Paper Info
Submit Date: Jun 19, 2019
Introduction
Unsupervised Learning을 pretraining에 적용시키는 방식은 NLP domain에서 매우 큰 성과를 이뤄냈다. Unsupervised pretraining하는 방법론은 크게 AutoRegressive(AR)과 AutoEncoding(AE)가 있다. AutoRegressive는 순방향 또는 역방향으로 다음의 corpus를 예측하는 방식으로 학습한다. 이는 단방향 context만 학습할 수 있다는 단점이 있다. 하지만 현실의 대부분의 downstream task는 bidirectional context가 필수적이기에 이는 크나큰 한계가 된다.
반면 AutoEncoding은 변형된 input을 다시 본래의 input으로 재구성하는 방식이다. BERT가 대표적인 예시인데, input data의 일부분을 [MASK] token 등으로 변화를 준 뒤, 원래의 input을 만들어내도록 학습시킨다. 이러한 방법은 bidirectional context를 학습할 수 있다는 점에서 AutoRegressive에 비해 상대적으로 좋은 성능을 보인다.하지만 인위적인 변형을 가해 만들어낸 [MASK] token 등은 pretraining 과정에서만 존재하는 token이고, 이후 downstream task를 학습시키는 fine-tuning 과정에서는 존재하지 않는 token이 된다. 따라서 pre-training과 fine-tuning 사이의 괴리가 발생하게 된다. 또한 각 [MASK] token을 predict하는 과정은 independent하기 때문에 predict된 token들 사이의 dependency는 학습할 수 없다는 한계도 있다.
본 논문에서 제시하는 XLNet은 이러한 AR과 AE을 모두 사용해 각각의 장점만을 취하도록 했다.
Proposed Method
Background
AR (Autoregressive)
일반적인 AR의 objective function은 다음과 같다.
\[\underset{\theta}{max}\ \ log{\ p_\theta(x)} = \sum_{t=1}^Tlog{\ p_\theta\left(x_t|x_{<t}\right)} = \sum_{t=1}^Tlog{\ \frac{exp\left(h_\theta\left(x_{1:t-1}\right)^Te\left(x_t\right)\right)}{\sum_{x'}{exp\left(h_\theta\left(x_{1:t-1}\right)^Te\left(x'\right)\right)}}}\]\(h_\theta\left(x_{1:t-1}\right)\)는 model의 context representation이고, \(e\left(x'\right)\)는 x의 embedding이다.
AE (Autoencoding)
일반적인 AE의 objective function은 다음과 같다.
\[\underset\theta{max}\ log{\ p_\theta\left(\bar{x}|\hat{x}\right)} \approx \sum_{t=1}^T{m_tlog{\ p_\theta\left(x_t|\hat{x}\right)}} = \sum_{t=1}^T{m_tlog{\ \frac{exp\left(H_\theta\left(\hat{x}\right)_t^Te\left(x_t\right)\right)}{\sum_{x'}{exp\left(H_\theta\left(\hat{x}\right)_t^Te\left(x'\right)\right)}}}}\]\(\hat{x}\)는 [MASK] token 등이 추가된 변형된 input이고, \(\bar{x}\)는 masked token이다.
\(m_t=1\)인 경우 \(x_t\)가 masked된 경우를 뜻하고, \(H_\theta\)는 Transformer의 hidden vector를 뜻한다.
XLNet
XLNet은 AR와 AE를 아래의 3가지 관점에서 비교하며 각각의 장점만 취한다.
-
Independence Assumption
AE의 objective function은 조건부확률을 계산하는 것이다. 이 때 \(\approx\)를 사용한다. 이는 모든 \(\bar{x}\)에 대한 reconstruction이 independent하게 이루어진다는 가정 하에 이루어지기 때문이다. 반면 AR의 objective function은 이러한 가정 없이도 성립하기에 \(=\)를 사용한다.
-
Input Noise
AE에서는 [MASK] token과 같이 실제 input에 없던 token들이 추가되게 된다. 이는 pretraining 때에만 존재하는 token으로 fine-tuning 과정에서는 존재하지 않는다. 이러한 pretraining과 fine-tuning 사이의 괴리를 해결하기 위해 BERT에서는 masking에 대해 모두 [MASK] token으로 변경하지 않고 일부분은 original token 그대로 두는 등의 기법을 사용했으나, 이는 전체 token에서 극히 일부분에만 적용되기 때문에 (0.15 * 0.1 == 0.015) 의미있는 결과를 도출해내지 못한다. AR에서는 input에 대한 변경이 없기 때문에 이러한 문제가 발생하지 않는다.
-
Context Dependency
AE는 bidirectional context를 모두 학습할 수 있지만, AR은 unidirectional context만 학습한다.
