Paper Info
Submit Date: Jul 1, 2018
Abstract
지금까지의 word representation에 관한 연구는 모두 영어에 집중되어 왔다. language-specific knowledge는 언어 학습에 있어서 매우 결정적인 요소인데 영어와 기원이 다른 여러 다양한 언어들에 대해서는 이러한 연구가 부진했던 것이 사실이다. 본 논문에서는 한국어만의 unique한 언어 구조를 분석해 NLP에 적용해보고자 했다. 구체적으로, Korean에만 존재하는 ‘jamo’ 개념을 도입해 character level에서 더 깊이 들어간 ‘jamo’ 단위로 단어를 분해해 사용했다. 동시에 여러 task에 대해 측정 가능한 한국어 test set도 제안했다. 본 논문에서 제안하는 방식은 word2vec이나 character-level Skip-Grams을 semantic, syntatic 모두에서 능가했다.
Introduction
기존의 word representation은 모두 영어 위주였기 때문에 다양한 형태를 가진 한국어에 대해서는 제대로 적용할 수 없었다. 단어를 n-gram set으로 분해하는 방식은 여러 language에서 효과적이긴 했으나 해당 언어만의 unique한 linguistic structure를 무시한다는 단점이 있었다. 이를 해결하기 위해 word vector를 학습하는 과정에서부터 language-specific한 구조를 활용하고자 하는 연구는 활발히 진행되어 왔다. 한국어의 경우 character-level로 단어를 분해하는 연구는 있어왔으나 한국어의 character는 자음과 모음으로 분해가 가능하다는 점에서 다소 부족한 부분이 있었다. 본 논문에서는 ‘jamo’ 단위로까지 분해해 word를 subword로 분해하는 방식을 제안하고, 한국어 원어민들에게서 얻어낸 정확도 높은 한국어 test dataset을 제안하고자 한다.
Related Work
Language-specific features for NLP
다양한 언어들의 각각의 고유한 특징은 여러 언어들에 대한 universal model을 개발하는데 큰 장애물이다. universal model은 한국어와 같은 교착어(어근+접사의 결합으로 구성되는 언어)에서는 특히나 좋은 성능을 내지 못했다. 언어 자체의 고유한 구조가 문법과 강력하게 연결되어 있기 때문이다. 한국어에 관련된 기존의 NLP 연구들은 교착어로써의 특성을 반영하고자 노력해왔다. word embedding 이후 ‘Josa’에 대해 특별한 labeling을 부여하거나, ‘jamo’ 단위로 word를 분해해 형태소의 변형을 찾아내려는 시도가 있었다.
Subword features for NLP
character-level의 subword features 방식은 여러 NLP task에서 성능 향상에 많은 기여를 했다. 특히나 character n-gram model은 sparsity 문제에서 상대적으로 자유롭기 때문에 작은 dataset에서 좋은 성능을 보였다.
Model
우선 word를 ‘jamo’ 단위로 word를 분해한 뒤, 얻은 ‘jamo’ sequence에서 n-gram을 사용해 word vector를 생성하는 방식을 제안한다.
