Paper Info
Submit Date: Aug 15, 2015
Backgrounds
BLEU Score (Bilingual Evaluation Understudy) score
\[BLEU=min\left(1,\frac{\text{output length}}{\text{reference_length}}\right)\left(\prod_{i=1}^4precision_i\right)^{\frac{1}{4}}\]reference sentence와 output sentence의 일치율을 나타내는 score이다. 3단계 절차를 거쳐 최종 BLEU Score를 도출해낸다.
- n-gram에서 순서쌍의 겹치는 정도 (Precision)
- Example
-
output sentence
빛이 쐬는 노인은 완벽한 어두운 곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다
-
true sentence
빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다
-
-
1-gram precision
\[\frac{\text{\# of correct 1-gram in output sentence}}{\text{all 1-gram pair in output sentence}}=\frac{10}{14}\] -
2-gram precision
\[\frac{\text{\# of correct 2-gram in output sentence}}{\text{all 2-gram pair in output sentence}}=\frac{5}{13}\] -
3-gram precision
\[\frac{\text{\# of correct 3-gram in output sentence}}{\text{all 3-gram pair in output sentence}}=\frac{2}{12}\] -
4-gram precision
\[\frac{\text{\# of correct 4-gram in output sentence}}{\text{all 4-gram pair in output sentence}}=\frac{1}{11}\]
- Example
- 같은 단어에 대한 보정 (Clipping)
- Example
-
output sentence
The more decomposition the more flavor the food has
-
true sentence
The more the merrier I always say
-
-
1-gram precision
\[\frac{\text{\# of 1-gram in output sentence}}{\text{all 1-gram pair in output sentence}}=\frac{5}{9}\] -
Clipping 1-gram precision
\[\frac{\text{\# of 1-gram in output sentence}}{\text{all 1-gram pair in output sentence}}=\frac{3}{9}\]
- Example
- 문장 길이에 대한 보정 (Brevity Penalty)
- Example
-
output sentence
빛이 쐬는 노인은 완벽한 어두운 곳에서 잠듬
-
true sentence
빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다
-
-
brevity penalty
\[min\left(1,\frac{\text{\# of words in output sentence}}{\text{\# of words in true sentence}}\right)=min\left(1,\frac{6}{14}\right)=\frac{3}{7}\]
- Example
- 최종 BLEU Score
- Example
-
output sentence
빛이 쐬는 노인은 완벽한 어두운 곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다
-
true sentence
빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다
-
-
BLEU Score
\[BLEU=min\left(1,\frac{\text{output length}}{\text{reference length}}\right)\left(\prod_{i=1}^4precision_i\right)^{\frac{1}{4}}\\=min\left(1,\frac{14}{14}\right)\times\left(\frac{10}{14}\times\frac{5}{13}\times\frac{2}{12}\times\frac{1}{11}\right)^{\frac{1}{4}}\]
- Example
출처: https://donghwa-kim.github.io/BLEU.html
Abstract
기존의 NMT (Neural machine translation)는 모두 고정된 개수의 vocabulary 안에서 작업했다. 하지만 translation은 vocabulary 개수의 제한이 없는 open-vocabulary problem이기 OOV(out of vocabulary) word가 많이 발생할 수밖에 없다. 본 논문에서는 이러한 OOV 문제를 subword unit 활용해 해결하고자 했다.
Introduction
기존의 NMT Model은 OOV words에 대해 back-off model 사용해왔다. back-off model 대신 본 논문에서 제시할 subword unit을 사용할 경우 OOV 문제를 더 확실히 해결해 open-vocabulary problem에서 성능 향상을 이끌어낼 수 있다.
Subword Translation
현재의 language model에서 translatable하지 않더라도, 다른 language의 translation의 sub word를 사용하면 translate이 가능하다.
- 이름 등의 고유 명사는 음절 별로 대응시킨다.
- Barack Obama (English; German)
- Барак Обама (Russian)
- バラク・オバマ (ba-ra-ku o-ba-ma) (Japanese)
- 동의어, 외래어 등 같은 origin을 갖는 단어들은 일정한 규칙을 갖고 변형되므로, character-level translation 사용한다.
