[NLP 논문 리뷰] Neural Machine Translation By Jointly Learning To Align And Translate (Attention Seq2Seq)
17 May 2020
Paper Info
Submit Date: Sep 1, 2014
Abstract
기존의 seq2seq model에서 사용된 LSTM을 사용한 encoder-decoder model은 sequential problem에서 뛰어난 성능을 보였다. 하지만 encoder에서 생성해낸 context vector를 decoder에서 sentence로 만들어내는 위와 같은 방식에서 고정된 vector size는 긴 length의 sentence에서 bottleneck이 된다는 사실을 발견했다. 본 논문에서는 이러한 문제점을 해결하기 위해 source sentence의 정보를 context vector 하나에 담는 것이 아닌, 각 시점마다의 context vector를 따로 생성해 decoder에서 사용했다.
Decoder
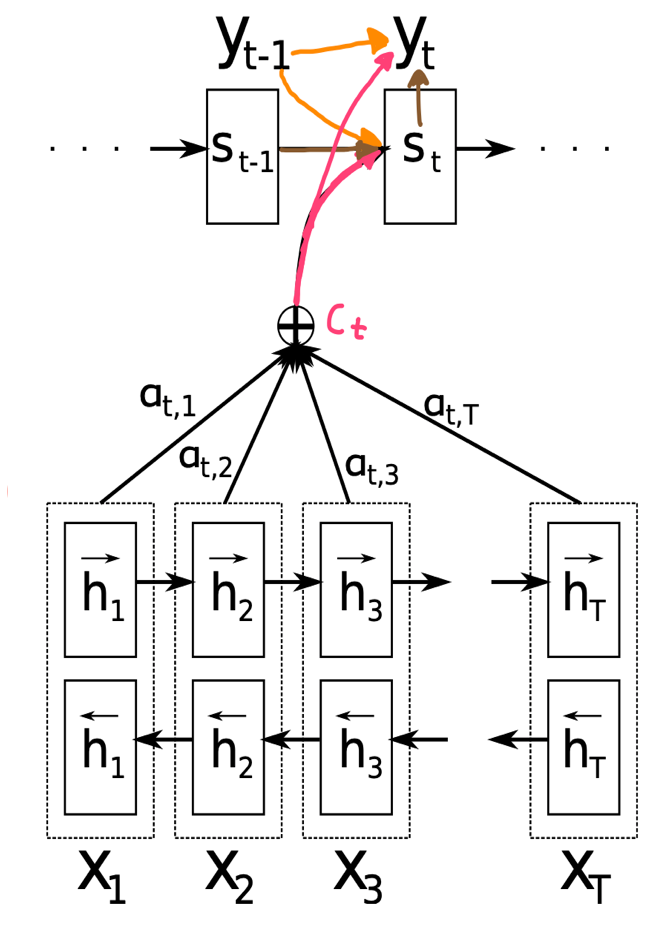
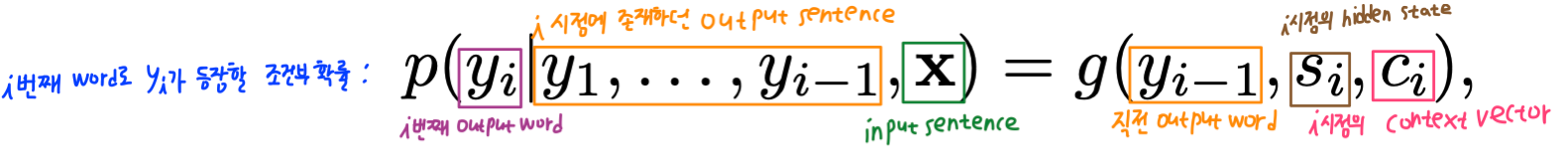
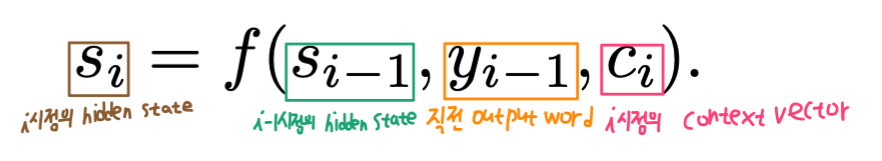
\(i\)번째 token으로 \(y_i\)가 등장할 조건부 확률에 대한 수식이다. \(y_1 \sim y_{i-1}\) (\(y_i\) 이전의 output sentence)와 \(x\)(input sentence 전체)에 대해 다음 token으로 \(y_i\)가 생성될 조건부 확률이다. 이는 \(g\) 함수에 \(y_{i-1}\), \(s_i\), \(c_i\)를 인자로 넣어 생성된 값이다. \(y_{i-1}\)은 직전 시점 \(i-1\)에서 생성한 output token이고, \(s_i\)는 현재 시점 \(i\)에서의 RNN hidden state, \(c_i\)는 현재 시점 i에 생성된 context vector이다. 직관적으로 해석해보면 이전 단어 \(y_{i-1}\) 이후에 나올 단어 \(y_i\)를 예측하는 것인데, 이 때 이전 output sentence의 상태 정보를 모두 포함하고 있는 \(s_i\)를 입력으로 받음으로써 output sentence의 문맥을 반영하고, input sentence에 대한 context vector \(c_i\)를 통해 input sentence의 문맥을 반영한다. 이전 seq2seq model에서는 context vector가 input sentence 전체에 대한 vector였는데, 이번 attention seq2seq model에서는 특정 시점 i에 대한 context vector \(c_i\)가 주어진다. 즉, context vector가 input sentence 전체에 대한 하나의 vector가 아니라 각 시점 i에 대해 \(c_i\)가 각각 정의된다는 것이다. 아래에서는 \(c_i\)에 대해 좀 더 자세하게 살펴본다.