Decomposition of Korean Words
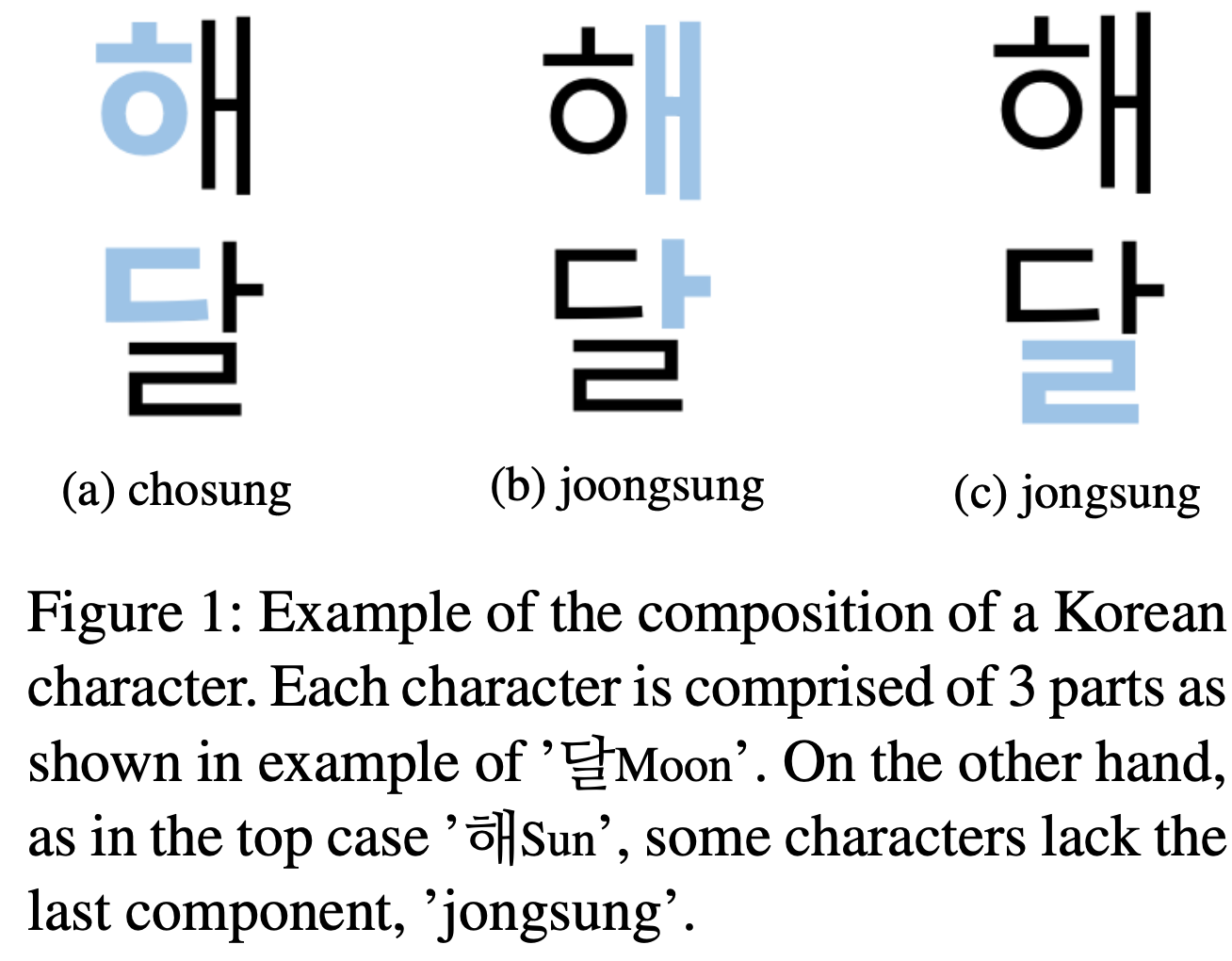
우선 한국어 word를 ‘jamo’ 단위로 분해하는 것에 대해서 살펴보자. 영어와는 달리 한국어는 자음과 모음의 규칙이 엄격하다. (영어의 straight을 생각해보자. 모음 a 뒤에 모음 i가 연속해서 등장한다.) 한국어의 character는 영어의 음절과 비슷한 개념이며, 이는 3개의 ‘jamo’ {1. 초성(‘chosung’):자음, 2. 중성(‘joongsung’):모음, 3. 종성( ‘jongsung’):자음}로 구성된다. ‘joongsung’에 대해서는 예외적으로 없을 수도 있는데, 이 때에는 새로운 symbol \(e\)를 사용했다. 아래는 한국어 ‘해’와 ‘달’에 대한 예시이다.
