Paper Info
Submit Date: Apr 06, 2020
Introduction
최근의 NLP model은 성능은 뛰어나지만 매우 model의 크기가 커 mobile device에서는 latency가 높아 사용이 어렵다는 단점이 있다. 본 논문에서 제시하는 MobileBERT는 knowledge transfer를 사용한 MobileBERT를 제안한다. 이 때 teacher model은 BERT large model에 bottleneck structure를 추가하고 multi-head attention layer와 feed-forward layer에 수정을 가한 inverted-bottleneck incorporated BERT (IB-BERT)이다. student model 역시 유사한 구조를 갖는다. 그 결과 최종적인 MobileBERT는 BERT base model에 비해 4.3배 작으며 5.5배 빠르면서 유사한 성능을 달성했다.
Related Work
BERT의 성능은 유지하면서 규모를 줄이려는 기존의 많은 연구들이 있었지만 대부분 fine-tuning 이후에서 knowledge transfer를 수행했다. 본 논문은 pre-train 직후의 BERT를 transfer해 MobileBERT가 task-agnostic(여러 downstream task에 general하게 활용될 수 있는 특성)한 특성을 유지하도록 한다. 또한 기존의 연구들은 대부분 BERT의 depth를 줄이는 방향으로 model의 규모를 축소했다면, 본 논문에서는 depth를 줄이는 대신 width를 줄이는 방향으로 규모를 줄였다.
MobileBERT
Bottleneck and Inverted-Bottleneck
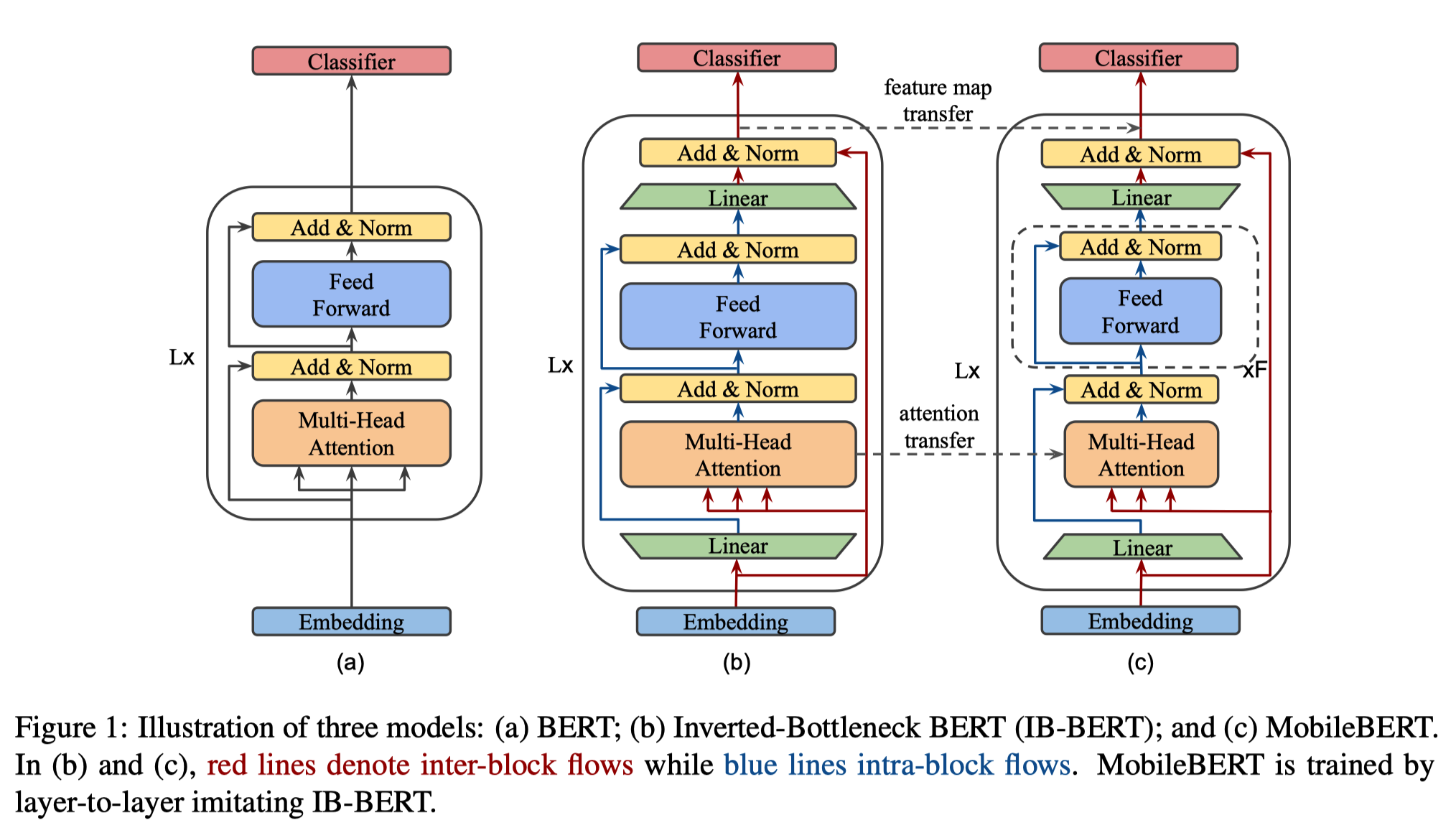
(a)는 original BERT이고, (b)는 IB-BERT, (c)는 MobileBERT이다. IB-BERT와 MobileBERT 모두 bottleneck structure 기반이다. bottleneck structure라는 것은 전체 Layer(여기서는 BERT Layer, 즉 Transformer Encoder Layer)의 input과 output에 dimension을 조절하기 위한 Linear Layer를 추가하는 것이다. 위 그림을 자세히 보게 되면 input Linear Layer에 통과하기 전(순수한 input embedding)을 MHA에서 query, key, value로 사용하고, 전체 Layer의 마지막에 Residual Connection으로 사용한다. 반면 input Linear Layer를 통과한 뒤의 embedding을 이후 MHA와 FFN의 Residual Connection에 사용한다. 즉, input Linear Layer 이전, 이후 embedding을 모두 사용한다. 이후에 다룰 knowledge transfer의 세부 작업에서 attention 값 자체 역시 transfer하게 되는데, 이를 위해서는 attention의 dimension이 teacher model과 student model에서 동일해야 하기 때문에 모두 동일하게 input Linear Layer 이전의 순수한 embedding 값을 MHA의 query, key, value로 사용하는 것이다. output Linear Layer는 dimension을 복구시켜 전체 layer의 input과 output dimension을 일치시키는 역할을 한다. 아래 table에서 각 model들의 세부적인 dimension을 비교해보자.
