Paper Info
Submit Date: Jul 26, 2019
Introduction
BERT 계열의 model들은 지금까지 매우 뛰어난 성능을 보여왔다. 본 논문에서는 BERT에 대한 추가적인 연구를 통해 기존의 BERT model들이 undertrained되었음을 보여주고, 다음의 개선 방안들을 제시한다.
- 더 긴 시간, 더 큰 batch size의 training
- NSP 제거
- long sequence에 대한 학습
- MLM에서의 동적인 masking 정책
본 논문의 Contribution은 다음과 같다.
- downstream task에서의 성능 향상을 위한 BERT model의 design choice, training 전략을 제시
- 새로운 CC-NEWS dataset을 도입
- 적절한 design choice에 기반한 MLM이 다른 여러 method 대비 좋은 성능을 보임을 입증
Background
BERT에 대한 overview
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 참고
Experimental Setup
Implementation
대부분의 hyperparameters의 값은 BERT와 동일한 값을 채택했다. 하지만 peak learning rate와 #warmup steps, Adam epsilon에 대해서는 tuning을 진행했다. 전체 sequence의 최대 길이 T는 512로 했다.
Data
BERT-style의 pretraining 방식은 data의 양에 따라 성능이 결정된다. BERT 이후 더 큰 dataset을 사용한 여러 연구가 진행되었으나, 그 dataset이 공개되지는 않았다. 본 논문에서는 총 160GB의 4개의 English dataset을 사용했다.
-
Book Corpus + Wikipedia
Original BERT에서 사용했던 dataset으로, 총 16GB이다.
-
CC-News
총 63million개의 2016/09~2019/02 사이의 뉴스 기사를 crawling한 dataset으로, 총 76GB이다.
-
OpenWebText
Reddit과 같은 web site에서 URL 기반으로 crawling을 한 dataset으로, 총 38GB이다.
-
Stories
story-like dataset으로, 총 31GB이다.
Evaluation
-
GLUE
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 참고