\[c_i=\sum^{T_x}_{j=1}{\alpha_{ij}h_j}\]\(c_i\)는 \(a_{ij}\)와 \(h_j\)에 대해 \(j\)부터 \(T_x\)까지 더한 vector이다. \(j\)부터 \(T_x\)까지의 의미는 input sentence의 처음부터 끝까지 각 input token에 대해 \(j\)로 순회한다는 의미이다. 즉, \(j\)는 input sentence에서의 token index이다. 반대로 \(i\)는 output sentence에서 현재 시점 i이다. 정리하자면 \(j\)는 input에 대한 index, \(i\)는 output에 대한 index이다. 우리는 output의 \(i\) 시점에서 생성되는 context vector \(c_i\)에 대한 수식을 살펴보는 것이다. \(h_j\)는 input sentence 전체의 context를 포함하지만 동시에 특히 \(j\)번째 token과 그 주변에 대해 더 attention(집중)을 한 vector이다.\(a_{ij}\)는 \(i\)번째 output token이 \(j\)번째 input token과 align될 확률값을 뜻한다. \(a_{ij}\)에 대해 더 살펴보자.
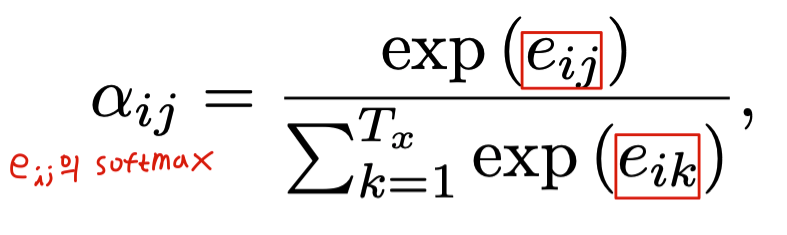
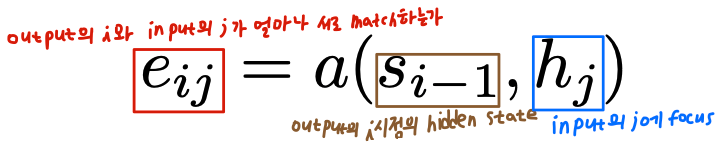
\(e_{ij}\)는 \(i\)번째에 들어올 output token과 \(j\)번째 input token이 얼마나 서로 잘 match되는지에 대한 값이다. output의 문맥을 반영하기 위해 \(s_{i-1}\)를 input으로 받고, \(j\)번째 input token에 대한 attention을 주기 위해 \(h_j\)를 input으로 받는다. 이렇게 완성된 \(e_{ij}\)를 softmax한 \(a_{ij}\)는 \(i\)번째 들어올 output token과 \(j\)번째 input token이 align될 확률값을 뜻한다.
다시\(c_i\)의 의미로 되돌아와보면, \(c_i\)는 \(i\) 시점에서 모든 input sentence token \(j\)에 대해 \(a_{ij}\)와 \(h_j\)를 곱한 vector에 대한 합이다. \(a_{ij}\)는 현재 시점 \(a_i\)에서 생성될 output token이 \(j\)번째 input token과 align될 확률값이며, \(h_j\)는 input sentence에 대한 context이되, \(j\)번째 input token에 특히 attention한 vector이다. 결론적으로 \(c_i\)는 현재 시점 \(i\)에서 input sentence의 어느 token에 더 attention을 해야 하는지에 대한 context라고 직관적으로 해석 가능하다.