Objective: Permutation Language Modeling
AR의 장점은 모두 취하면서(no Indepence Assumption, no Input Noise) AR의 단점은 해결하는(Bidirectional Context) Objective function을 정의하기로 한다.
\[\underset{\theta}{max} = E_{z\thicksim Z_T}\left[\sum_{t=1}^T{log{\ p_\theta\left(x_{z_t}|x_{z_{<t}}\right)}}\right]\]\(Z_T\)는 길이가 \(T\)인 sequence의 모든 순열 집합 을 뜻하고, \(z_t\)는 \(Z_T\)에서 \(t\)번째 element를 뜻한다. \(z_{<t}\)는 \(Z_T\)에서 \(0\) ~ \(t-1\)번째 원소들을 뜻한다.
위의 Objective Function은 \(x_i\)에 대해 \(x_i\)를 제외한 모든 \(x_t\)를 전체 집합으로 하는 순열에 대해 likelihood를 구하게 된다. AR의 구조를 채택했으나 순열을 사용해 bidirectional context까지 학습하도록 한 것이다.
Architecture: Two-Stream Self-Attention for Target-Aware Representations
일반적인 Transformer의 Self-Attention 구조에서는 Query, Key, Value가 모두 같은 값으로 시작하게 된다. 즉, 하나의 hidden state의 값을 공유한다. 그러나 XLNet에서는 구조상 Query의 값과 Key, Value의 값이 분리되어야 한다. 이를 위해 새로운 representation을 추가하게 된다.
구체적인 예시를 들어보자. \(T = 4\)일 때, 두가지의 순열이 선택되었다고 하자.
\[Z_1 = [x_2,x_3,x_1,x_4]\] \[Z_2 = [x_2,x_3,x_4,x_1]\]\(Z_1\)에서 \(t=3\)에 대한 조건부 확률을 구하는 식은 다음과 같다.
\[p\left(x_1|x_{z_{<3}}\right) =p\left(x_1|x_2,x_3\right)=\frac{exp\left(e\left(x_1\right)^Th_\theta\left(x_2,x_3\right)\right)}{\sum_{x'}{exp\left(e\left(x'\right)^Th_\theta\left(x_2,x_3\right)\right)}}\]\(Z_2\)에서 \(t=3\)에 대한 조건부 확률을 구하는 식은 다음과 같다.
\[p\left(x_4|x_{z_{<3}}\right) =p\left(x_4|x_2,x_3\right)=\frac{exp\left(e\left(x_4\right)^Th_\theta\left(x_2,x_3\right)\right)}{\sum_{x'}{exp\left(e\left(x'\right)^Th_\theta\left(x_2,x_3\right)\right)}}\]위의 두 조건부확률 식은 분모는 완전히 같은 값이다. 만약 \(x_1\)과 \(x_4\)가 같은 word였다고 한다면 (a, an, the와 같은 관사 등) 완전히 같은 조건부 확률을 계산하는 상황이 발생하게 된다. 직전 시점 \(t-1\)까지의 정보 embedding 정보만을 저장하는 representation \(h_\theta\left(x_{z_{<t}}\right)\)만으로는 이러한 문제를 해결할 수 없다. 따라서 현재 시점의 위치정보 까지 받는 새로운 representation \(g_\theta\left(x_{z_{<t}},z_t\right)\)을 추가한다. 최종적으로 아래의 수식을 정의하게 된다.
\[p\left(X_{z_t}=x|x_{z_{<t}}\right) =\frac{exp\left(e\left(x\right)^Tg_\theta\left(x_{z<t},z_t\right)\right)}{\sum_{x'}{exp\left(e\left(x'\right)^Tg_\theta\left(x_{z<t},z_t\right)\right)}}\]두 representation에 대해 자세히 알아보자.
Content Representation
\(h_\theta\left(x_{z<t}\right)\)는 기존 Transformer의 hidden state와 동일한 구조이다. 현재 시점(\(t\))의 정보까지 포함해 입력으로 받는다. 이를 Content Representation이라고 하고, Key, Value에 사용하게 된다.