-
SQuAD
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 참고
-
RACE
ReAding Comprehension from Examinations이다. 중국에서의 Enghlish Examination에서 추출한 28,000개의 단락과 100,000개의 질문이 존재한다. 각 단락은 여러 질문과 함께 등장하는데, 그 중 하나의 알맞은 질문을 고르는 task이다. 기존의 다른 comprehension dataset에 비해 passage의 길이가 길고, 추론 질문의 비율이 높다는 점에서 차이가 있다.
Training Procedure Analysis
BERT model L=12, H=768, A=12, #params: 110M으로 은 고정해둔 상태로 실험을 진행한다.
Static vs Dynamic Masking
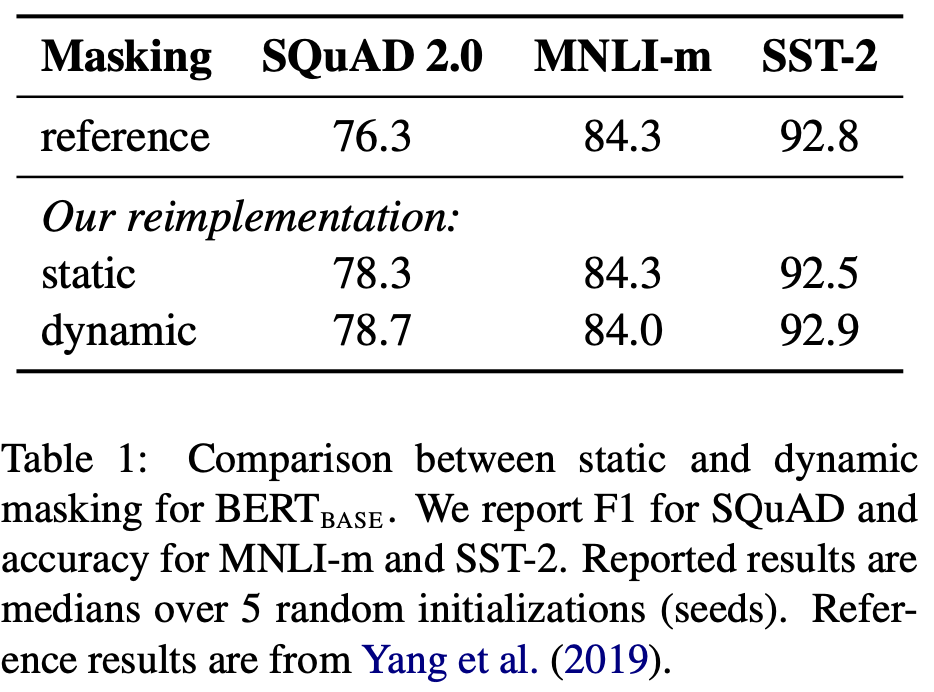
본 논문에서는 Dynamic Masking 기법을 도입했다. 기존의 BERT에서의 Masking Rule은 전처리 과정에서 한 번 수행한 masking이 계속 유지되는 Static Masking이다. 이는 매 epoch마다 동일한 masking으로 학습을 하게 됨을 의미한다. Dynamic Masking은 training data를 10배로 복제해 각각의 training data마다 다른 masking을 수행했다. 같은 비율의 masking 정책 하에서 (80%/10%/10% 등) 다른 word가 masking되는 것이다. 이를 40 epochs동안 수행하는데, 결국 같은 masking으로 총 4epochs의 학습이 이루어지게 되는 것이다. 이러한 Dynamic Masking 기법은 dataset이 클 수록 Static Masking 대비 더 큰 성능 향상을 보였다. 위 Table에서 볼 수 있듯이 static 대비 dynamic masking이 조금이나마 더 좋은 성능을 보였다.
Model Input Format and Next Sentence Prediction
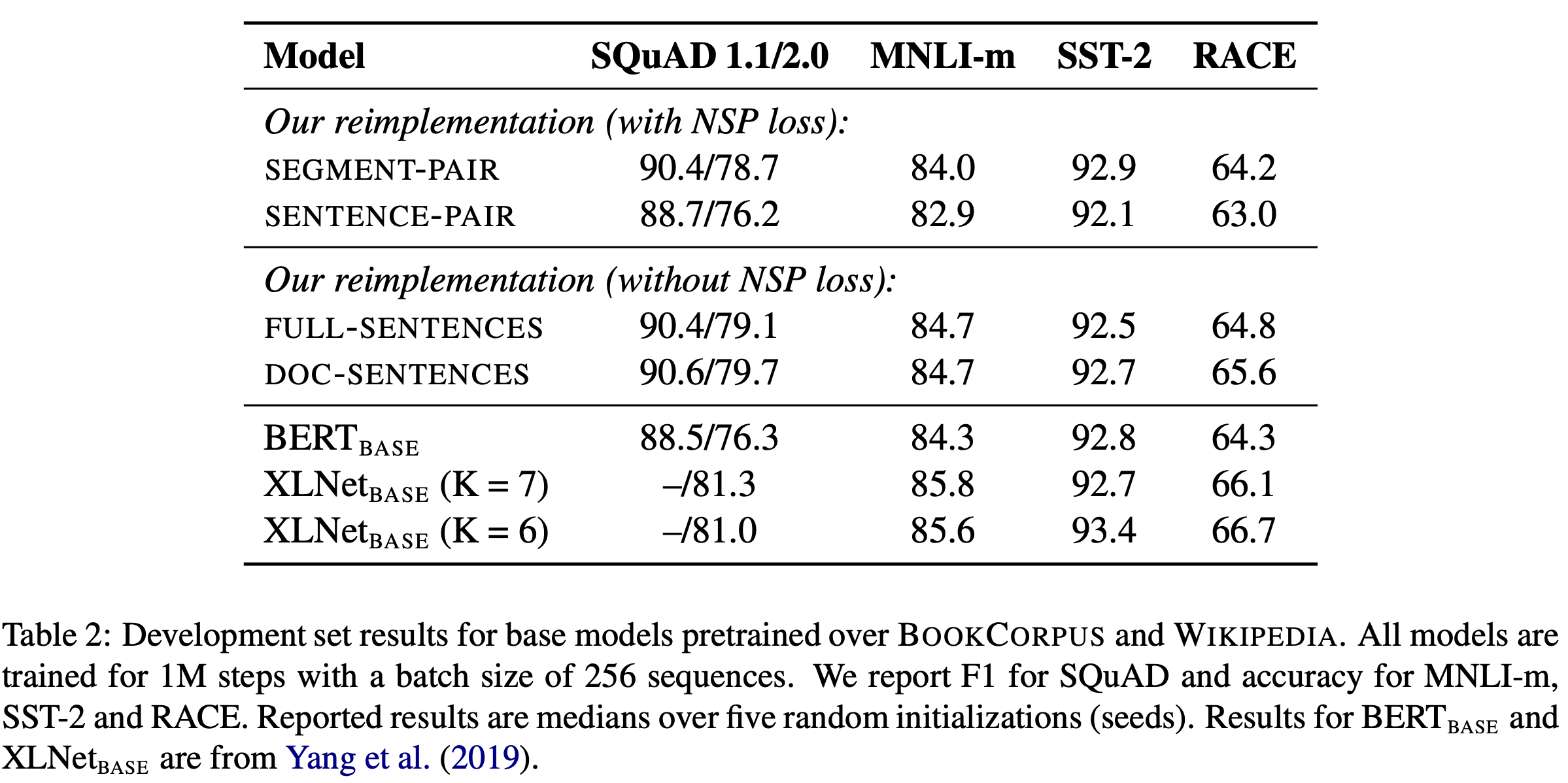
NSP가 성능 향상에 얼마나 기여하는지에 대해서는 많은 연구가 있어왔고, 때로는 각 논문마다 다른 결과를 도출해내기도 했다. 이를 검증하기 위해 위와 같은 실험을 진행했다. 각 항목에 대해서 자세히 살펴보겠다.