\['해'=\{ㅎ,ㅐ,e\},\ '달'=\{ㄷ,ㅏ,ㄹ\}\]이러한 representation을 이용하면 \(N\)개의 한국어 character는 \(3 * N\)개의 ‘jamo’로 구성된다고 보장 가능하다. word에 대해서도 시작과 끝에 symbol \(\lt\)와 \(\gt\)를 추가했다. 따라서 아래는 한국어 ‘강아지’에 대한 예시이다.
\['강아지'=\{\lt,ㄱ,ㅏ,ㅇ,ㅇ,ㅏ,e,ㅈ,ㅣ,e,\gt\}\]Extracting N-grams from jamo Sequence
Character-level n-grams
한국어의 ‘먹었다’ 라는 word를 예시로 n-gram을 추출해보자. 우선 character-level에서는 다음과 같은 3개의 unigram을 얻을 수 있다.
\[\{ㅁ,ㅓ,ㄱ\},\{ㅇ,ㅓ,ㅆ\},\{ㄷ,ㅏ,e\}\]2개의 bigram을 얻을 수 있다.
\[\{ㅁ,ㅓ,ㄱ,ㅇ,ㅓ,ㅆ\},\{ㅇ,ㅓ,ㅆ,ㄷ,ㅏ,e\}\]1개의 trigram을 얻을 수 있다.
\[\{ㅁ,ㅓ,ㄱ,ㅇ,ㅓ,ㅆ,ㄷ,ㅏ,e\}\]Inter-character jamo-level n-grams
한국어의 character는 character마다 독립적이지 않고, 이전 character의 영향을 강하게 받는다. 대표적인 예로 조사 ‘이’, ‘가’를 들 수 있다. 두 조사는 semantic에서는 완전히 동일하지만, 직전 character가 종성이 있을 경우 ‘이’를, 종성이 없을 경우 ‘가’를 사용해야만 한다. 이러한 제약을 반영하기 위해 ‘jamo’-level의 n-gram은 인접한 character들까지 통합하도록 했다. 이러한 방식을 통해 다음과 같은 ‘jamo’-level trigram을 얻을 수 있다.