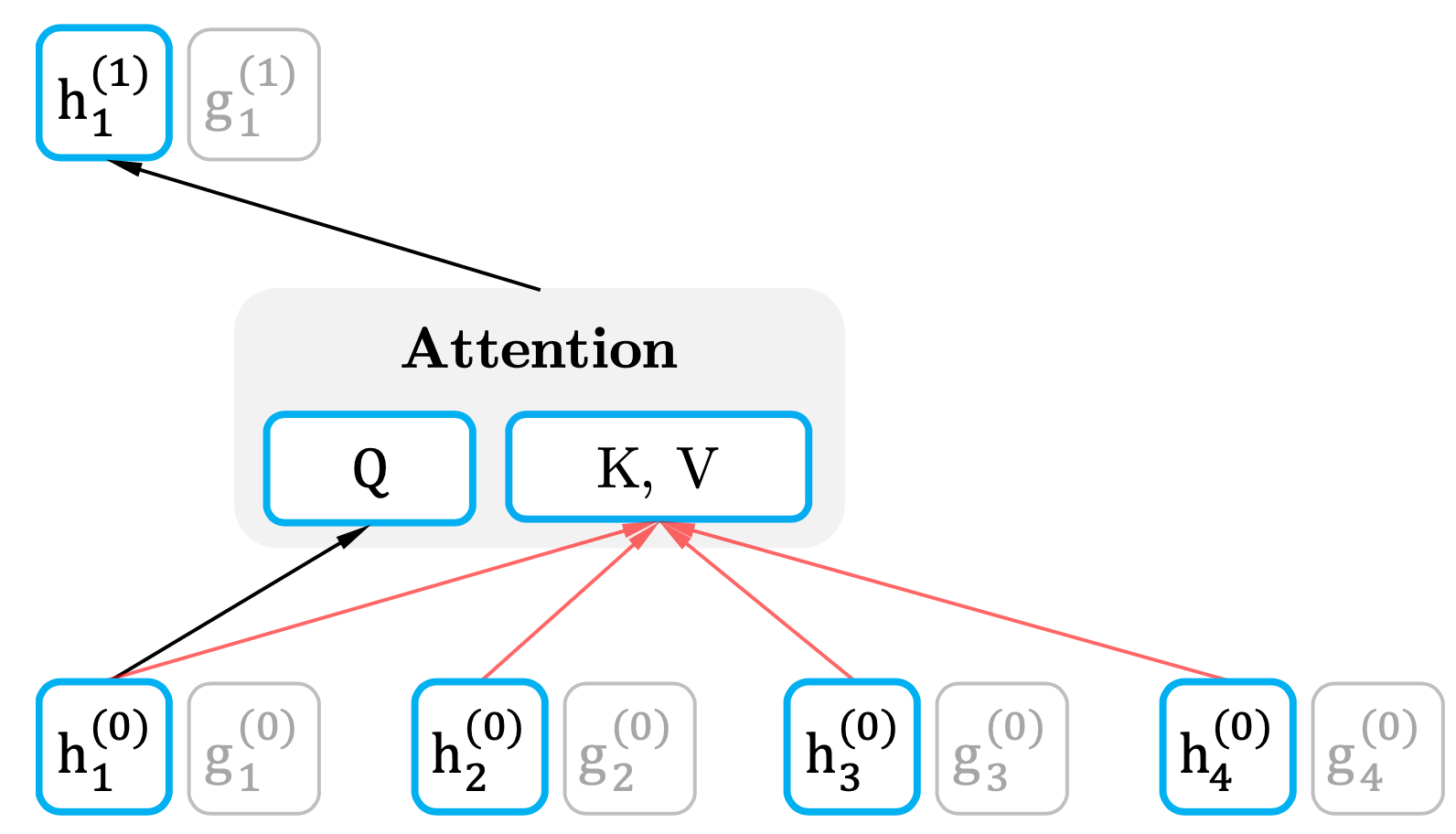
Query Representation
\(g_\theta\left(x_{z_{<t}},z_t\right)\)는 현재 시점(\(t\))의 정보는 제외하고 입력으로 받는다. 대신 현재 시점(\(t\))의 위치 정보(\(z_t\))는 입력으로 받는다. 이를 Query Representation이라고 하고, Query에 사용하게 된다.
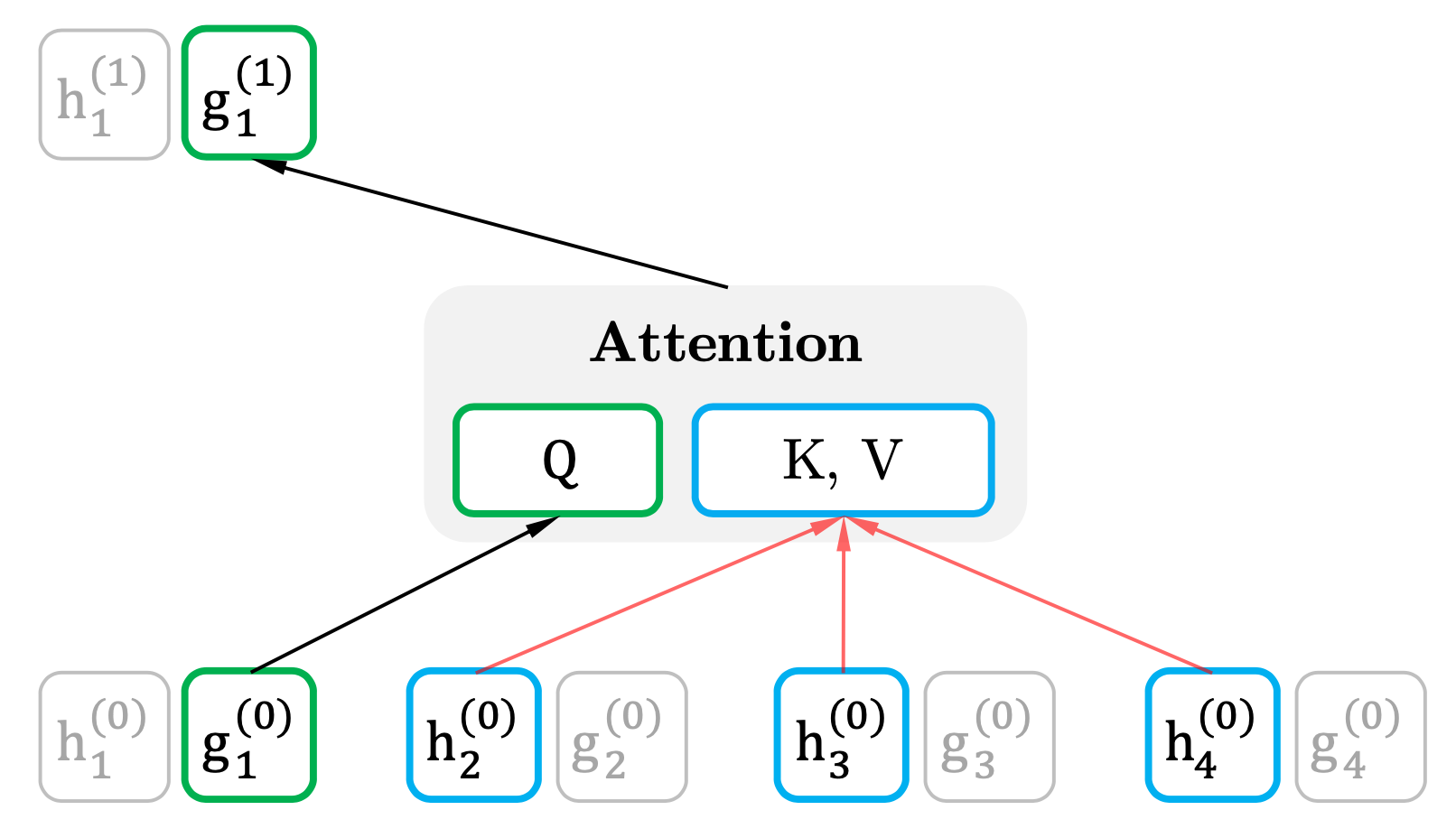