-
SEGMENT-PAIR
여러 문장으로 이루어질 수 있는 segment의 pair이다. 한 pair는 최대 512 tokens까지 가질 수 있다. NSP를 포함한다.
-
SENTENCE-PAIR
문장의 pair이다. 한 pair는 최대 512 tokens까지 가질 수 있다. 당연하게도 평균적인 #tokens가 SEGMENT-PAIR보다 작기 때문에, batch size를 늘려 SEGMENT-PAIR의 한 batch와 total #tokens가 비슷해지도록 했다. NSP를 포함한다.
-
FULL-SENTENCES
여러 문장들의 sequences이다. 최대 512 tokens까지 가질 수 있다. 문장이 중간에 끊기는 일은 없도록 한다. 특수한 경우로, 한 document가 끝났음에도 새로운 문장이 삽입될 수 있을 경우, 다음 document의 첫 문장부터 이어서 삽입되게 된다. 이 경우에 있어서는 서로 다른 document에서 온 문장 사이에 특수한 seperator token이 삽입된다. NSP를 포함하지 않는다.
-
DOC-SENTENCES
FULL-SENTENCES와 유사하지만, 서로 다른 document에서 온 문장이 연속되는 일이 없도록 한다. 당연하게도 FULL-SENTENCES에 비해 평균 #tokens가 낮을 수 밖에 없기 때문에, 이 역시 batch size를 늘려 FULL-SENTENCES의 한 batch와 total #tokens가 비슷해지도록 했다. NSP를 포함하지 않는다.
SEGMENT-PAIR와 SENTENCE-PAIR를 비교해보자. SENTENCE-PAIR가 더 낮은 성능을 보였다. SENTENCE-PAIR는 model이 long-range dependencies를 학습할 능력이 없다고 가정한 것인데, 실제로는 BERT model이 long sequences에 대해서도 dependency를 학습할 수 있음을 알 수 있다.
한편, DOC-SENTENCES와 BERT_BASE를 비교해보면 DOC-SENTENCES가 original BERT보다 더 좋은 성능을 보인다는 것을 확인할 수 있다. 이는 NSP가 오히려 downstream task의 성능에 악영향을 미친다는 것을 보여준다.
마지막으로, FULL-SENTENCES와 DOC-SENTENCES를 비교하면 한 document 안의 문장만 묶는 DOC-SENTENCES가 미약하게나마 더 좋은 성능을 보인다는 것을 확인할 수 있다. 하지만 DOC-SENTENCES는 batch size가 각 batch마다 다르기 때문에, 본 논문의 이후 실험에서는 편리성을 위해 FULL-SENTENCES를 사용하기로 한다.