- claustrophobia (English)
- Klaustrophobie (German)
- Клаустрофобия (Klaustrofobiâ) (Russian)
- 복합어는 각각의 sub-word를 번역한 후 결합한다.
- solar system (English)
- Sonnensystem (Sonne + System) (German)
- Naprendszer (Nap + Rendszer) (Hungarian)
위와 같은 규칙으로 german training data에서 가장 빈도 낮은 100개의 word를 분석하면 english data를 통해 56개의 복합어, 21개의 고유명사, 6개의 외래어 등을 찾아낼 수 있었다.
Related Work
OOV는 고유명사 (사람 이름, 지역명), 외래어 등에 대해서 자주 발생한다. 이를 해결하기 위해 character level로 word를 분리한 뒤, 각 character들이 일정한 기준을 충족할 경우 하나의 token으로 묶어 표현하는 방식을 채택했다. 이를 통해 text size는 줄어들게 된다. 이 때 단어를 subword로 구분하는 기존의 Segmentation algorithm을 사용하되, 좀 더 aggressive한 기준을 적용하고자 했다. vocabulary size와 text size는 서로 trade-off 관계이므로 vocabulary size가 감소한다면 시간/공간 복잡도는 낮아지겠지만 unknown word의 개수가 증가하게 된다.
Byte Pair Encoding (BPE)
import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'low</w>' : 5, 'lower</w>' : 2,
'newest</w>' : 6, 'widest</w>' : 3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)
# r . -> r.
# l o -> lo
# lo w -> low
# e r. -> er.
BPE는 가장 빈도가 높은 pair of bytes부터 하나의 single byte로 치환해 저장하는 압축 algorithm이다.