위의 model이 기존 seq2seq model에 비해 가지는 이점은 encoder가 고정된 size context vector 1개에 모든 input sentence token에 대한 attention을 담을 필요가 없다는 것이다. 왜냐하면 decoder model에서 단지 context vector 1개만 사용해 output sentence를 생성해내는 것이 아니라, \(h_j\)와 같은 input sentence token에 대한 attention data를 사용하기 때문이다.
Encoder
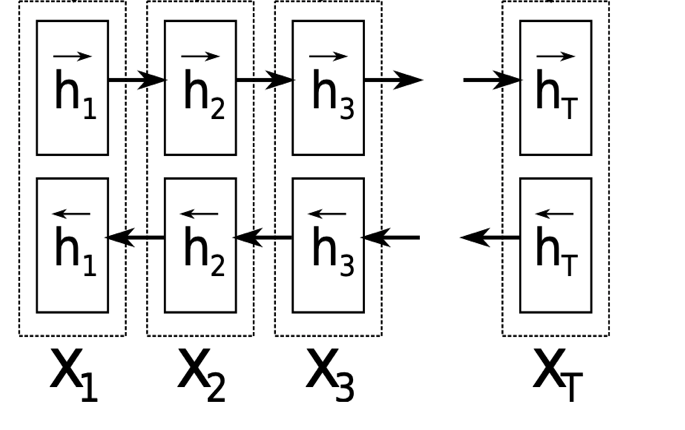
기존 seq2seq model에서는 encoder는 1개의 context vector를 생성해내기 위해 존재했다. 하지만 본 model은 위에서 언급했듯이 하나의 context vector가 아닌 각 시점에 대한 context vector를 각각 생성한다. 이 때 사용하는 \(h_j\)를 구하는 것이 encoder의 역할이다. \(h_j\)는 위에서 언급했듯이 \(j\)번째 input token에 대해 attention한 vector이다. 이 때 attention한다는 의미는 \(j\)번째 input token에 대해 당연히 가장 높은 가중치를 주고, \(j\)번째에서 멀어질수록 낮은 가중치를 주는 것이다. 이는 \(j-1\), \(j-2\) …의 역방향, \(j+1\), \(j+2\) …의 순방향, 즉 양방향에 대해 모두 적용되어야 한다. 이를 위해 사용한 것이 Bidirectional RNN이다. 순방향에 대한 \(h_j\)를 생성하고, input sentence의 끝에 도달하면 다시 역방향에 대한 \(h_J\)를 생성한다. 그 후 순방향에 대한 \(\overrightarrow{h_j}\)와 역방향에 대한 \(\overleftarrow{h_j}\)를 함께 반영해 최종 \(h_j\)를 만들어낸다.
Results
본 논문에서 개발한 attention seq2seq model을 RNNsearch라고 명명한다. 이전 seq2seq model은 RNNencdec라고 명명한다.
model 명 뒤의 숫자는 train 시 사용했던 dataset의 최대 setnence length이다.
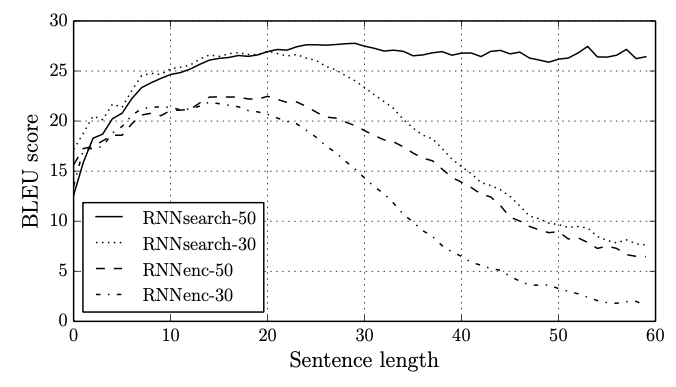
가장 주목할만한 점은 sentence length에 관계없이 robust한 결과를 보여줬다는 것이다. 이를 통해 fixed length context vector에 모든 context를 저장함으로써 발생한 bottleneck을 해결했다는 것을 알 수 있다.