Training with large batches
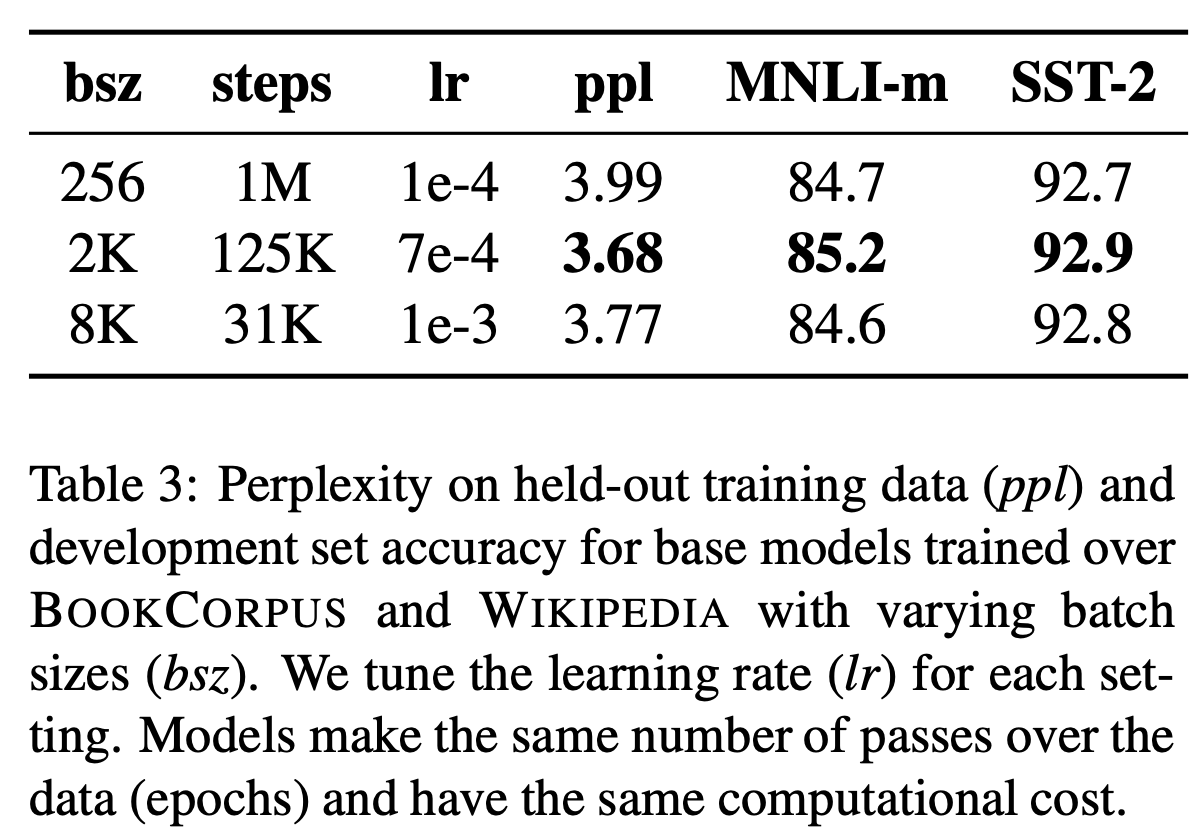
batch-size를 증가시킬수록 optimization speed와 성능 향상에 기여한다는 것은 알려져 있다. BERT 역시 larget batch size가 효과가 있는지 확인을 해보기로 한다. batch size=256, #steps=1M은 original BERT_BASE의 값이다. 이와 동일한 computational cost를 갖는 다른 batch size & #steps를 실험해본다. 실제로 같은 computational cost를 갖는 경우에도 batch size가 커질수록 perplexity가 감소함을 확인할 수 있었다. end-task에서의 정확도도 상승했다.
Text Encoding
BPE는 등장 빈도를 기반으로 subword를 생성해내는 기법으로, OOV가 없다는 장점이 있다. 기존의 BPE는 모두 character 단위로 이루어졌는데, original BERT도 이를 채택했다. 본 논문에서는 unicode character 단위가 아닌 byte 단위로 하는 BPE를 도입하기로 한다. original BERT의 BPE는 vocabulary size가 30K였다면, 새로운 방식은 50K 정도의 큰 vocabulary size가 필요하다. 하지만 기존에는 필수적이던 전처리 과정이 필요없다는 장점을 갖는다. 사실 새로운 BPE는 약간의 성능 하락을 보여주지만, universal한 encoding 방식을 도입했다는 점에서 미미한 정도의 성능 하락을 감안하고서라도 채택해볼 만 하다.
RoBERTa
정리하자면, RoBERTa는 Robustly optimized BERT approach의 약자로, 다음의 4가지 특징을 갖는다.
