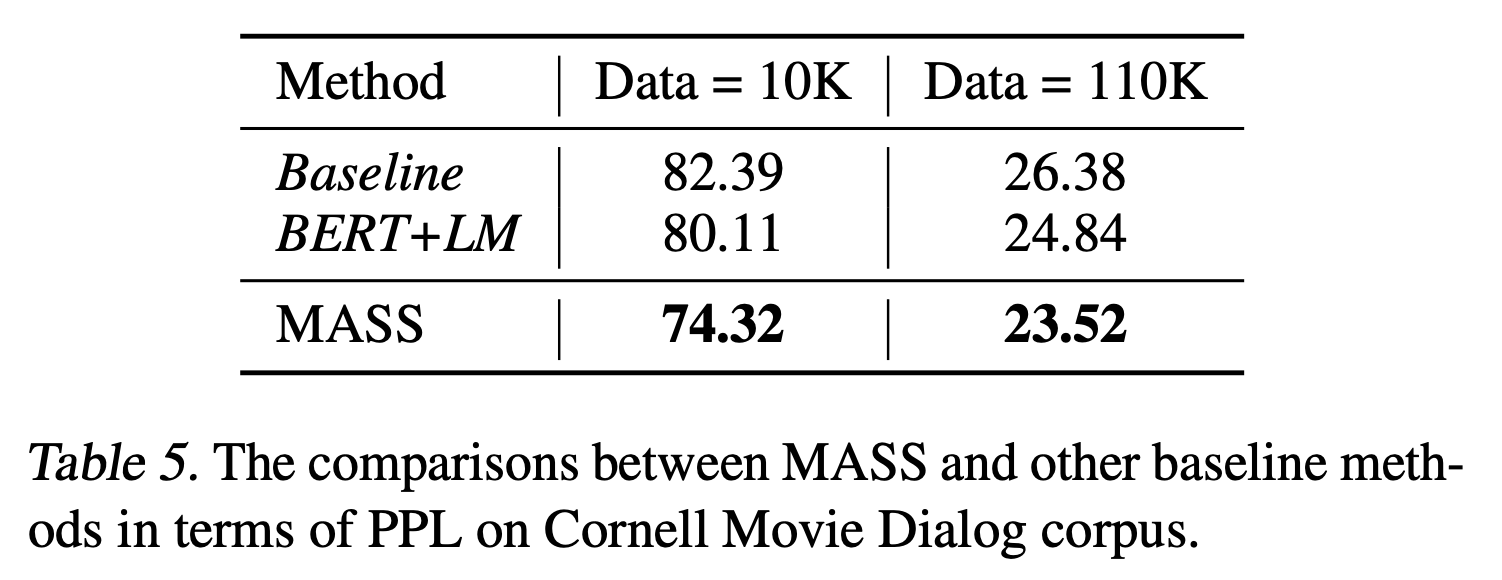
Sample 크기가 10K, 110K인 경우에 대해서 성능을 측정했다. MASS는 모든 경우에서 Pre-training을 수행하지 않은 Baseline Model과, Pre-training을 수행한 BERT Model보다 더 좋은 성능을 보였다. PPL은 더 낮은 Score가 더 좋은 성능을 뜻한다.