\[\{\lt,ㅁ,ㅓ\},\{ㅓ,ㄱ,ㅇ\},\{ㄱ,ㅇ,ㅓ\},\{ㅆ,ㄷ,ㅏ\},\{ㅓ,ㅆ,ㄷ\},\{ㅏ,e,\gt\}\]Subword Information Skip-Gram
Experiments
Corpus
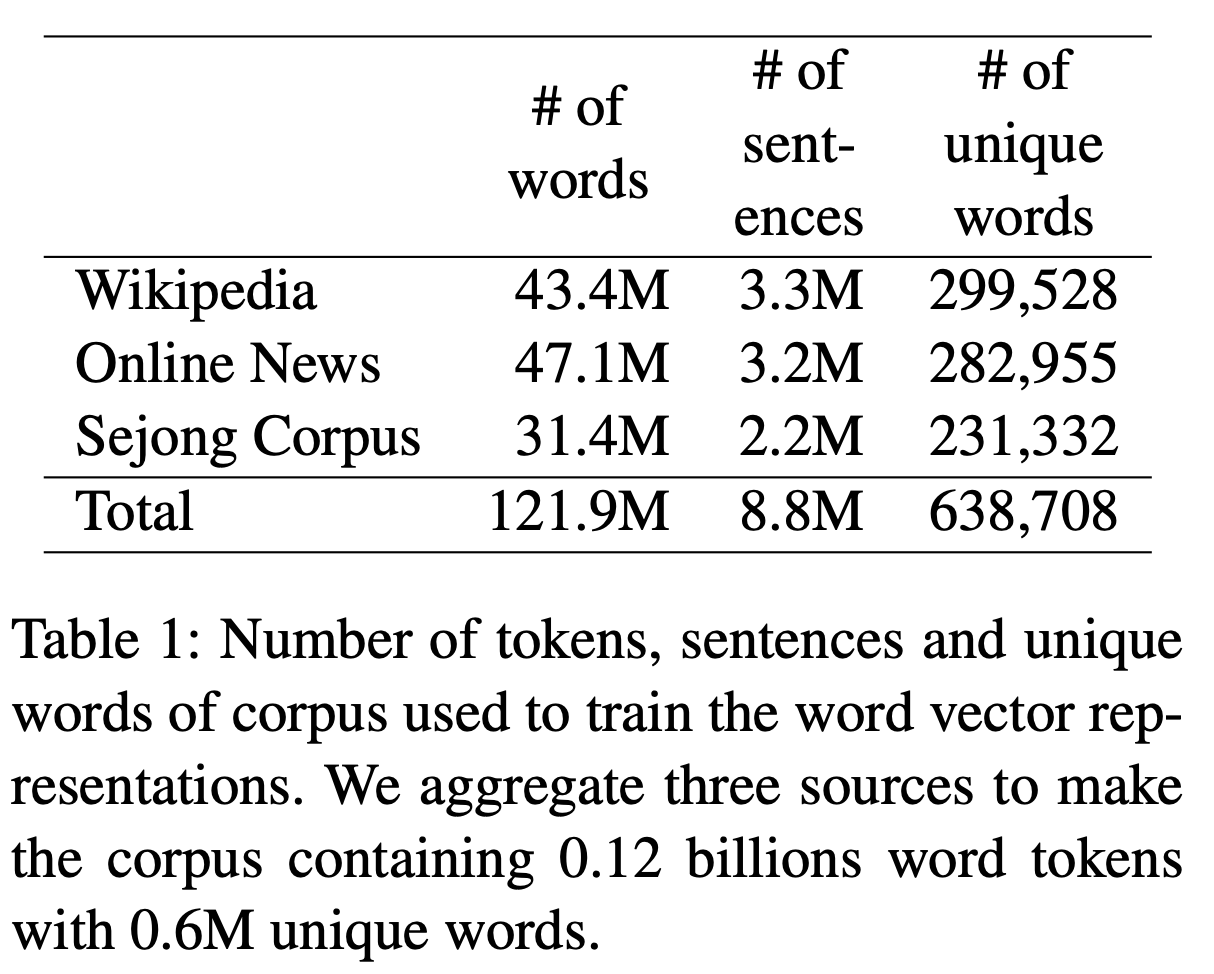
한국어 Wikipedia, 뉴스 기사, Sejong Corpus에서 corpus를 수집했다. 0.12 billion개의 token과 638,708개의 unique words를 얻었는데, 이 중 10번 미만 등장한 corpus는 제외했다.
Korean Wikipedia
0.4million개의 기사에서 3.3million개의 sentence와 43.4million개의 word를 얻었다.
Online News Articles
5개의 major 신문사의 사회, 정치, 경제, 국제, 문화, IT의 6가지 분야에서 기사를 수집했다. 2017년 9월~11월의 기사들을 사용했다. 3.2million개의 sentence와 47.1million개의 word를 얻었다.
Sejong Corpus
Sejong Corpus는 1998년~2007년 사이의 뉴스 기사, 사전, 소설 등의 formal text와 TV, 라디오의 대본 등의 informal text에서 추출한 corpus이다. Wikipedia나 New Article에서 얻을 수 없는 corpus를 얻어낼 수 있었다.
Evaluation Tasks and Datasets
similarity task와 analogy task를 통해 word vector의 성능을 측정하고자 했다. 하지만 각각의 task에 대한 한국어 evaluation dataset이 존재하지 않아 evaluation dataset을 개발해 사용했다. 동시에 감정 분석 downstream task를 진행했다.