- dynamic masking 기법
- FULL-SENTENCES
- large mini batches
- byte-level BPE
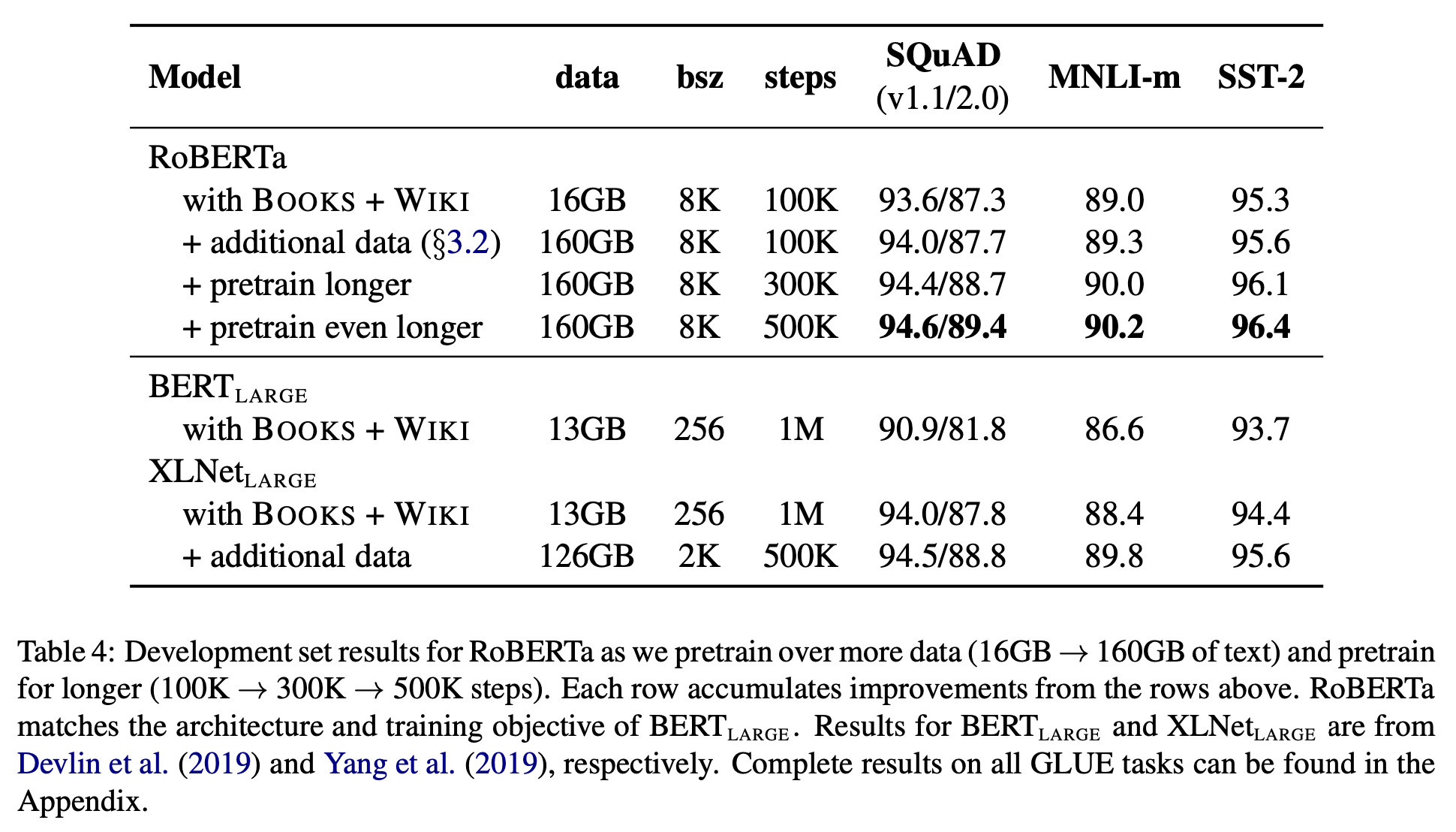
original BERT_LARGE model과 성능을 비교하기 위해서 RoBERTa의 model 크기를 BERT_LARGE와 동일하게 했다. 또한 original BERT에서 사용했던 dataset으로만 pretraining한 경우, 추가적인 dataset으로 pretraining한 경우, pretraining 횟수를 100K에서 300K, 500K로 증가시킨 경우를 비교했다. RoBERTa는 BERT_LARGE나 XLNet_LARGE와 동일한 조건에서도 더 높은 성능을 보였으며, 당연하게도 가장 많은 pretraining을 시킨 경우가 가장 좋은 성능을 보였다.