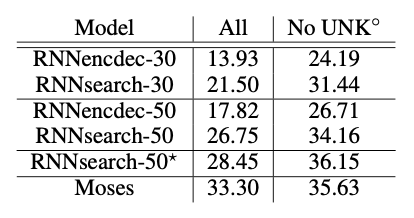
UNK (Out Of Vocabulary)를 포함한 경우와 포함하지 않은 경우 모두 기존 seq2seq model보다 월등한 수치를 보여줬다. RNNsearch-50*는 더이상 성능 향상이 없을 때까지 계속 training을 시킨 model이다.
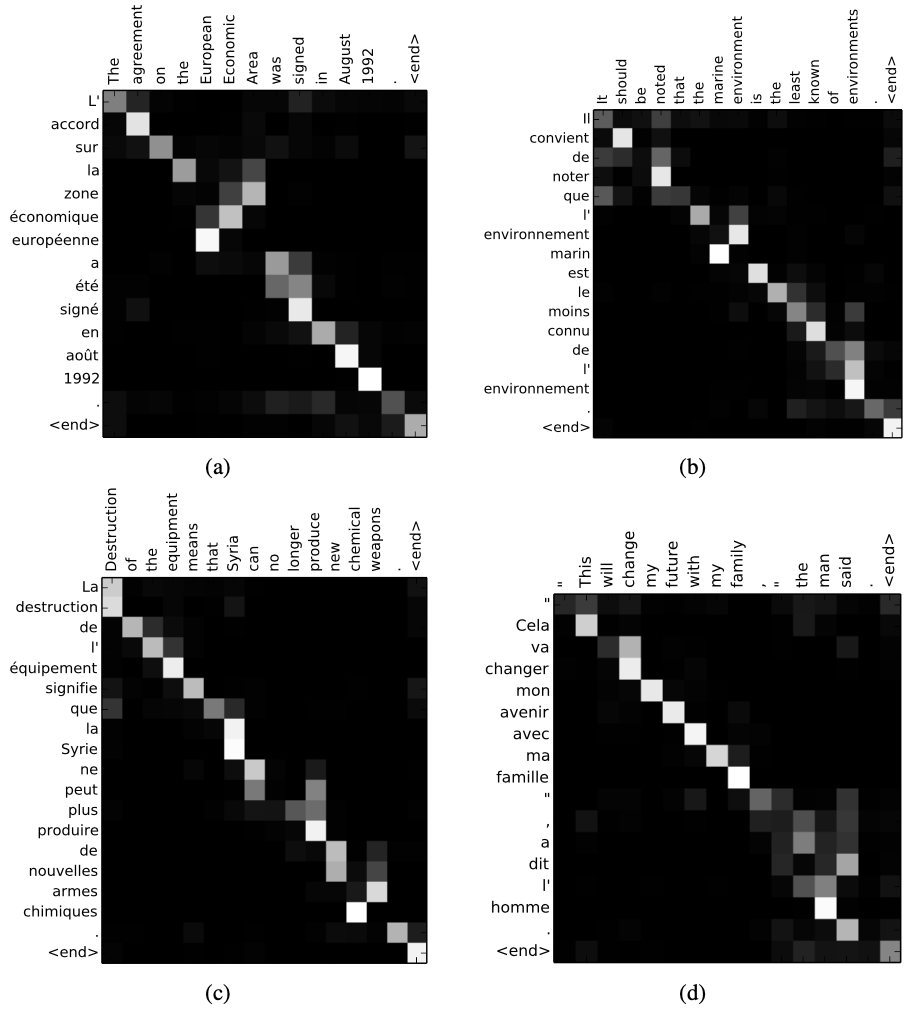
위는 \(a_{ij}\)를 시각화한 그림인데, 대체로 monotonic한 match를 볼 수 있다. English-French translate이기에 그렇다. 하지만 (a)를 보면 조사나 명사에 대해서 monotonic하지 않은 case가 있음에도 불구하고 정확히 align을 했다는 사실을 확인 가능하다. (d)에서는 본 model에서 채택한 soft-align 방식의 이점이 드러난다. soft-align이란 가장 높은 확률값을 가진 token pair 1개만을 채택해 align하는 것이 아니라 여러 token에 대해 각각의 align probability를 적용해 soft하게 align했다는 의미이다. 만약 soft-align이 아닌 hard-align을 했다면 [the man]의 2개의 token을 각각 [l’ homme]의 두 token 중 하나에 align해야 하는데 이러한 작업은 translation에 결코 도움이 되지 않는다. 따라서 soft-align을 사용해 여러 token에 대한 align을 모두 고려하는 방식이 적합하다는 것을 알 수 있다.