Word Similarity Evaluation Dataset
한국어를 모국어로 사용하는 학생 두 명이 353개의 영어 단어 쌍을 번역한다. 353개의 한국어 단어쌍이 생성된다. 이후 다른 14명의 한국인이 한국어 단어 쌍에 대해 0~10 사이의 유사도 점수를 매긴다. 각 단어 쌍에 매겨진 점수 중에서 최대, 최소 점수를 제외하고 평균을 매긴다. 영어 단어 쌍과 한국어 단어 쌍 사이의 상관계수는 0.82로 매우 유사했다.
Word Analogy Evaluation Dataset
- Semantic 차원
-
수도-국가 (Captial-Country)
ex) 아테네 : 그리스 = 바그다드 : 이라크
-
남성-여성 (Male-Female)
ex) 왕자 : 공주 = 신사 : 숙녀
-
이름-국적 (Name-Nationality)
ex) 간디 : 인도 = 링컨 : 미국
-
국가-언어 (Country-Language)
ex) 아르헨티나 : 스페인어 = 미국어 : 영어
-
기타 (Miscellaneous)
ex) 개구리 : 욜챙이 = 말 : 망아지
-
- Syntactic 차원
-
격 (case)
ex) 교수 : 교수가 = 축구 : 축구가
-
시제 (tense)
ex) 싸우다 : 싸웠다 = 오다 : 왔다
-
태 (voice)
ex) 팔았다 : 팔렸다 = 평가했다 : 평가됐다
-
동사 변형 (verb form)
ex) 가다 : 가고 = 쓰다 : 쓰고
-
높임법 (honorific)
ex) 도왔다 : 도우셨다 = 됐다 : 되셨다
-
Sentiment Analysis