GLUE Results
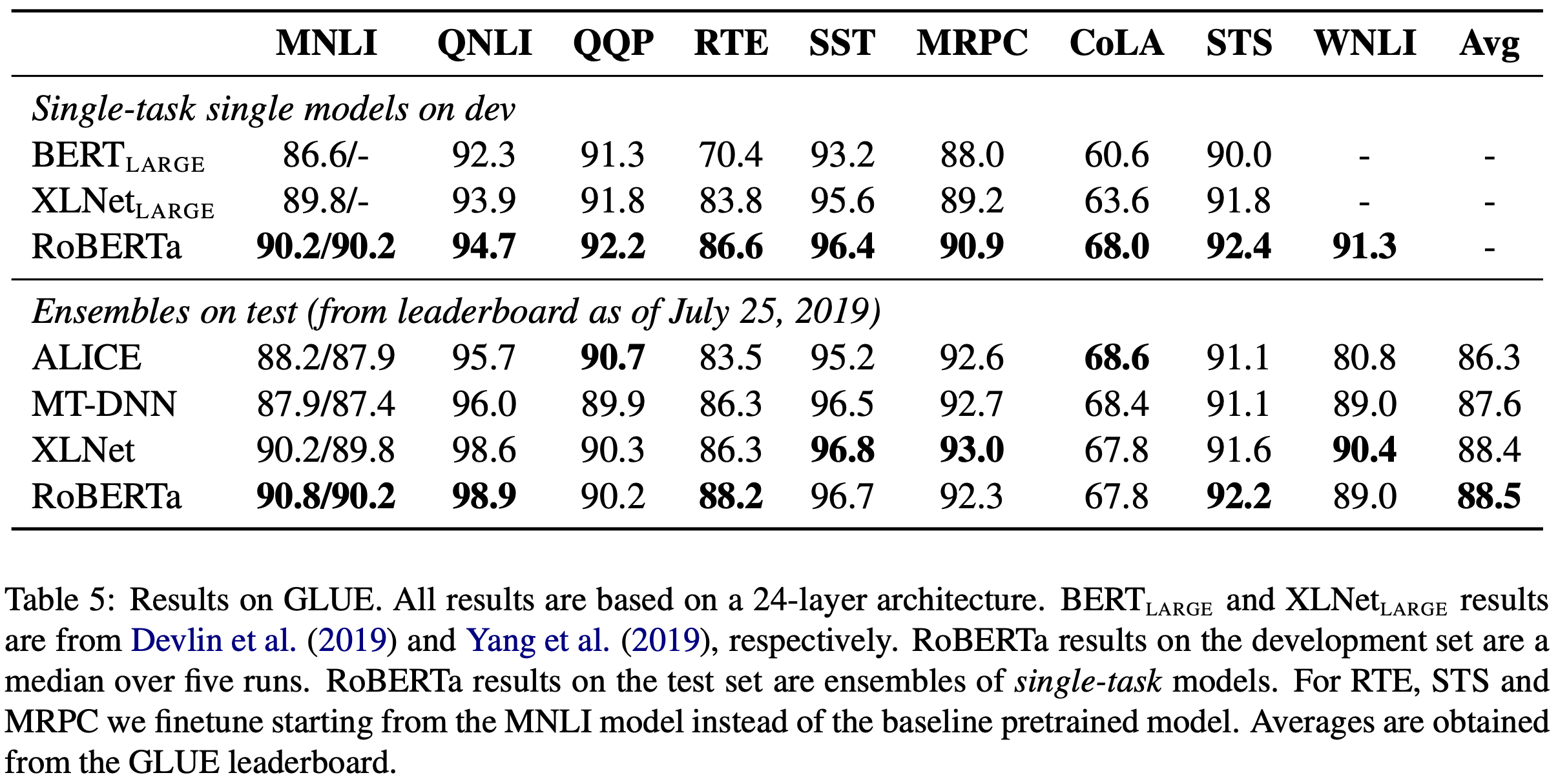
Single-task single models on dev는 GLUE의 각 subtask에 대해 별개로 fine-tuning을 진행한 model들이다.