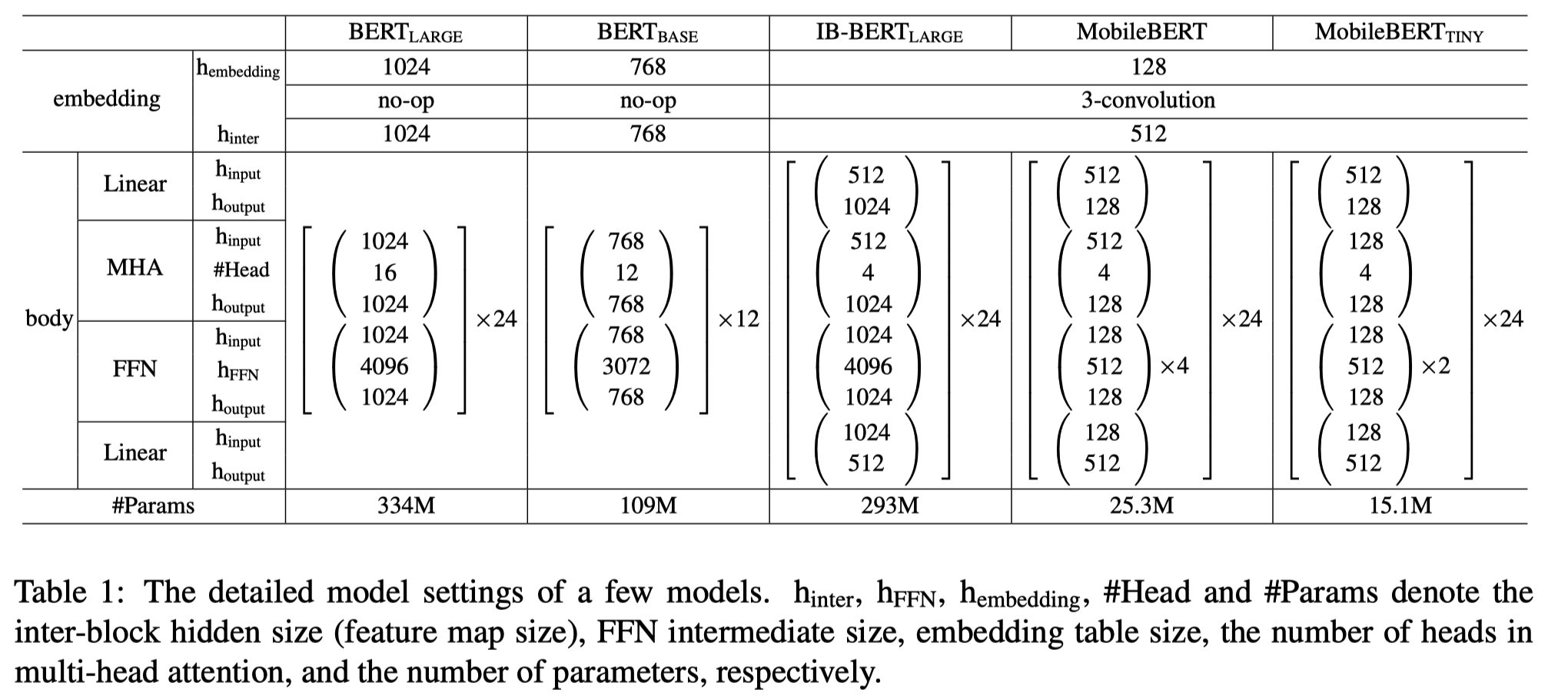
original BERT는 bottleneck structure가 아니기 때문에 input과 output에 추가적인 Linear Layer가 없다. embedding dimension을 \(d_{embed}\)라고 명명해보자. 위 표에서는 embedding의 \(h_{inter}\), MHA의 \(h_{input}\)이다. MHA의 input dimension은 \(d_{embed}\)일 것이다. BERT Large model은 \(d_{embed}=1024\)이다. 반면 bottleneck structure를 사용하는 IB-BERT나 MobileBERT는 모두 \(d_{embed}=512\)이다. 실제로는 input embedding의 dimension(\(h_{embedding}\))은 128이지만, 3개의 convolution layer를 거쳐가면서 최종적으로는 dimension이 512가 된다.
original BERT(정확히는 Transformer)에서는 \(d_{model}\)이라는 notation을 사용했다. MHA의 output, FFN의 input과 output의 dimension을 의미한다. 위 표에서는 MHA의 \(h_{output}\), FFN의 \(h_{input}\)과 \(h_{output}\)을 의미한다. BERT Large model은 \(d_{model}=1024\)이다. \(d_{model} = h \times d_{k}\)인데 BERT Large model은 \(h=16\)이므로 \(d_k=64\)가 된다. original BERT에서는 \(d_{embed}\)와 \(d_{model}\)가 모두 1024로 동일한 값이기 때문에 \(d_{embed}\)라는 notation을 따로 사용하지 않고 \(d_{model}\)로 통일했다. 하지만 bottleneck structure에서는 \(d_{model} \neq d_{embed}\)이기 때문에 두 값을 별개로 둔다.