Permutation Language Modeling with Two-Stream Attention
전체적인 Two-Stream Attention의 구조는 아래와 같다.
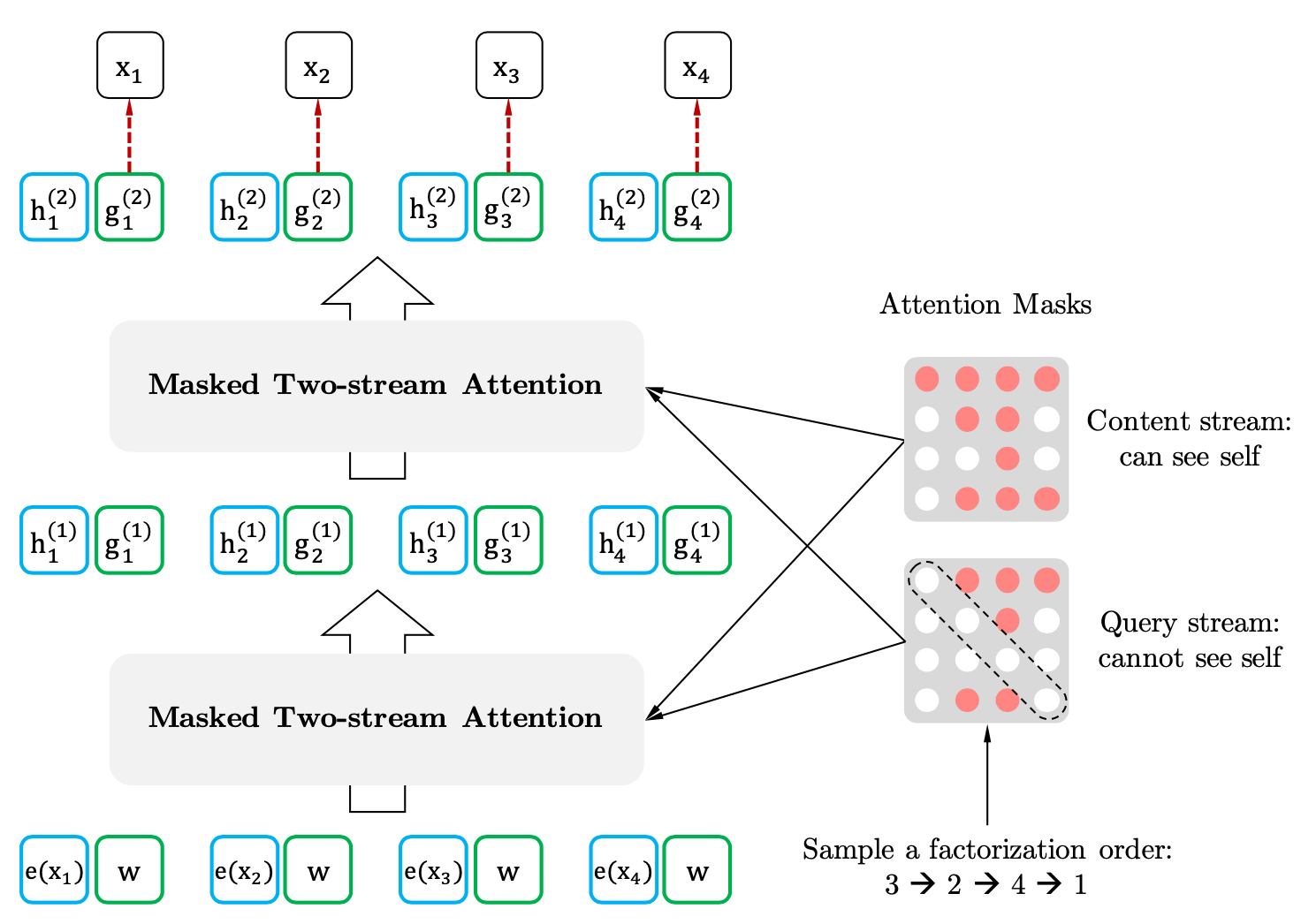
Query의 초기값은 weight \(w\), Key와 Value의 초기 값은 embedding된 input 값 \(e\left(x_i\right)\)이다. 이후 아래와 같이 갱신된다.