Ensembles on test는 GLUE leaderboard에 있는 다른 score와 비교한 것이다. 특이하게 RoBERTa는 RTE, SST, MRPC subtask에 대해서 pretrained RoBERTa에서 fine-tuning을 시작하지 않고, MNLI single-task model에서 fine-tuning을 시작했다. 이 경우가 더 좋은 성능을 보였다고 한다.
Single-task, single models에서는 RoBERTa가 9개의 모든 GLUE subtask에서 SOTA를 달성했다. 주목할만한 점은, 여기서의 RoBERTa는 original BERT_LARGE와 동일한 model architecture, 동일한 masking rule(static masking)을 적용했다는 점이다. 이는 굳이 dataset size나 training time을 배제하더라도, training objective(NSP 제거)가 얼마나 큰 영향을 미치는지를 보여준다.
Ensembles on test에서 RoBERTa는 전체 9개 중 4개의 subtask에서 SOTA를 달성했다. 비교 대상인 다른 model들과 달리 RoBERTa는 multi-task fine-tuning을 수행하지 않았다는 점에서 큰 의미가 있다.
SQuAD Results
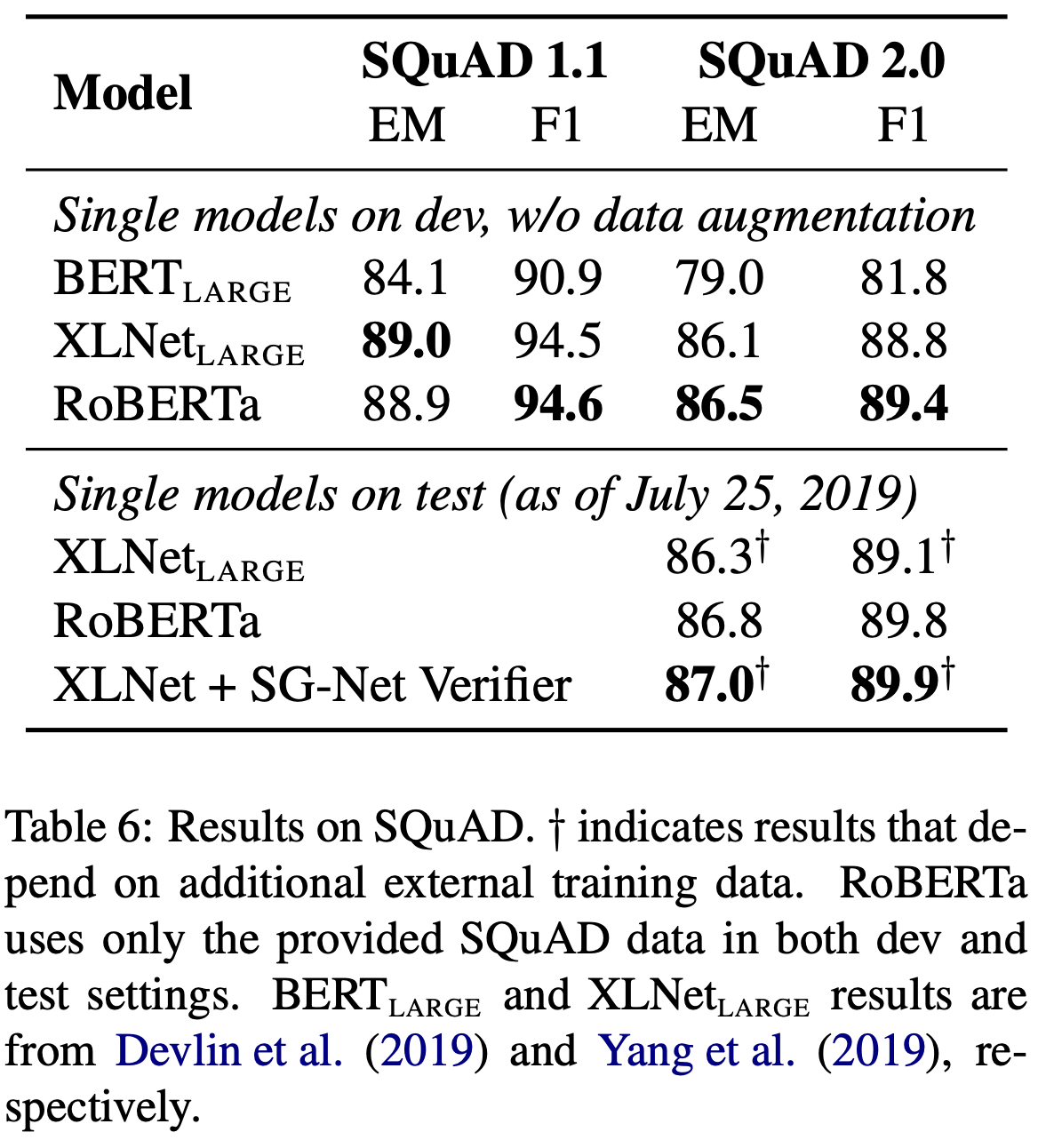
SQuAD 2.0에 대해서는 추가적으로 answerable에 대한 binary classification을 수행하고, 기존의 loss와 더했다. 한편, RoBERTa는 original BERT나 XLNet과 달리 pretraining에서 추가적인 QA dataset을 사용하지 않고, 바로 SQuAD에 대해 fine-tuning을 진행했다. 그럼에도 불구하고 BERT나 XLNet에 비해 더 좋은 성능을 보였다.