IB-BERT는 \(d_{model}=1024\)이다. BERT Large model과 동일하다. 반면 MobileBERT는 \(d_{model}=128\)이다. BERT model의 depth(layer의 개수)는 수정하지 않고, model의 width(\(d_{model}\))을 대폭 줄여 model의 규모를 감소시킨 것이다. 정리하자면 bottleneck structure에서 input Linear Layer의 역할은 model의 width를 조절하는 것이다. 동일한 \(d_{embed}\) 하에서도 Linear Layer를 거쳐 다른 \(d_{model}\)(IB-BERT는 512, MobileBERT는 128)로 만들어낸다.
한편 bottleneck structure에서는 \(h\)가 4로 변경되었다. 위 표에서는 MHA의 \(\#Head\)이다. BERT Large model은 \(h=16\), BERT Base model은 \(h=12\)임을 생각하면 대폭 감소된 값이다. \(h\)의 직관적인 의미는 얼마나 많은 개수의 attention을 담을 것인가에 대한 수치인데 사실 IB-BERT에서 MobileBERT로 knowledge distillation을 수행해야 하는 것을 생각한다면 두 model의 \(h\)는 당연히 동일한 값이어야 한다는 사실을 알 수 있다. 그런데 \(h\)는 \(d_{model}=h \times d_k\)를 통해 도출되는 값이기 때문에 \(d_{model}\)이 고정적인데 \(h\)가 과도하게 크다면 \(d_k\)가 너무 작은 값이 되어버린다. \(d_k\)는 query, key, value vector의 dimension이기 때문에 \(d_k\)가 너무 작을 경우 각 token에 충분한 정보를 담을 수 없게 된다. 따라서 \(h=4\)라는 값을 사용하게 된다. MobileBERT가 \(d_{model}=128\)임을 생각했을 때 \(d_k=32\)가 되므로 BERT Large model의 \(d_k=64\)와 비교해보면 \(h=4\)가 적절한 값이라는 것을 알 수 있다.
FFN 내부에서는 \(d_{ff}\)라는 notation이 사용되는데 위 표에서 \(h_{FFN}\)을 의미한다. original BERT model에서는 \(d_{ff}=d_{model} \times 4\)였는데, bottleneck structure에서도 동일한 공식을 사용한다. 따라서 IB-BERT는 \(d_{ff}=4096\), MobileBERT는 \(d_{ff}=512\)이다.
original BERT model은 BERT Layer가 24층 쌓인 model이었다. IB-BERT와 MobileBERT 역시 동일하게 24개의 layer로 구성된다.
Stacked Feed-Forward Networks
original BERT에서 MHA와 FFN의 #parameter 비율은 항상 1:2였다. 하지만 bottleneck structure에서는 이 balance가 깨지게 된다. IB-BERT와 MobileBERT를 비교해보자. IB-BERT와 MobileBERT는 모두 \(d_{embed}=512\)로 동일하다. FFN에서는 input과 output이 모두 \(d_{model}\)이다. 반면 MHA의 경우에는 input은 \(d_{embed}\), output은 \(d_{model}\)이다. MobileBERT는 IB-BERT에 비해 \(d_{model}\)이 훨씬 낮기 때문에 MHA의 비율이 증가하게 된다. 이를 해결하기 위해서 FFN을 stack하게 된다. 구체적으로는 MobileBERT에서는 FFN을 4층 쌓는다. 이를 통해 MHA와 FFN의 비중을 유사하게 유지할 수 있게 된다.
Operational Optimizations
latency 관점에서 여러 실험을 진행해 본 결과 기존 BERT에서 gelu activation function과 layer normalization이 많은 latency를 발생시킨다는 점을 발견했다. 따라서 gelu를 ReLU로 변경하고, layer normalization을 새로 정의한다. 수식은 아래와 같다.
\[\text{NoNorm}(h)=\gamma \circ h + \beta\]\(\circ\)는 단순한 element-wise 곱셈 연산으로 기존의 layer normalization에 비해 연산량이 대폭 감소했다.
Embedding Factorization
kernel size 3인 1D convolution을 사용해 \(d_{embed}\)를 128에서 512로 변경했다.
Training Objectives
transfer 과정에서 student model의 각 layer는 그에 대응하는 teacher model의 layer를 통해 학습하게 된다. 단순히 model 전체의 최종 output만을 갖고 transfer하는 것이 아닌, 각 layer마다 별개로 transfer를 진행하는 것이다. 이 과정에서 FMT와 AT라는 2가지 loss를 결합해 사용하게 된다. 각각에 대해 알아보자.
Feature Map Transfer (FMT)
BERT layer의 최종 output을 transfer하는 것이다. 단순히 mean squared error를 사용한다.
\[L^l_{FMT}=\frac{1}{TN}\sum^T_{t=1}\sum^N_{n=1}\left(H^{tr}_{t,l,n}-H^{st}_{t,l,n}\right)^2\]\(l\)은 layer의 index이고, \(T\)는 sequence length, \(N\)은 feature map size이다. \(tr\)은 teacher model, \(st\)는 student model을 의미한다.
Attention Transfer (AT)
teacher model의 attention map을 transfer하게 된다. KL-divergence를 사용한다.
\[L^l_{AT}=\frac{1}{TA}\sum^T_{t=1}\sum^A_{a=1}D_{KL}\left(a^{tr}_{t,l,a} \Vert a^{st}_{t,l,a}\right)\]\(A\)는 attention head의 개수를 의미한다.
Pre-training Distillation (PD)
각 layer 단계에서의 knowledge transfer에 더해 전체 model의 knowledge distillation을 수행한다. distilBERT에서와 동일하게 MLM loss에 대해서만 knowledge distillation을 수행한다.
\[L_{PD}=\alpha \cdot L_{MLM} + \left(1-\alpha\right)L_{KD} + L_{NSP}\]\(L_{KD}\)는 teacher model과 student model 사이의 MLM에 대한 knowledge distillation loss이다.