Query Stream은 현재 시점 \(t\)의 위치 정보(\(z_t\))는 알 수 있지만, 실제 값(\(x_{z_t}\))는 알지 못하는 상태로 구해진다.
Content Stream은 현재 시점 \(t\)의 위치 정보(\(z_t\))는 물론, 실제 값(\(x_{z_t}\))도 사용해 구해진다.
\[g_{z_t}^{\left(m\right)} = Attention\left(Q=g_t^{\left(m-1\right)},KV=h_{z_{<t}}^{\left(m-1\right)};\theta\right)\] \[h_{z_t}^{\left(m\right)}=Attention\left(Q=h_{z_t}^{\left(m-1\right)},KV=h_{z_{z\leq t}}^{\left(m-1\right)};\theta\right)\]\(m\)은 Multi-head Atention Layer의 현재 Layer Number이다.
Incorporating Ideas from Transformer-XL
Modeling Multiple Segments
BERT의 input과 동일한 구조를 채택했다. [CLS, A, SEP, B, SEP]의 구조이다. [CLS], [SEP] token은 BERT와 동일한 역할이고, [A], [B]는 각각 sentence A, sentence B이다. BERT와의 차이점은 NSP (Next Sentence Predict)를 Pretraining에 적용하지 않은 것인데, 유의미한 성능 향상이 없었기 때문이라고 한다.
Relative Segment Encodings
BERT의 segment embedding은 \(S_A\)와 \(S_B\) 등으로 \(A\)문장인지, \(B\)문장인지를 드러냈다. XLNet에서는 Transformer-XL의 relative positional encoding의 idea를 segment에도 적용해 relative한 값으로 표현했다. XLNet의 Segment Encoding은 두 position \(i, j\)가 같은 segment라면 \(s_+\), 다른 segment라면 \(s_-\)로 정의된다. \(s_+\)와 \(s_-\)는 모두 training 과정에서 학습되는 parameters이다. 이러한 relative segment encoding은 재귀적으로 segment encoding을 찾아내면서 generalization된 표현이 가능하다는 점, 두 개 이상의 segment input에 대한 처리 가능성을 열었다는 점에서 의의가 있다.
Discussion
구체적인 예시를 들어 BERT와 비교해보자. BERT와 XLNet이 “New York is a city.”라는 문장을 pretraining하는 상황이다. [New, York]의 두 token을 predict하는 것이 목표이다. BERT의 objective는 다음의 수식이다.
\[J_{BERT}=log{\ p\left(New\ |\ is\ a\ city\right)} + log{\ p\left(York\ |\ is\ a\ city\right)}\]XLNet은 순열을 특정해야 objective를 구체화할 수 있다. [is, a, city, New, York]의 순열이라고 가정하자. 다음의 수식이 XLNet의 objective이다.
\[J_{XLNet}=log{\ p\left(New\ |\ is\ a\ city\right)} + log{\ p\left(York\ |\ \textbf{New}\ is\ a\ city\right)}\]XLNet은 AutoRegressive Model이기 때문에 input sentence에 변형을 가하지 않고, 따라서 predict target word 사이의 dependency 역시 학습할 수가 있다. 위의 예시에서는 ‘York’를 predict할 때에 ‘New’ token의 정보를 활용했다.
Experiments
Pretraining and Implementation
Pretraining의 Dataset으로 BooksCorpus, Giga5, CLue Web2012-B, Common Crawl dataset의 Dataset을 사용했다. Google SentencePiece Tokenizer를 사용했다. XLNet-Large는 512 TPU v.3를 사용해 2.5일동안 500K step의 학습을 진행했다. 이 때 Adam Optimizer를 사용했다. Dataset의 크기에 비해 학습량이 적어 Unerfitting된 상태이지만, Pretraining을 더 수행한다고 하더라도 실제 downstream task에서 유의미한 성능 향상은 없었다.