Analysis of MASS
Study of Different k
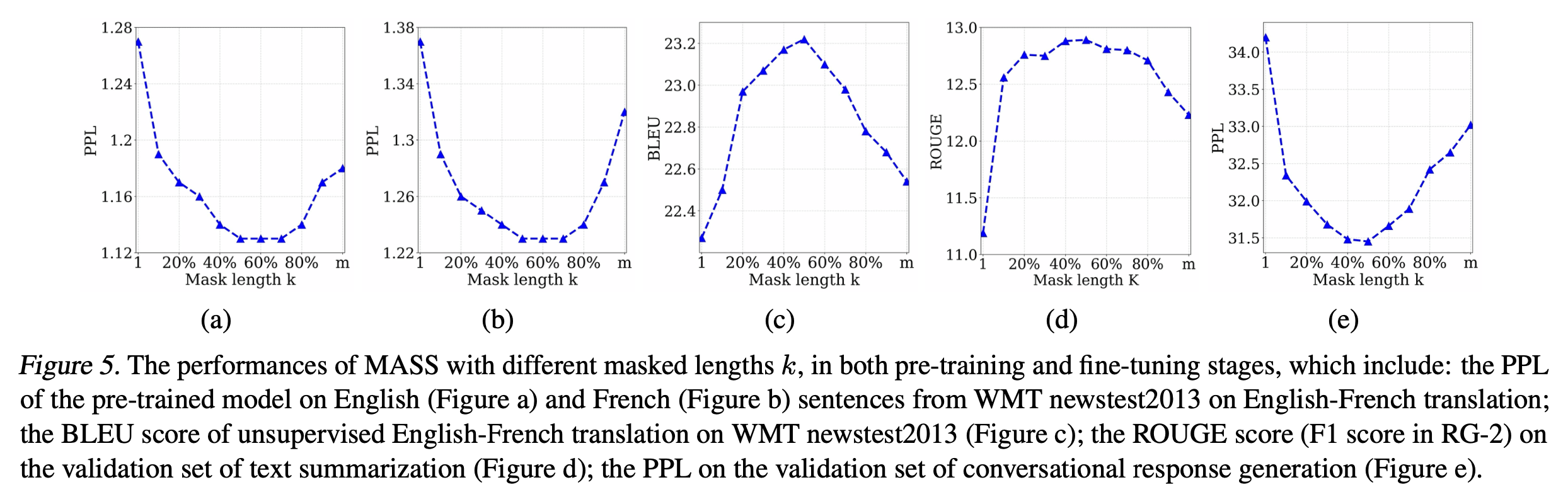
hyperparameter \(k\)에 대해서 자세히 살펴보자. \(k\)의 값 변화에 따른 Score들을 측정해본다.
(a)와 (b)는 각각 English, French에 대해 Pre-training을 시킨 직후(fine-tuning 없이)의 PPL Score를 나타낸 것이다. \(k\)가 \(m\)의 50%~70% 인 구간에서 가장 좋은 수치를 보였다.
(c)는 English-French NMT에 대한 BLEU Score이다. (d)는 Text Summarization에 대한 ROUGUE score이다. (e)는 Conversational Response Generation에 대한 PPL Score이다. 모두 공통적으로 \(k\)가 \(m\)의 50%인 구간에서 가장 좋은 수치를 보였다.
\(k\)가 \(m\)의 50%라는 수치는 직관적으로 이해했을 때에도 가장 적합하다.
\(k\)의 값이 감소한다면 masking을 덜 수행하게 되므로 Encoder Input에 변형이 덜 발생한다는 의미이며, 동시에 Decoder Input으로 들어오는 값이 감소함을 뜻한다. 따라서 Encoder에 대한 의존도를 높이게 된다.
반대로 \(k\)의 값이 증가한다면 masking을 더 많이 수행하게 되므로 Encoder Input에 변형이 더 발생한다는 의미이며, 동시에 Decoder Input으로 들어오는 값이 증가함을 뜻한다. 따라서 Decoder에 대한 의존도를 높이게 된다.
Language Generation task에서는 Encoder(source)와 Decoder(target) 중 어느 쪽으로도 편향되지 않아야 좋은 성능을 나타낼 것이다. 따라서 \(k\)가 \(m\)의 50%라는 수치가 가장 적합함을 직관적으로 이해할 수 있다.
위의 Figure에서도 볼 수 있듯이 당연하게도 \(k=1\)인 경우(BERT의 MLM), \(k=m\)인 경우(General Language Model) 모두 Language Generation task에서는 좋은 성능을 보이지 못한다.
Ablation Study of MASS

MASS에서 추가된 새로운 Masking Rule 다음의 2가지로 정리할 수 있다.
- MASK token을 연속적으로 배치
- encoder input의 unmasked token을 decoder input에서 masking
위의 Table의 Discrete는 1번 rule을 제거한 것이고(비연속적으로 MASK token 배치), Feed는 2번 rule을 제거한 것이다(decoder input이 original sentence). Unsupervised English to French NMT에서 MASS가 가장 좋은 성능을 보였다.
Conclusion
MASS는 Dataset이 적은 경우(또는 Dataset이 아예 없는 경우)의 Language Generation task에서 기존의 SOTA를 능가하는 성능을 보였다. 특히나 Unsupervised NMT에서 비약적인 성능 향상을 이뤄냈다.