Training Strategies
위에서 정의한 Objective Function을 통해 training을 하게 되는데, 이 때 사용할 수 있는 총 3가지 전략을 제시한다.
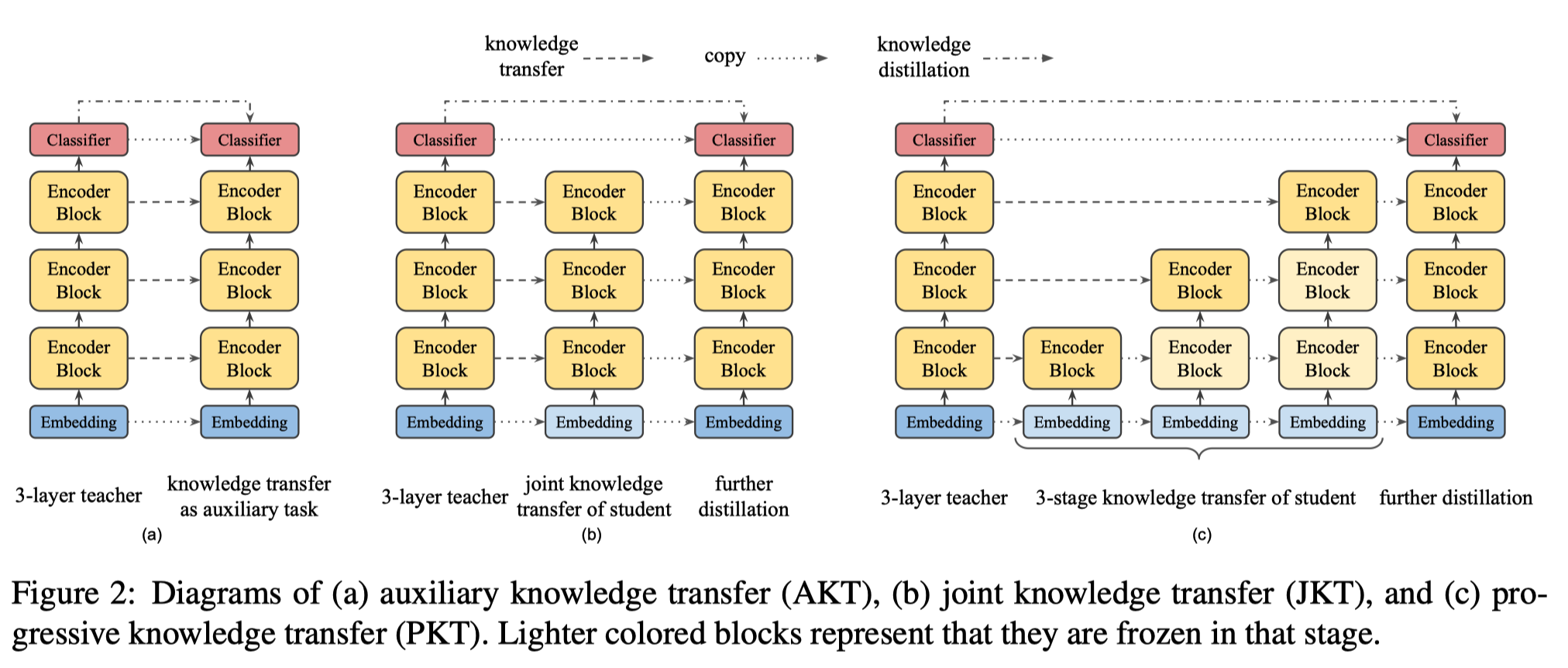
Auxiliary Knowledge Transfer (AKT)
각 layer마다 수행하는 knowledge transfer와 전체 BERT의 MLM에 대해 수행하는 knowledge distillation를 결합해 하나의 loss로 사용하는 방식이다.
Joint Knowledge Transfer (JKT)
각 layer마다 knowledge transfer를 우선적으로 수행하고, 모두 완료되고 나면 그 뒤에 knowledge distillation을 수행한다.
Progressive Knowledge Transfer (PKT)
JKT와 유사한데, knowledge transfer를 각 layer마다 순차적으로 수행하는 것이다. 이전 layer에 대해서는 freezing을 하게 된다. 그러나 실제로 사용될 때에는 아예 freezing하기 보다는 더 낮은 layer일수록 learning rate를 줄이는 방식으로 조절하게 된다.