Fair Comparison with BERT
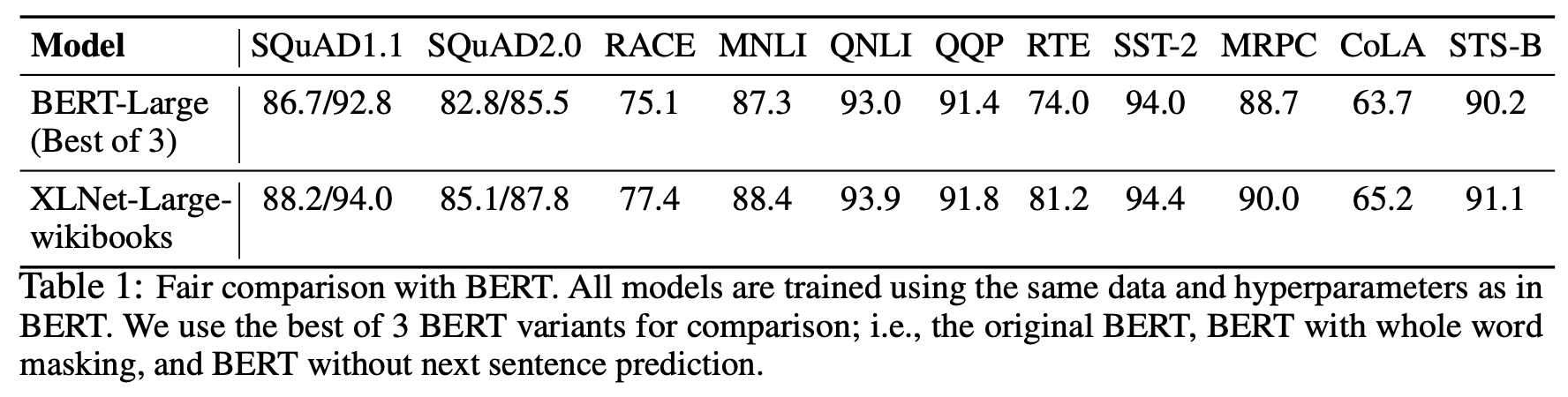
XLNet-Large는 모든 task에서 BERT-Large보다 좋은 성능을 보였다.
Comparison with RoBERTa: Scailing Up
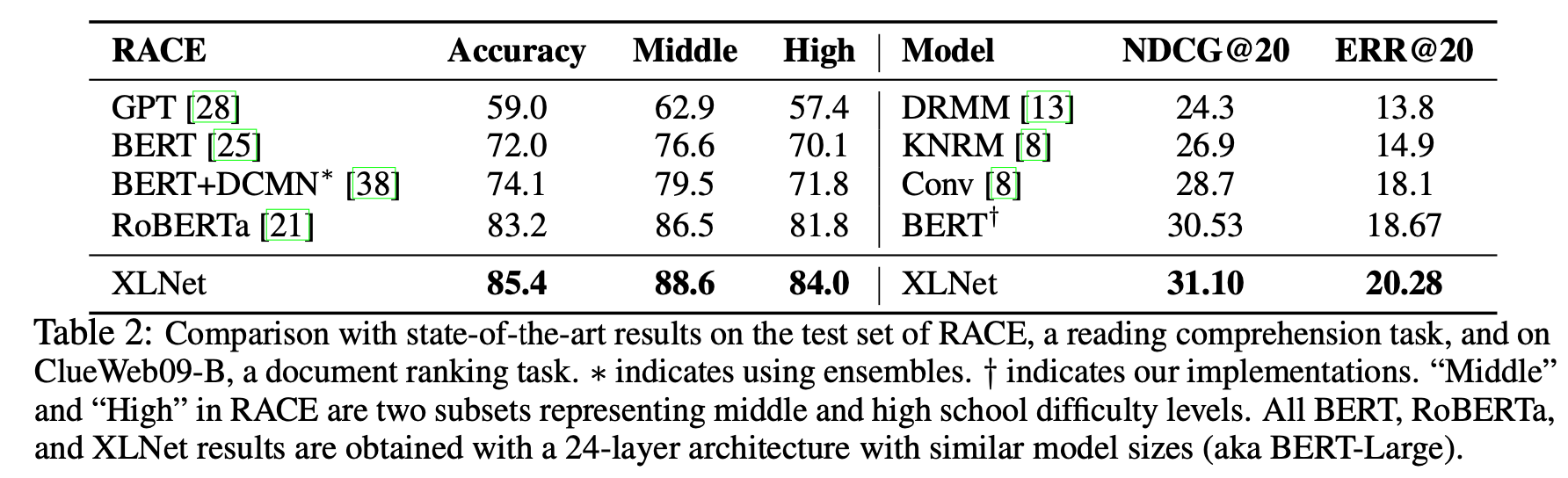
XLNet은 RACE task에서도 BERT, GPT, RoBERTa 등의 model들보다 좋은 성능을 보였다.