BPE는 다음과 같은 과정을 따른다.
- word를 character의 sequence로 변환 후 end symbol · 추가
- 모든 character의 pair를 센 후 가장 빈도가 높은 pair of character (‘A’, ‘B’)를 새로운 symbol ‘AB’ (character n-gram)로 치환
- 2번 단계를 원하는 횟수만큼(vocabulary size만큼 token이 생성될 때까지) 반복
BPE의 반복 횟수는 vocabulary size라는 hyperparameter에 따라 결정된다.
- 예시
-
train sentences
sentence = [ 'black bug bit a black bear but is the black bear that the big black bug bit', 'a big bug bit the little beetle but the little beetle bit the big bug back'. 'the better with the butter is the batter that is better' ] -
count segments
[('t h e </w>', 8), ('b l a c k </w>', 4), ('b i t </w>', 4), ('i s </w>', 3), ('b i g </w>', 3), ('b e a r </w>', 2), ('b u t </w>', 2), ('t h a t </w>', 2), ('l i t t l e </w>', , 2), ('b e e t l e </w>', 2), ('b e t t e r </w>', 2), ('b a c k </w>', 1), ('w i t h </w>', 1), ('b u t t e r </w>', 1), ('b a t t e r </w>', 1)] -
count bi-grams
[(('t', 'h'), 11), (('h', 'e'), 8). (('t', '</w>'), 8), (('g', '</w>'), 7)] -