Experiments
Model Settings
Architecture Search for IB-BERT
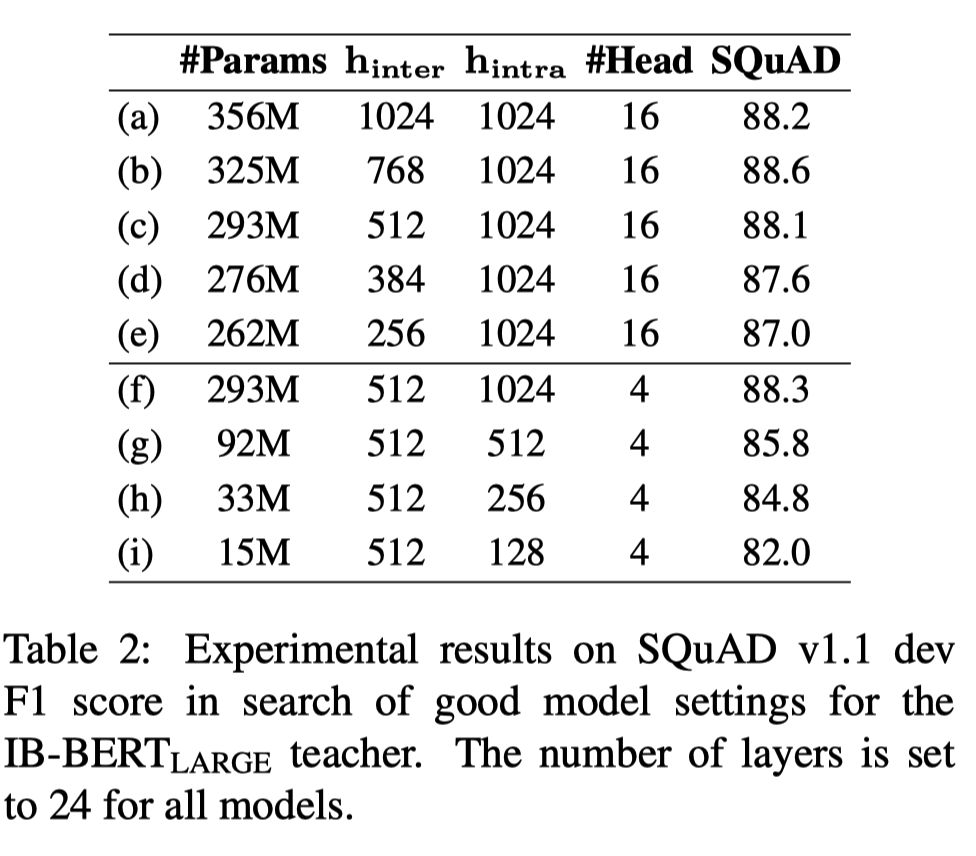
model의 parameter를 변경하며 SQuAD에 대한 F1 Score를 비교했다. \(h_{inter}\)는 \(d_{embed}\)를, \(h_{intra}\)는 \(d_{model}\)을 뜻한다. 모든 training은 batch size 2048로 125k step 수행했다.
적절한 \(h_{inter}\) 값을 찾기 위해 BERT Large model의 값인 1024부터 시작해 감소시키는 실험을 진행했다. 그 결과 \(h_{inter}\)가 512가 되는 시점부터 \(h_{inter}\)가 감소할수록 성능이 감소하는 것을 확인했다. 따라서 IB-BERT의 \(h_{inter}\)를 512로 채택했다.
이후 적절한 \(h_{intra}\) 값을 찾기 위해 똑같이 1024부터 시작해 감소시키는 작업을 진행했다. 그 결과 \(h_{intra}\)가 감소할수록 model의 성능이 급격히 감소하는 현상을 확인할 수 있었다. \(h_{intra}\)는 결국 BERT model의 representation power를 의미하는 것이기 때문에 IB-BERT는 \(h_{intra}\)를 감소시키지 않고 BERT Large model의 값인 1024를 그대로 채택했다.
Architecture Search for MobileBERT
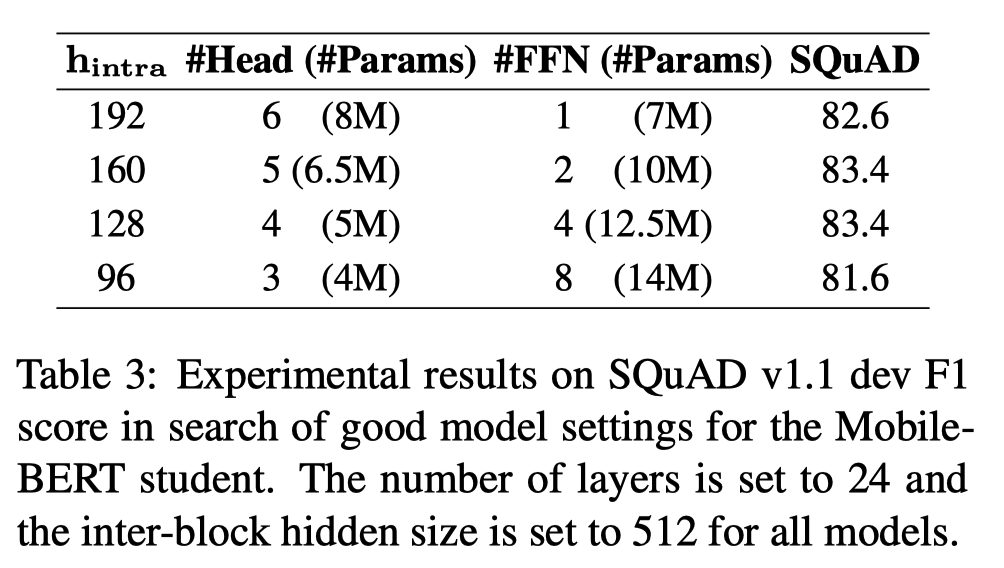
MobileBERT에서 MHA와 FFN 사이의 적절한 비율을 찾기 위한 실험을 진행했다. 그 결과 대체로 MHA의 #parameters와 FFN의 #parameters의 비율이 0.4~0.6인 구간에서 model의 성능이 가장 좋다는 것을 확인할 수 있었다. BERT Large model에서는 0.5를 채택했다. 따라서 \(h_{intra}=128\), \(\text{#FFN}=4\)를 채택했다. \(\text{#Head}=4\)는 teacher model의 값을 그대로 가져온 것인데, 실험을 해본 결과 multi-head의 개수는 성능에 큰 영향을 미치지 않는다는 사실을 발견했다. 이는 Table 2에서 (c)와 (f)의 성능이 거의 차이를 보이지 않는다는 점을 통해 알 수 있다.
Implementation Details
BERT와 공정한 비교를 위해 동일한 dataset과 같은 training 전략을 채택했다. fine-tunning에서 추가한 layer도 BERT의 것과 완전히 동일한 구조를 사용했다. fine-tuning에서 batch size, #epochs, learning rate 등의 hyper-parameter를 찾기 위한 search도 동일한 방식으로 수행했으나, search space는 original BERT와 차이가 있다. 대부분의 경우에서 MobileBERT는 original BERT보다 더 많은 epoch, 더 큰 learning rate를 필요로 했기 때문이다.