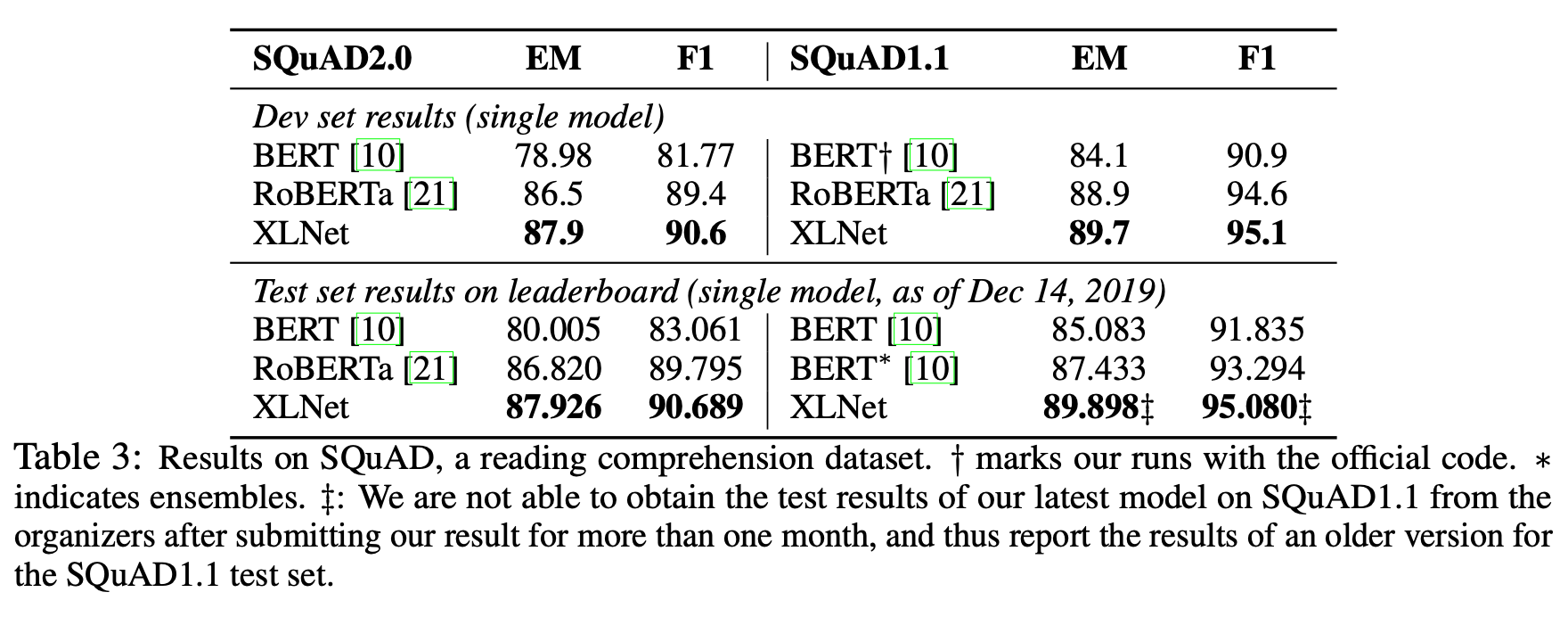
XLNet은 SQuAD2.0 task에서도 BERT, RoBERTa보다 좋은 성능을 보였다.
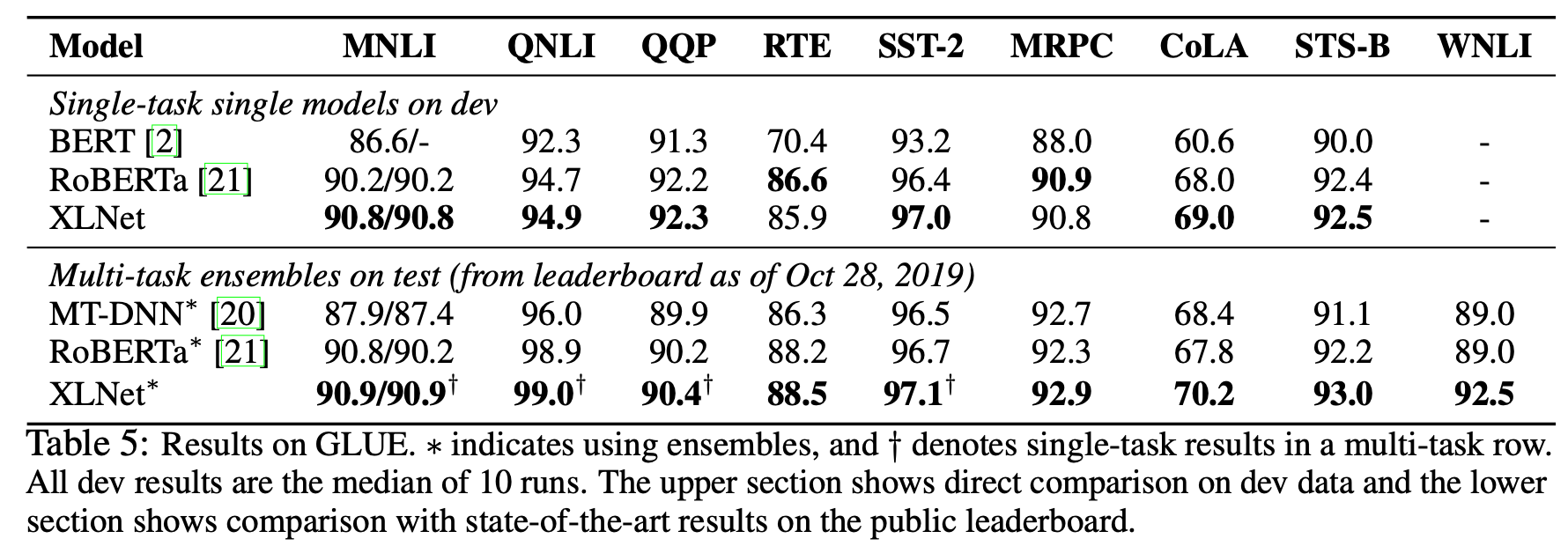
XLNet은 GLUE task에서도 BERT, RoBERTa보다 좋은 성능을 보였다.