네이버 영화 감정 분석 dataset을 사용했다. Classifier로 300개의 hidden layer, dropout=0.5의 LSTM을 사용했다.
Comparison Models
모든 model의 training epoch=5, #negative samples=5, window size=5, #dimension=300으로 동일하다.
-
Skip-Gram (SG)
word-level Skip Gram이다. 모든 unique word에 대해서 unique vector가 부여됐다.
-
Character-level Skip-Gram (SISG(ch))
character-level n-gram이다. n=2-4이다.
-
Jamo-level Skip-Gram with Empty Jongsung Symbol (SISG(jm))
‘jamo’-level의 n-gram이다. 비어 있는 종성 symbol \(e\)를 추가했다. n=3-6이다.
Results
Word Similarity
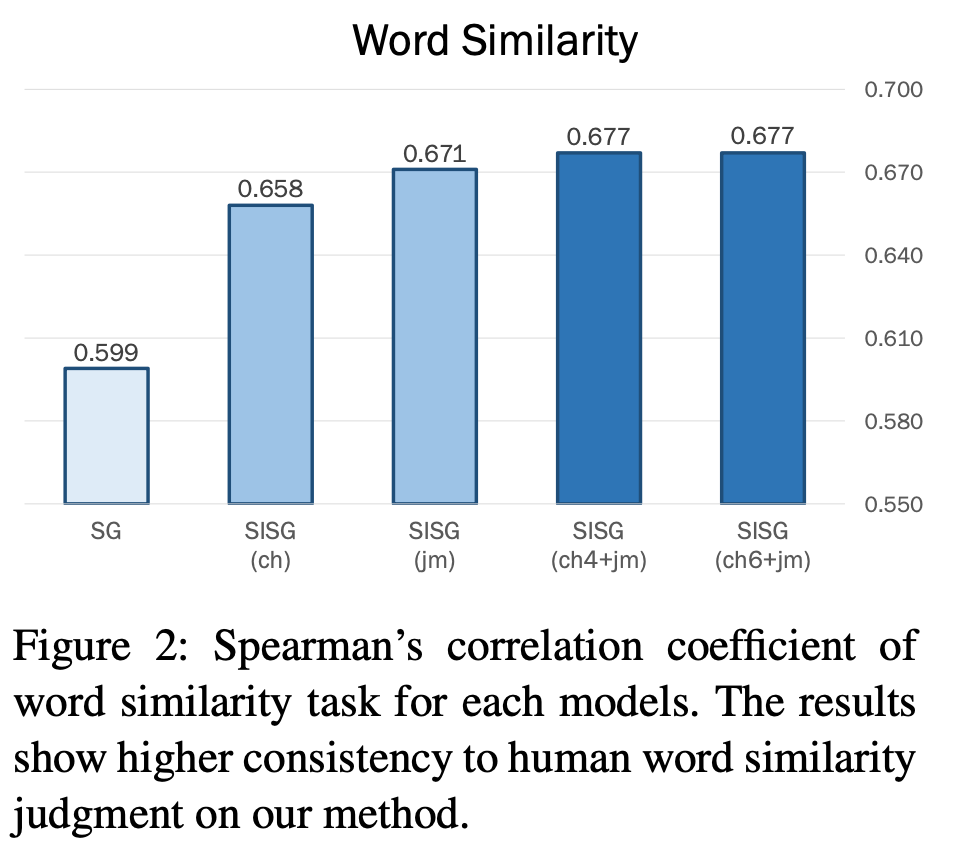
단어 유사성에 대해 인간의 판단과 model의 cosine 유사도에 대해서 스피어만 상관 계수를 분석한다. word-level skip-gram인 SG보다 character n-gram을 적용한 SISG가 훨씬 더 좋은 성능을 보였다. ‘jamo’-level로 더 깊게 분해한 model이 가장 좋은 성능을 보였다.
Word Analogy
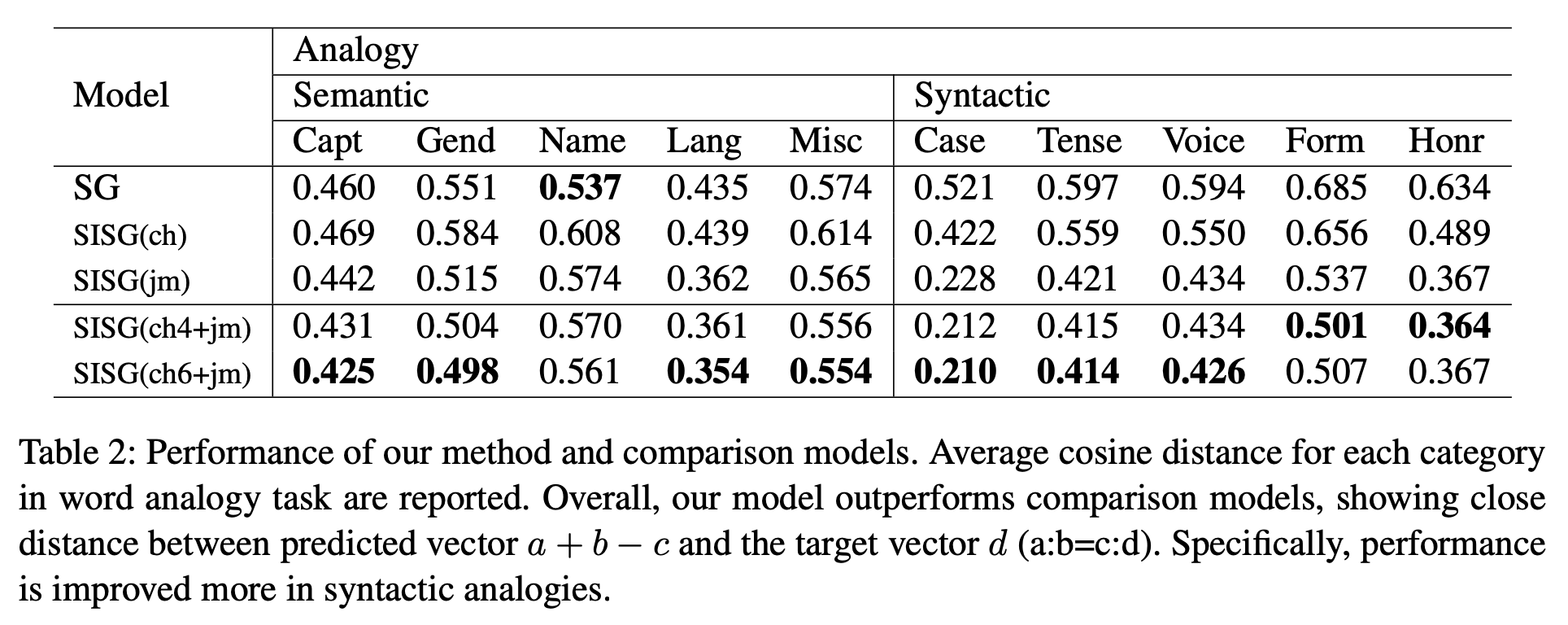
a:b=c:d의 4개의 단어가 주어진다. 왕:왕비 = 남자:여자 와 같은 형태이다. 여기서 a + b - c와 d 사이의 cosine 유사도를 구한다.