Results on GLUE
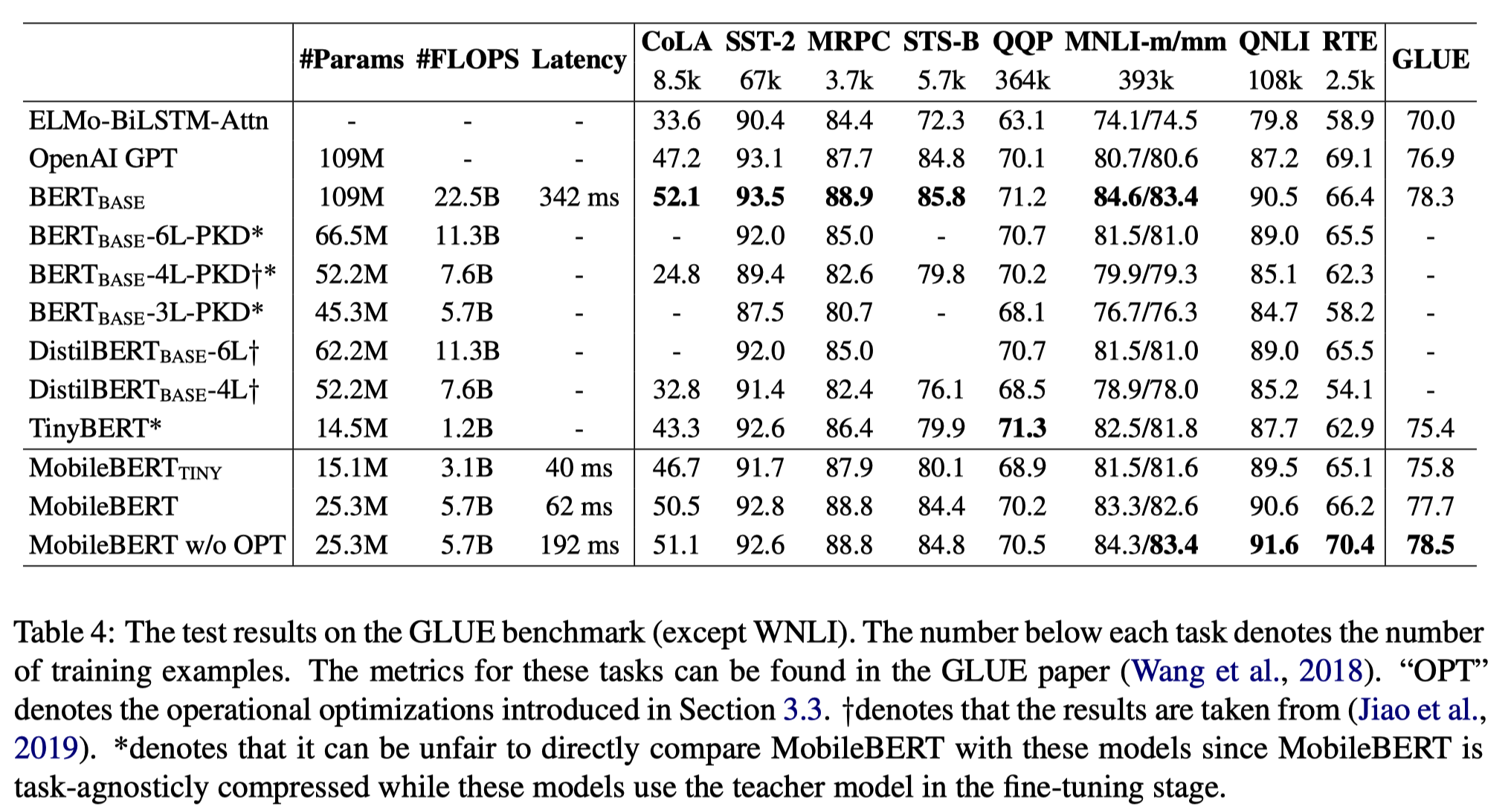
original BERT Base model과 ELMo, GPT 등의 SOTA model, DistilBERT, TinyBERT 등의 경량화 BERT model과 성능을 비교했다. MobileBERT_TINY는 MHA의 크기를 줄여 FFN을 stacking하지 않은 model이고, MobileBERT_w/o_OPT는 latency를 줄이기 위해 도입한 operational optimization을 제거한 model이다. 그 결과 MobileBERT는 BERT Base model의 4.3배 작은 크기로 0.6 낮은 GLUE Score를 달성했다. GPT, ELMo 등의 여타 SOTA model은 아예 능가하는 성능을 보였다. DistilBERT, TinyBERT보다도 대부분의 task에서 더 좋은 성능을 보였다. operational optimization을 제거한 경우에는 오히려 BERT Base model보다도 0.2 높은 수치를 달성했다.
inference time에서의 latency를 측정하기 위해 TensorFlow Lite를 사용해 Pixel 4에서 4-thread로 latency를 측정했다. 그 결과 sequence length 128일 때에 Mobile BERT는 62ms를 달성했다. 이는 BERT Base model보다 5.5배 빠른 수치이다.