RACE Results
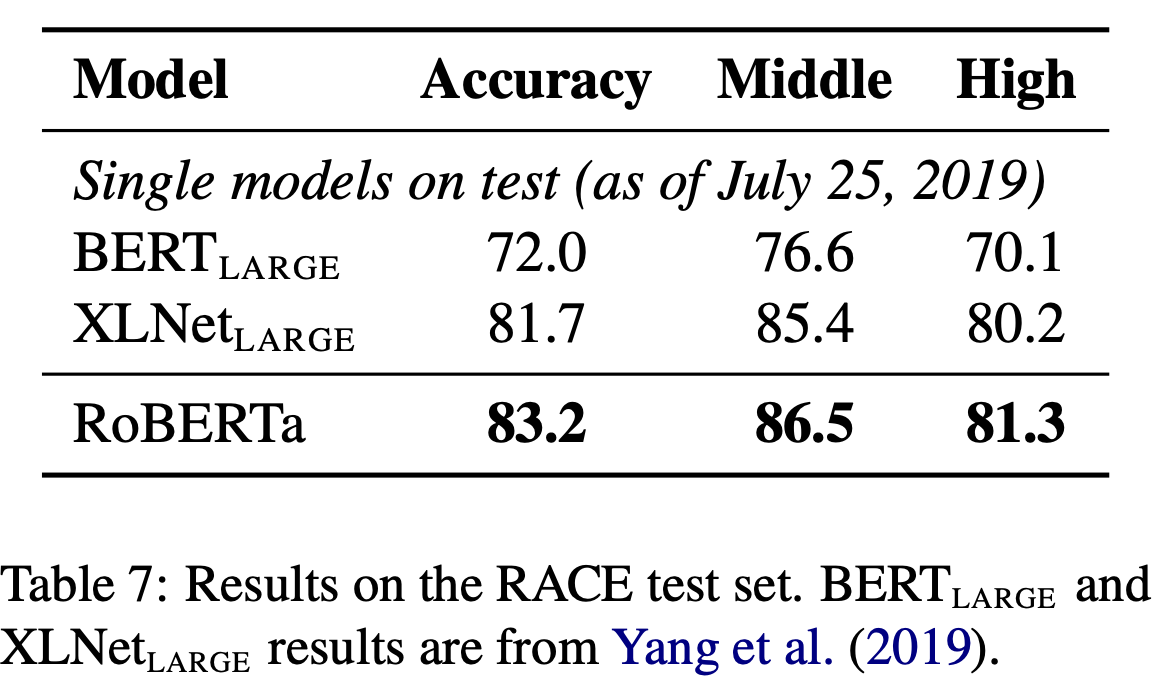
RoBERTa 는 RACE task에서도 Middle school data와 High school data 모두에서 BERT_LARGE나 XLNET_LARGE 대비 더 좋은 성능을 보였다.
Conclusion
BERT model의 성능을 향상시키는 여러 방법을 제시했다.
- 더 많은 횟수, 더 큰 batch size, 더 많은 data로 pretraining
- NSP 제거
- longer sequences로 pretraining
- dynamic masking
- byte 기반 BPE
이를 종합한 RoBERTa는 GLUE, SQuAD, RACE에서 SOTA를 달성했다.