add merge-rules
('t', 'h') -> th ('h', 'e') -> he ('t', '</w>') -> t</w> ('g', '</w>') -> g</w>
-
Evaluation
Subword statistics
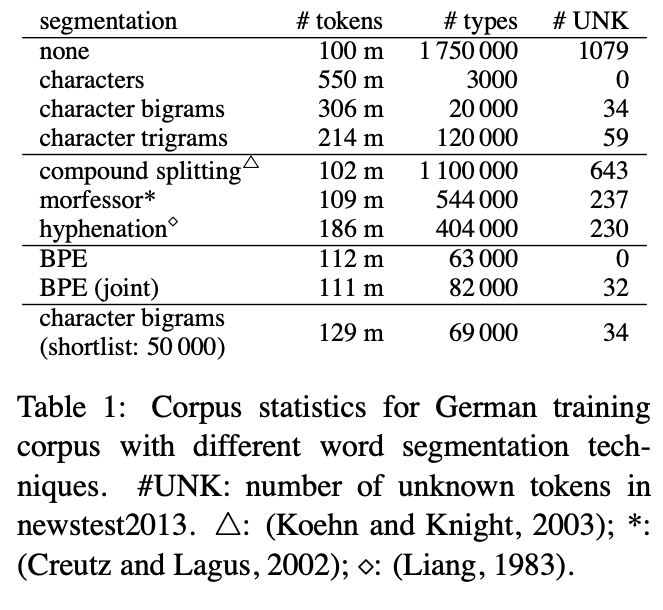
-
tokens: text size
-
types: vocabulary size, token 개수
-
UNK: unknown word (OOV word)의 개수
Translation experiments
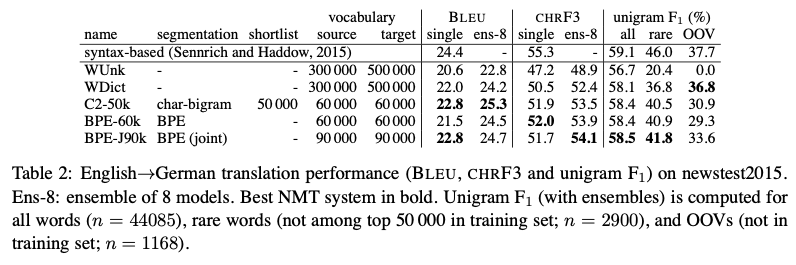
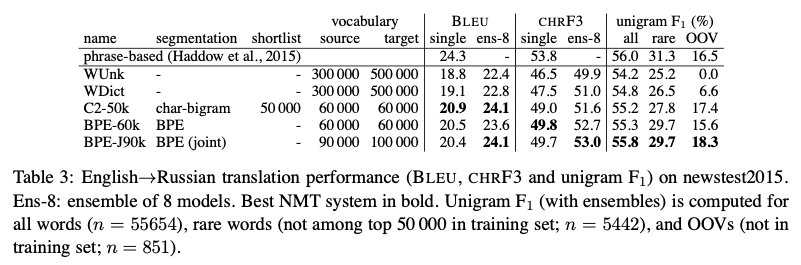
- W Unk: back-off dictionary를 사용하지 않은 model이다.
- W Dict: back-off dictionary를 사용한 model이다.
- C2-50k: char-bigram을 사용한 model이다.
- CHR F3: 인간의 판단과 일치율
- unigram F1: BLEU unigram(brevity penalty 제외)와 Recall의 조합
source와 target 각각 따로 BPE를 수행하는 BPE보다 동시에 수행하는 BPE joint가 더 좋은 성능을 보였다.
Analysis
Unigram accuracy
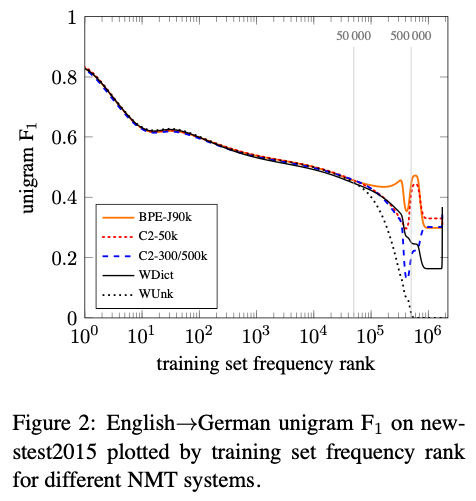
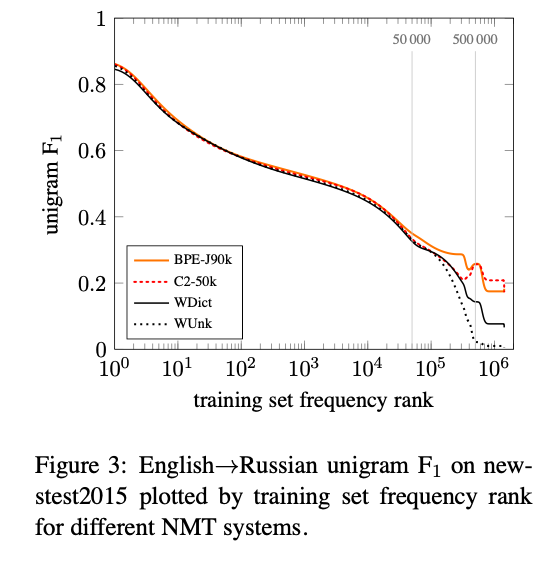
Manual Analysis
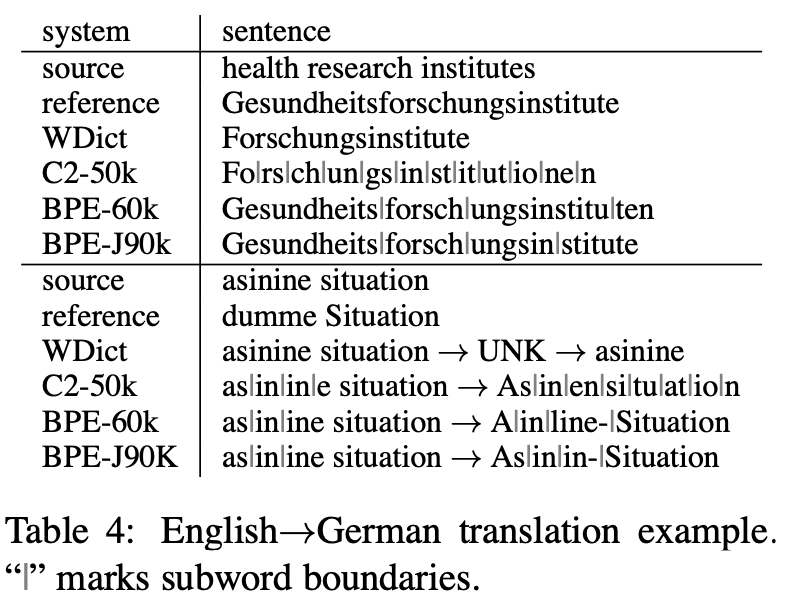
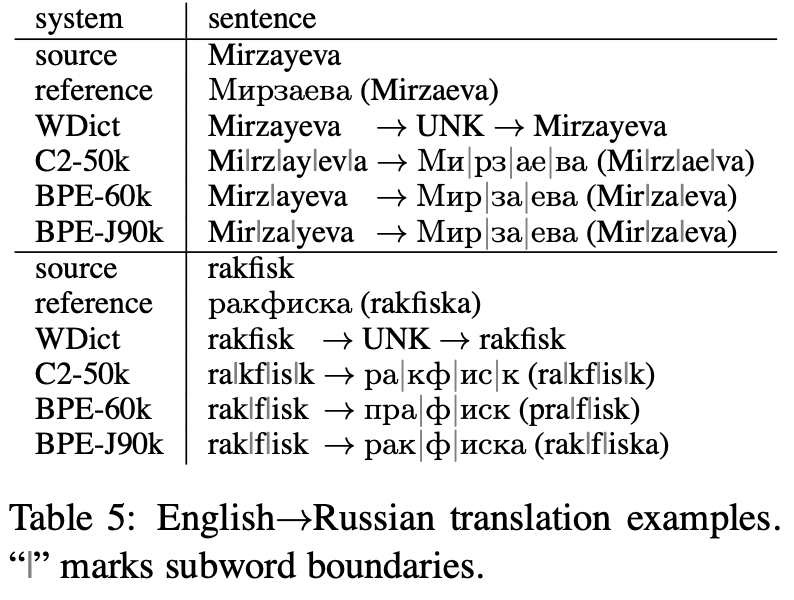
Conclusion
OOV 문제를 해결해 NMT와 같은 open-vocabulary translation에서 좋은 성능을 보였다. 기존에 OOV를 해결하기 위해 사용되던 back-off translation model보다 더 좋은 성능을 보였다.