Results on SQuAD
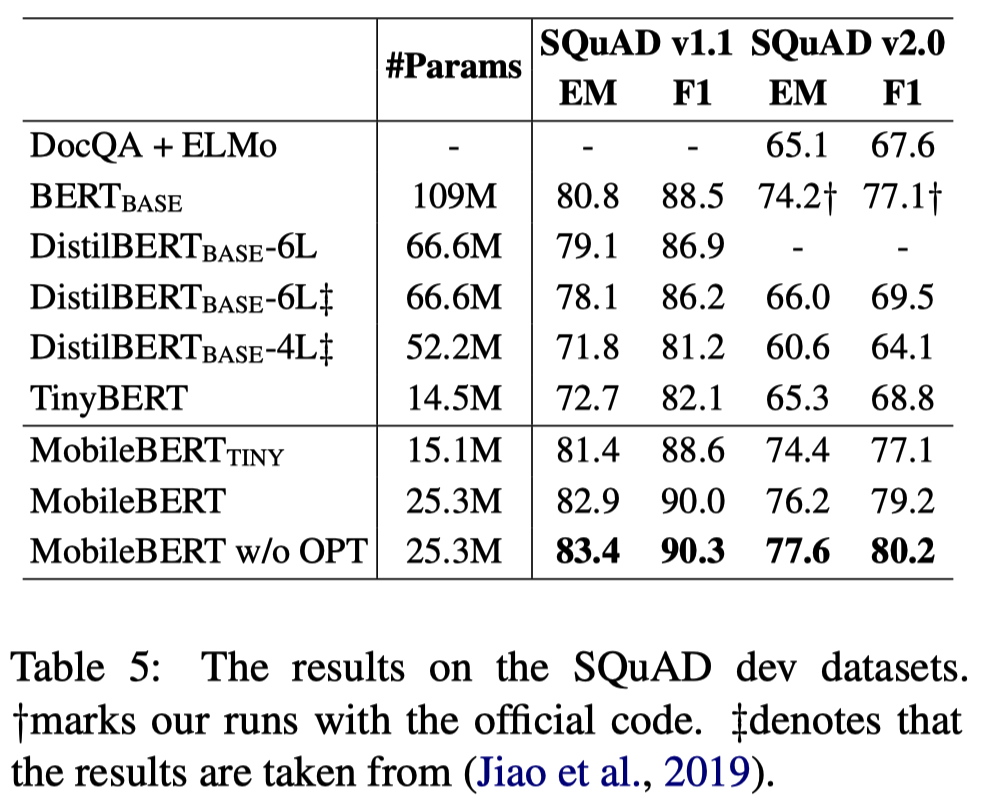
SQuAD에서는 BERT Base model을 능가했으며, 다른 경량화 model보다도 훨씬 좋은 성능을 보였다.
Quantization
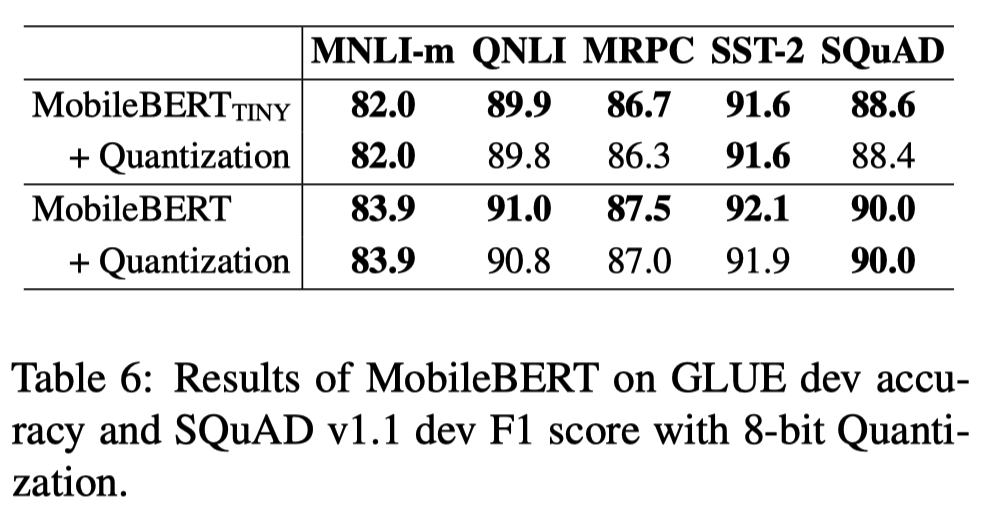
MobileBERT에 추가적으로 TensorFlow Lite에서 8-bit quantization을 수행했음에도 성능 하락이 발생하지 않았다. 이를 통해 여전히 더 경량화 가능한 지점이 많이 존재한다는 것을 알 수 있다.
Ablation Studies
Operational Optimizations
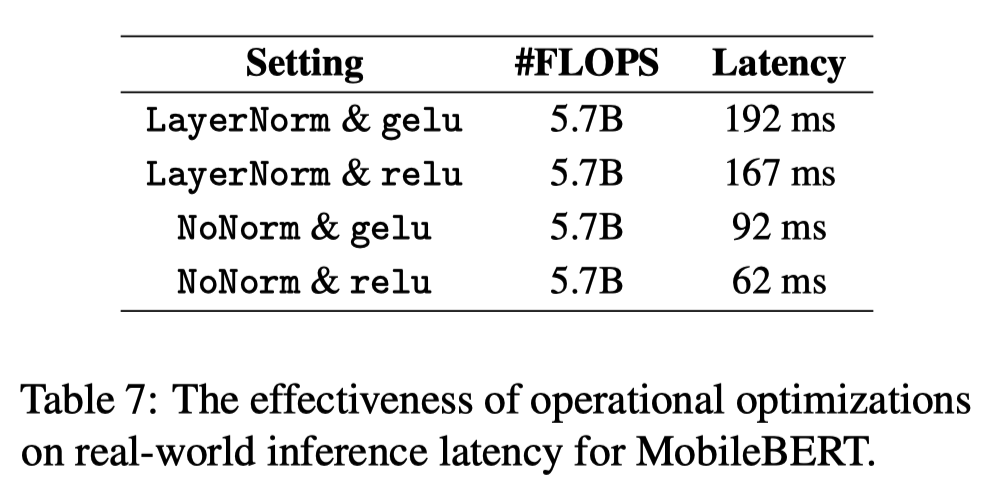
operational optimization에 대해 latency를 측정하는 실험을 진행했다. NoNorm과 relu를 사용한 경우에 가장 latency가 낮았다.