Sentiment Analysis
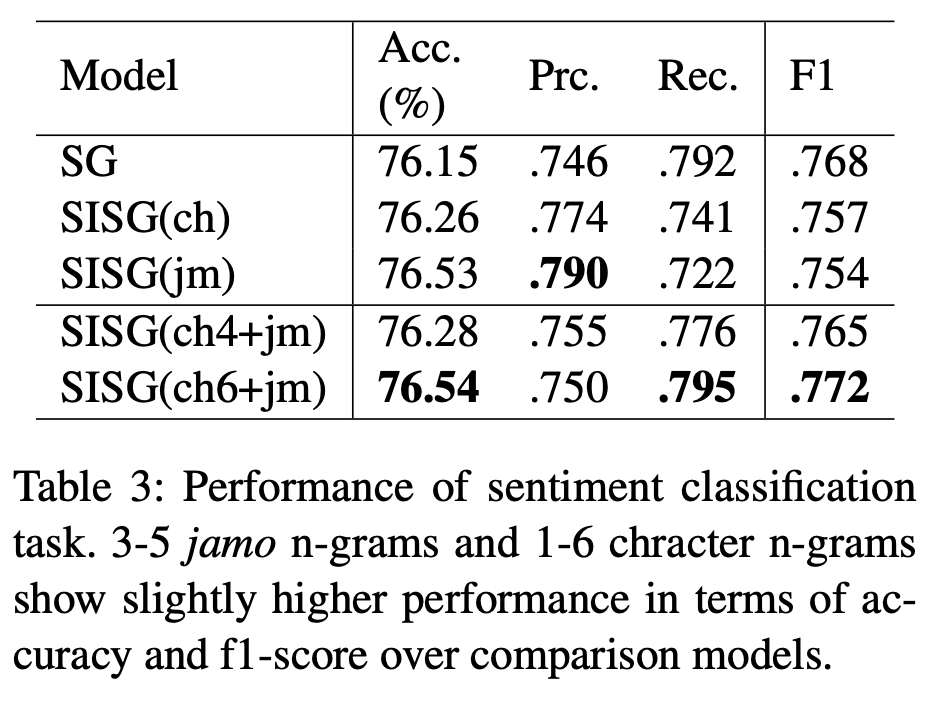
word-level skip-gram보다 character-level, ‘jamo’-level이 더 좋은 성능을 보였다. 하지만 word-level은 F1 Score에서 본 논문에서 제시한 model보다는 낮지만, character-level, ‘jamo’-level보다 더 좋은 수치를 보였다. 이는 영화 리뷰라는 dataset의 특성 상 고유 명사가 많이 등장하는데, word-level이 고유 명사를 더 잘 잡아내기 때문으로 추측할 수 있다.