Ablation Study
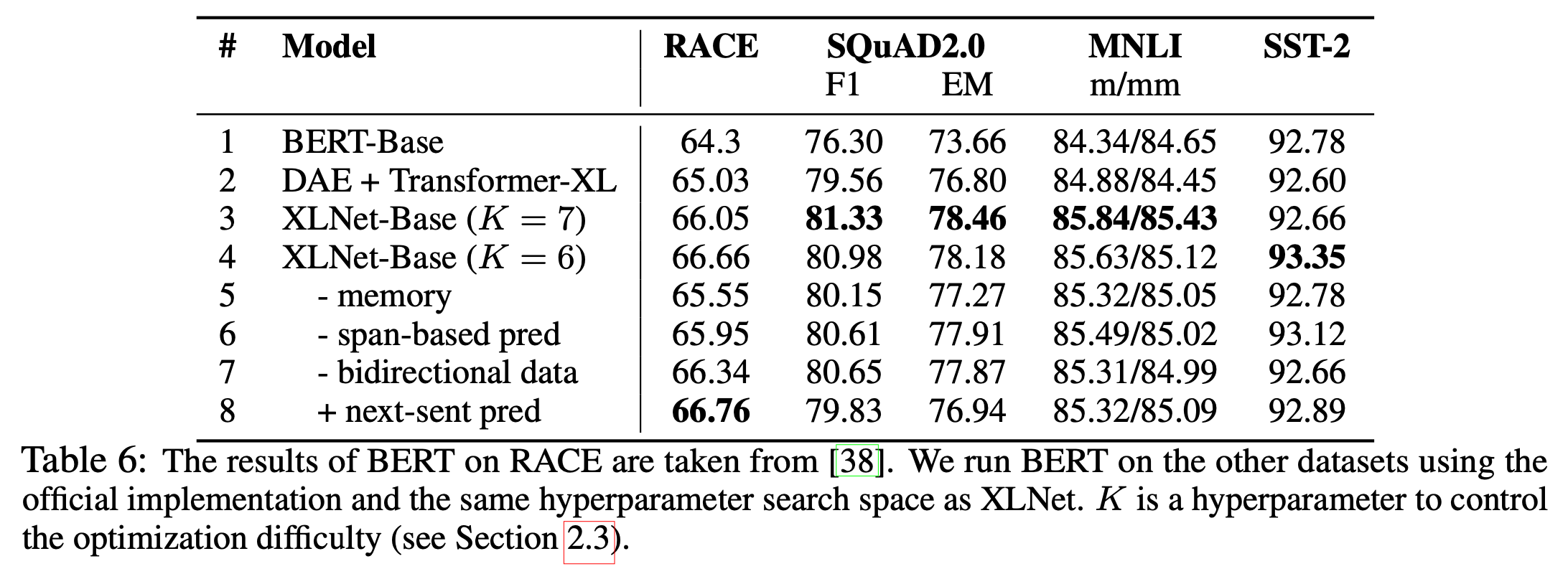
1~4를 살펴보면 XLNet-Base가 BERT나 Transformer-XL보다 좋은 성능을 보인다. 이를 통해 permutation language modeling objective가 효과적이었다는 것을 알 수 있다.
1~2를 살펴보면 Transformer-XL이 BERT보다 RACE와 SQuAD2.0 task에서 더 좋은 성능을 보인다. 이를 통해 Transformer-XL 계열의 model이 long sequence modeling에 효과적이라는 것을 알 수 있다.
4~5행을 살펴보면 memory caching mechanism이 빠진 경우 RACE나 SQuAD2.0과 같은 long sequence task에서 성능 저하가 있었다는 것을 알 수 있다.
4, 6~7행을 살펴보면 span-based prediction과 bidirectional data가 성능 향상에 기여했다는 것을 알 수 있다.
마지막으로 4, 8행을 통해 NSP가 RACE task를 제외한 모든 경우에서 오히려 성능을 하락시켰다는 것을 알 수 있다.
Conclusions
Permutation을 사용한 Autoregressive Pretraining 방식을 개척했다는 점에서 의의가 있다.