Training Strategies
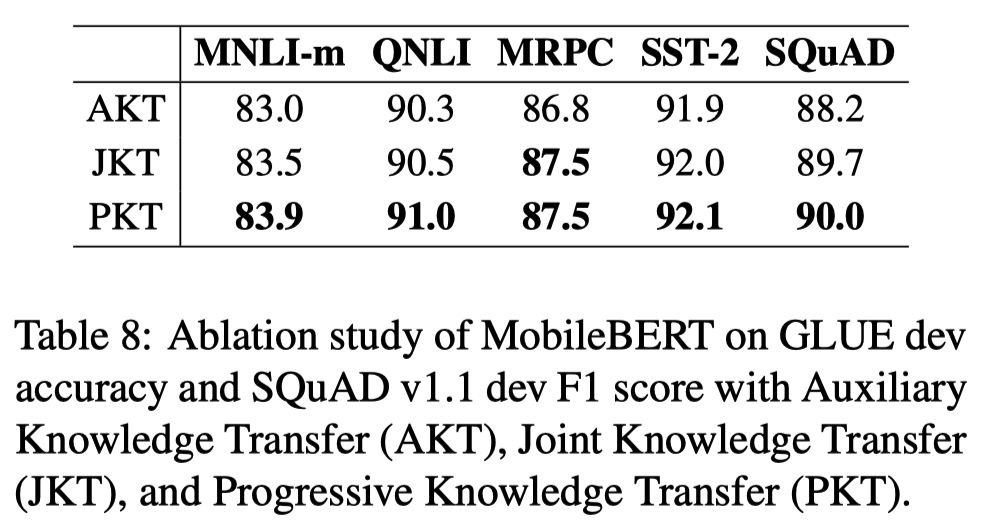
AKT, JKT, PKT의 tranining strategy를 비교하는 실험을 진행했다. 그 결과 PKT가 가장 좋은 성능을 보였으나 JKT와는 큰 차이가 없었다. AKT만이 유독 더 낮은 성능을 보였는데 teacher model의 layer-wise knowledge가 student model에게 optimal하지 않아 추가적인 knowledge distillation이 필요하다고 추측해 볼 수 있다.
Training Objectives
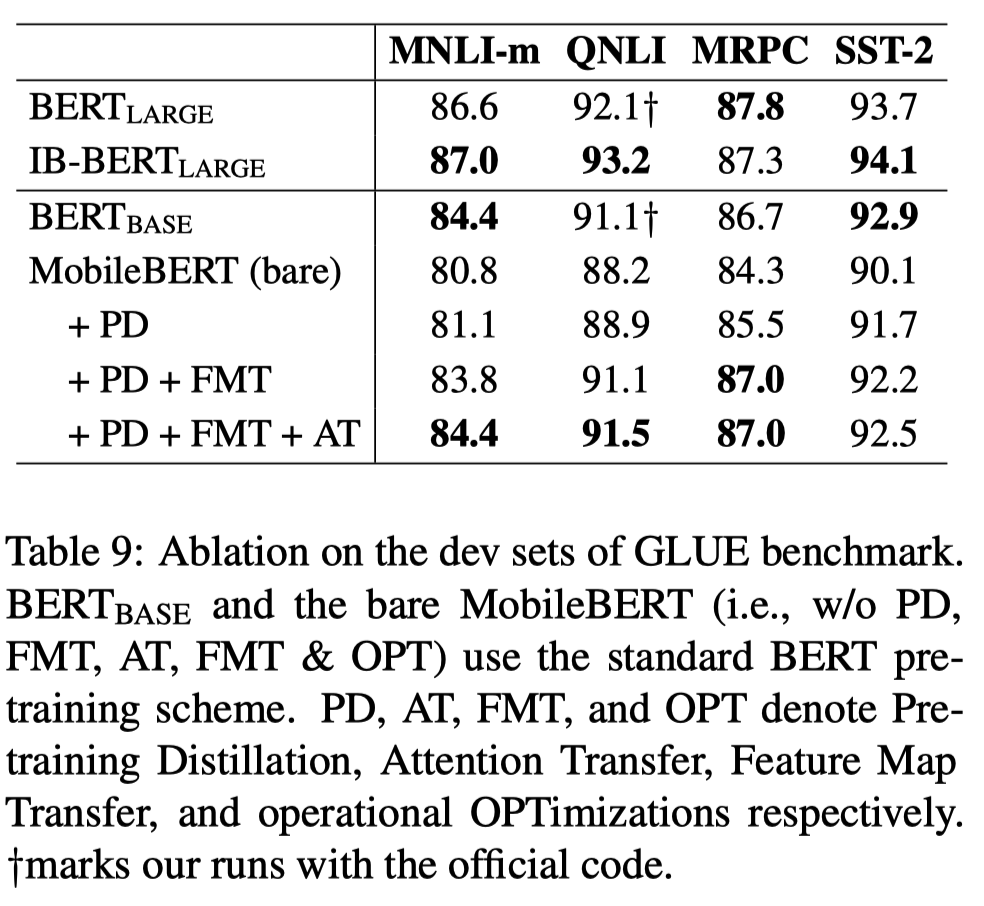
objective function을 수정하며 각각의 영향을 비교하는 실험을 진행했다. 그 결과 FMT(Feature Map Transfer)가 가장 큰 영향을 끼친다는 사실을 확인했다.
Conclusion
본 논문에서 제안한 MobileBERT는 BERT의 경량화 model로 mobile device에서 실행되기에 충분한 성능, 속도, 크기를 가졌다. BERT Base model과 비교했을 때 훨씬 빠르고 가벼우면서도 성능은 비슷하다. MobileBERT는 model의 depth는 유지하면서 width를 줄였으며, bottleneck structure를 채택했고, progressive knowledge transfer 전략을 사용했다. 각각의 요소들은 다른 model의 경량화에도 적용될 수 있을 것으로 기대한다.