Effect of Size n in both n-grams
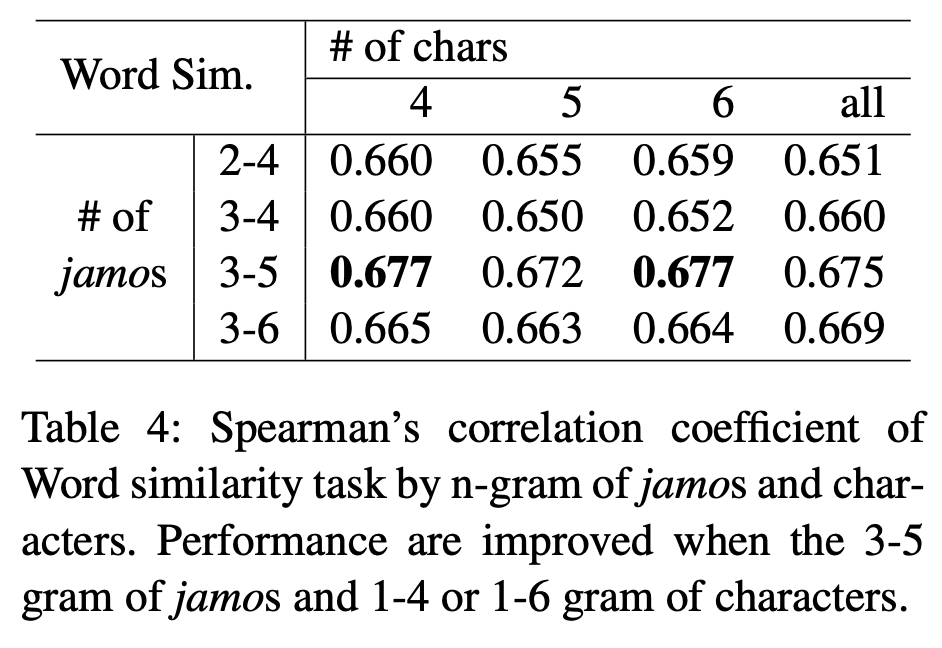
‘jamo’-level에서의 n은 증가할수록 대체로 더 좋은 성능을 보여주지만, character-level에서의 n은 그렇지 않다. 이는 한국어의 특성에서 기인하는데, 대부분의 한국어 word는 6자 이하(97.2%)이기 때문에, n=6은 과도하게 큰 값이다. 4자 이하의 word는 전체 한국어 word의 82.6%를 차지하기 때문에 n=4로도 충분하다고 볼 수 있다.
Conclusion and Discussions
한국어 character를 어떻게 ‘jamo’-level로 분해하는지에 대한 방법론을 제시했다는 점에서 의의가 있다. 특히 비어있는 종성 symbol \(e\)를 추가해 일반화된 표현을 가능하게 했다는 점, inter-character하게 ‘jamo’-level로 분해하는지에 대해서 새로운 방식을 제안했다. 또한 word 단위에서 similarity, analogy 측정을 위한 dataset을 개발했다. sentiment classification task를 통해 word vector 학습이 downstream NLP task에도 큰 영향을 미친다는 점도 알 수 있다.
한국어를 ‘jamo’-level로 분해하는 방식은 syntatic, semantic의 양 측면에 있어서 모두 긍정적이다. inter-character ‘jamo’-level로 분해해 각종 조사 및 어미에 대해서 syntatic한 feature를 잡아낼 수 있었다. (주어 뒤의 조사 ~은, 동사 뒤의 조사 ~고~, 과거 시제 ~었, 경어체 ~시~ 등) 심지어 더 같은 의미의 더 짧은 character로 축약도 가능했다. (되었다 → 됐다) character level n-gram은 word의 semantic한 feature를 잡아낼 수 있도록 했다. 이러한 방식 덕분에 기존의 word vector보다 더 좋은 성능을 보일 수 있었다.